用戶與產品之間的相互可以看成是雙向線性的過程,手機上輸入字母“d”和界面輸出顯示是一次短交互,完成一次購物支付是長交互,這是使用一次產品過程中。用戶體驗考量的是用戶使用產品的全過程,這個過程包括了從安裝到放棄使用的時間軸,交互的良性循環的優秀用戶體驗的表現。
簡單以推薦引擎為例來說明各元素是如何在時間軸上發揮作用的:
初始化。基於群體特征和用戶的相關程度,將相似用戶喜好的其他物品推薦給用戶。在用戶對產品還沒有發生行為時,用戶填寫的個人信息(性別、年齡和收入等)可以作為初始化推薦。
內容推薦。單個用戶選擇某一物品,系統基於物品的元數據推薦相似的產品。這是用戶個體行為對數據的過濾,當用戶多次行為之後,系統可以大概估計對用戶的喜好。用戶的歷史行為會不斷影響後續推薦,形成用戶和系統之間的交互循環。
協同過濾。基於用戶行為發現物品的相關性。內容推薦是單個用戶對系統數據的過濾,而協同過濾是基於多個用戶行為的交叉結果,所以依賴於其他用戶行為數據量准確度。
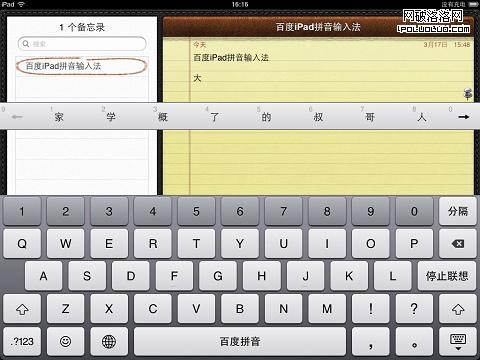
輸入法的字詞聯想也可以看出一個推薦引擎。當打入字母“da”,系統從詞庫挑選出“da”目錄下的漢字“大/達/打……”,“大”字上屏之後,系統聯想與“大”組詞概率比較大的字“家/學/概……”。這些聯想詞最早可能是從字典中篩選出來的,如用戶選擇了“概”字,“概”會被系統加權,下次對“大”聯想時更靠前顯示。用戶輸入詞組“dagai”,選擇“大概”上屏,也是對“概”字的加權。
如用戶輸入“daniu”,選擇了“大牛”上屏,而系統詞庫中沒有這個詞組,屬於用戶自造詞。如用戶分別輸入“da”和“niu”並上屏,系統智能分析“大”和“牛”有組詞的概率,有可能用戶下次輸入“大”字,系統會聯想到“牛”。
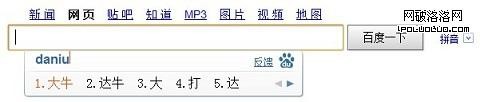
聯想的交互是單個用戶對系統詞庫的內容過濾,初始詞庫可以逐漸形成個性詞庫。如果是雲端輸入法,系統可以實時獲得所有用戶的輸入字詞,詞庫的更新頻率更快,滿足用戶個性詞庫的同時也能更新最新流行詞,這是多個用戶對詞庫的協調過濾。
用戶自造詞會降低部分詞匯的出現概率,系統甚至會從詞庫中刪除這些詞匯。從輸入法的例子中可以看出用戶行為是如何影響系統和其他用戶,歷史行為影響新的行為,實現不斷的交互循環。
純銀的“顯性內容決定論”可以理解為:優質用戶產生優質內容,優質內容吸引優質用戶,內容決定產品的魅力和氣場。從系統設計的觀點看,用戶行為可以看成系統數據的一部分,優秀用戶的行為和優質內容是同質化數據。它們之間的頻繁交互是優化內容數據的組織形式,再不斷向外擴展生成和吸收同質數據,版本迭代是滾雪球式的數據擴展。
如此看來,產品架構需要考慮是如何增加數據量、組織數據和數據擴展的良性循環。

切客的勳章
以手機LBS為例,增加數據量的方法簡單分為三種:用戶輸入、導入數據和商家發布信息。需求驅動用戶主動使用,LBS的勳章激勵機制是引導用戶行為,優惠券是刺激用戶需求。用戶的簽到行為如果無法加以利用的話,可以認為是不斷輸入垃圾信息。但簽到的位置、簽到商家的類型和頻繁程序都是可以加以分析,便於後期向用戶推薦有效信息和組織用戶之間的聯系。
每次循環都會影響到後續的產品質量,“小步快跑”的道理也在此,用戶對於產品的感受也是不斷增強,但也可能達到飽和。使用豆瓣電台選擇喜歡聽的音樂,累計聽歌近兩萬首時,電台猜中概率明顯降低。原因可能是:
- 已經遍歷各種音樂,難以發現新歌曲,個人輸入行為已經趨向於飽和。
- 沒有文藝范,不是目標用戶群,對音樂缺乏探索。
- 聽到不喜歡的音樂時,可能會連續點擊十次下一首,最後無奈關掉電台,對於用戶的隱性反饋缺乏理解。
以思維導圖式的方式理解產品會缺乏組織性,循環是產品架構的初級概念之一,以時間軸去安排產品設計的優先級。