記得很早以前看到過這樣的一段介紹:
想象你在逛街邊的一家書店,如果最終你沒有購買任何圖書就直接離開了,店長並不會知道你來過。但是如果你買了書,那麼書店的員工就會知道他們賣出了一些商品(當然如果你在那裡留了聯系信息來預訂另外一本書,他們就可以得到更多東西)。
回過頭來,我們從信息收集的角度看看網站訪問,那就是另外一個截然不同的世界了。無論你有沒有買東西,在你訪問站點時,總是會留下很多記錄,通過收集這些訪問者留下的大量數據,我們的網絡專家就可以得到關於網站用戶體驗的很多結論。
從站點的記錄中,可以知道你走過的每個通道、點擊的每個鏈接、拿了哪些商品、收藏了哪些你感興趣的話題等等。甚至知道你曾就搜索了哪些寶貝,網絡廣告推廣商就會根據這些你感興趣的商品,定向的給你投放一些“可能喜歡的寶貝”。
這就是最最簡單的web分析概念了,那麼我們進行web分析的最終動機又是什麼?
你的客戶需要什麼?他並不需要“可用性”和“用戶體驗”本身,他真正需要的是實現他的目標,達到他的訪問動機。
狹義地看,web分析是指分析網站訪客的行為;廣泛一點來說,web 分析是指評估、調整網站各個方面的運作,使其符合公司的商業目標。
換句話,web分析,最終動機並不是“報告”,也不是算計著如何向決策者們發送充滿數據的垃圾郵件。它的真正目的是獲得可行動的認識和度量。
Avinash Kaushik 在《Web Analytics: An Hour a Day》一書中,提到了單靠一些傳統的web分析,有時會帶來的YY般的數據報告,比如“退出最多的頁面”、“訪客屏幕分辨率”、“網站交互次數”等等,這些度量的一個共同點是,它們聲稱會說點什麼,但幾乎什麼也沒說明白。
可是反過來思考一下,基於日志數據的web分析真的就一無是處了麼?答案當然是否定的。日志分析,依舊是web 分析的基石,他給我們提供的是最廣泛的現象呈現,我們可以從中“知其然”。後面“知其所以然”的部分,就需要結合定性的分析研究來發現了。
那麼我們能從日志中得到哪些基礎數據呢?看看下面這個圖,縱向的把收集到的數據進行分析並劃分了幾個層次,這個圖也描述了一個目前很廣泛使用的基於日志的統計分析步驟:日志文件->PV->會話->使用者->客戶->忠實客戶,我們可以明顯地看出,金字塔越上層的數據就越具有商業價值。
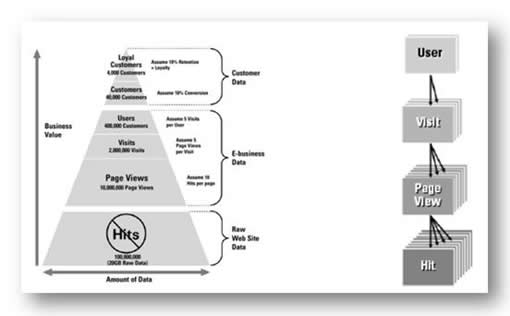
對圖中一些術語的解釋:
命中(Hit)和請求是同一術語。為了獲得服務器上的一個資源(可以是文本、圖像或任何可以被包含在頁面內的元素),浏覽器和它連接的服務器之間進行的一次單一連接。日志文件中一條記錄就是一個請求。
訪問數(Visit)和用戶會話是同一術語。從CNNIC對這個術語的定義看,沒有詳細定義什麼算是Visit,什麼算是Loss,目前,一個Visit必須至少完整下載一個頁面到客戶端,如果沒有完全下載就被用戶關閉窗口即結束請求,那麼是一個Loss,而不是一個Visit或稱Session。一般的度量方法:訪問者在20分鐘內與網站有交互活動則被認為是同一次進入網站,不記錄新的用戶會話數;當訪問者持續20分鐘與網站沒有交互活動,當他再次訪問網站時訪問者被認為再一次進入了網站,記錄新的用戶會話數。
Avinash 所提出的“三位一體”的web分析理論也正是將定性和定量合二為一的,以使客戶需求與公司目標達到雙贏為目的,得到可行動的認識和度量。
- 首先,進行行為分析,也就是我們傳統認為的點擊數據流分析,分析點擊密度、細分用戶等等。這一步的目的是收集真實的行為,來試圖推測用戶的意圖。從這些收集統計的數據中,我們並不企圖找出真正的意圖和問題,而是使其為更高層次的分析面提供參考。
- 第二點是通過結果分析,來找出“so what”的問題,在網站目標明確的前提下進行實際產出變化的分析,衡量這個web站點在滿足它的存在這一目標上做得如何,才能讓上一步的數據更加有意義。
- 第三部分是體驗分析,這是分析的關鍵,打破陳規去讓用戶告訴我們這些問題到底是“為什麼”,方法多是側重定性分析的,比如AB測試和多元測試、啟發式評估、客戶之聲等等。這樣也可以有效的避免將那些網站給用戶帶來的“誤會”當作有效樣本放入統計數據池中。
最後說幾個有意思的web分析方法:
1. 數據與可視化結合
“如果你有大量的數據,你應該感受到它們的存在。如果你必須浏覽十萬行日志文檔,當你浏覽到一百行時就已經忘了第一行。” —Marty
面對龐大的雜亂無章的日志數據,將其可視化,已經成為一種趨勢,我們十分高興的看到,一些主流的web分析網站都推出了很多可視化的東西,而且並不局限於日志數據。很多時候,換個角度,能得到不一樣的收獲。
來幾個典型的例子:
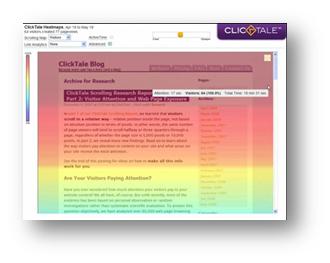
熱力圖:可以應用在點擊日志、眼動分析、頁面展現率等等很多定性、定量的分析上

收集頁面上點擊的位置,顏色越熱,表示點擊量越高
- 上一頁:以用戶為中心的設計思想不完全正確
- 下一頁:設計師和美工