近日在調測一個UTF8編碼的中文Zen Cart網站時遇到一件怪事,網頁顯示文字正常,用ie的察看源文件(記事本打開)卻發現亂碼,firefox沒有這個問題。經在網上多方查證和多次測試,解決了這個問題,其實是UTF-8文件的Unicode簽名BOM(Byte Order Mark)問題。
BOM(Byte Order Mark),是UTF編碼方案裡用於標識編碼的標准標記,在UTF-16裡本來是FF FE,變成UTF-8就成了EF BB BF。這個標記是可選的,因為UTF8字節沒有順序,所以它可以被用來檢測一個字節流是否是UTF-8編碼的。微軟做這種檢測,但有些軟件不做這種檢測,而把它當作正常字符處理。
微軟在自己的UTF-8格式的文本文件之前加上了EF BB BF三個字節, windows上面的notepad等程序就是根據這三個字節來確定一個文本文件是ASCII的還是UTF-8的, 然而這個只是微軟暗自作的標記, 其它平台上並沒有對UTF-8文本文件做個這樣的標記。
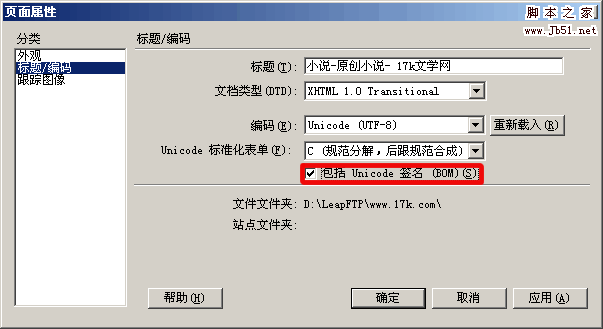
也就是說一個UTF-8文件可能有BOM,也可能沒有BOM,那麼怎麼區分呢?三種方法。1,用UltraEdit-32打開文件,切換到十六進制編輯模式,察看文件頭部是否有EF BB BF。2,用Dreamweaver打開,察看頁面屬性,看“包括Unicode簽名BOM”前面是否有個勾。3,用Windows的記事本打開,選擇 “另存為”,看文件的默認編碼是UTF-8還是ANSI,如果是ANSI則不帶BOM。
我找到Zen Cart的模版文件中的html_header.php,發現文件果然不帶BOM,用UltraEdit-32另存為的方式加上BOM後,再上傳html_header.php,一切正常。
注意用Convertz把gb2312文件轉換成UTF-8文件時,默認設置是不帶BOM的。不帶BOM可能出現上述亂碼問題,但是帶 BOM,對於php的include文件要小心,會在php字節流前面多出EF BB BF,提前輸出到顯示器有可能會帶來程序錯誤。一個解決方案是凡是被include的文件都保存為ANSI,主文件可以是UTF-8。要想把一個文件去掉 BOM,使用UlterEdit打開, 切換到十六進制編輯模式,把最前面三個字節(就是那該死的 EF BB BF)替換為20,保存(注意關閉保存時自動備份的功能),再切換到默認編輯模式,把最前面的三個空格去掉就可以了。
另外還學到一些編碼的小知識:所謂的unicode保存的文件實際上是utf-16,只不過恰好跟unicode的碼相同而已,但在概念上unicode與utf是兩回事,unicode是內存編碼表示方案,而utf是如何保存和傳輸unicode的方案。utf-16還分高位在前 (LE)和高位在後(BE)兩種。官方的utf編碼還有utf-32,也分LE和BE。非unicode官方的utf編碼還有utf-7,主要用於郵件傳輸。utf-8的單字節部分是和iso-8859-1兼容的,這主要是一些舊的系統和庫函數不能正確處理utf-16而被迫出來的,而且對英語字符來說,也節省保存的文件空間(以非英語字符浪費空間為代價)。在iso-8859-1的時候,utf8和iso-8859-1都是用一個字節表示的,當表示其它字符的時候,utf-8會使用兩個或三個字節。