深度理解語義化
編輯:HTML5教程
對於當前的 Web 而言,HTML 是聯系大多數 Web 資源的紐帶,也是內容的載體。在 Web 被剛剛設計出來的時候,Tim Berners-Lee 可能不會想到它現在會達到的規模以及深入到我們生活的那麼多方面。也許起初的想法很簡單:用來發布 Web 內容和資源的索引,方便人們查看。
但是隨著 Web 規模的不斷擴大,信息量之大已經不在人肉處理的范圍之內了。這個時候人們開始用機器來處理 Web 上發布的各種內容,搜索引擎就誕生了。再後來,人們又設計了各種智能程序來對索引好的內容作各種處理和挖掘。所以讓機器能夠更好地讀懂 Web 上發布的各種內容就變得越來越重要。
其實 HTML 在剛開始設計出來的時候就是帶有一定的「語義」的,包括段落、表格、圖片、標題等等,但這些更多地只是方便浏覽器等 UA 對它們作合適的處理。但逐漸地,機器也要借助 HTML 提供的語義以及自然語言處理的手段來「讀懂」它們從網上獲取的 HTML 文檔,但它們無法讀懂例如「紅色的文字」或者是深度嵌套的表格布局中內容的含義,因為太多已有的內容都是專門為了可視化的浏覽器設計的。面對這種情況,出現了兩種觀點:
我們可以讓機器的理解能力越來越接近人類,人能看懂、聽懂的東西,機器也能理解;
我們應該在發布內容的時候,就用機器可讀的、被廣泛認可的語義信息來描述內容,來降低機器處理 Web 內容的難度(HTML 本身就已經是朝這個方向邁出的一小步了)。
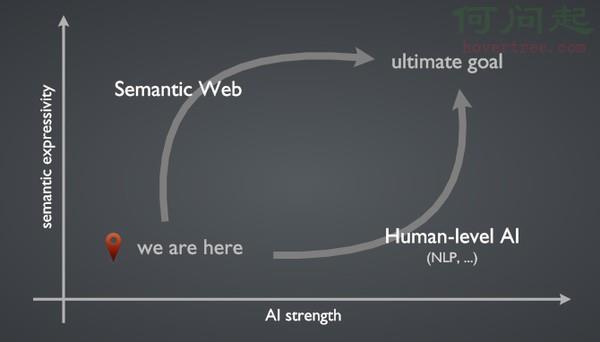
這個圖的意思是說,內容的語義表達能力和 AI 的智能程度決定了機器分析處理 Web 內容能力的高低。上面觀點 1 的方向是朝著人類水平的人工智能努力,而觀點 2 的方向正是萬維網創始人 Tim Berners-Lee 爵士提出的美好願景:語義網。語義網我就不多說了,簡單來說就是讓一切內容和包括對關系的描述都成為 Web 上的資源,都可以由唯一的 URI 定義,語義明確、機器可讀。顯然,兩條路都的終極目標都很遙遠,第一條路技術上難以實現,而第二條路實施起來障礙太多。
我認為我們當前能夠看得見摸得著的 Web 語義化,其實就是在往第二條路的方向上,邁出的一小步,即對已經有的被廣泛認可的 HTML 標准做改進。我們剛開始意識到,我們必須回歸內容本身,將內容本身的語義合理地表述出來,再為不同的用戶代理設計不同的樣式描述,也就是我們說的內容與樣式分離。這樣我們在提供內容的時候,首先要做的就是將內容本身進行合理的描述,暫時不用考慮它的最終呈現會是什麼樣子。
HTML 規范其實一直在往語義化的方向上努力,許多元素、屬性在設計的時候,就已經考慮了如何讓各種用戶代理甚至網絡爬蟲更好地理解 HTML 文檔。HTML5 更是在之前規范的基礎上,將所有表現層(presentational)的語義描述都進行了修改或者刪除,增加了不少可以表達更豐富語義的元素。為什麼這樣的語義元素是有意義的?因為它們被廣泛認可。所謂語義本身就是對符號的一種共識,被認可的程度越高、范圍越廣,人們就越可以依賴它實現各種各樣的功能。
- 上一頁:用HTML5的canvas繪制矩形和路徑
- 下一頁:HTML5語義化解說
小編推薦
熱門推薦