很多程序員在解決JVM性能問題的時候,花開了很多時間去調優應用程序級別的性能瓶頸,當你讀完這本系列文章之後你會發現我可能更加系統地看待這類的問題。我說過JVM的自身技術限制了Java企業級應用的伸縮性。首先我們先列舉一些主導因素。
l 主流的硬件服務器提供了大量的內存
l 分布式系統有大量內存的需求,而且該需求在持續增長
l 一個普通Java應用程序所持有的對空間大概在1GB~4GB,這遠遠低於一個硬件服務器的內存管理能力以及一個分布式應用程序的內存需求量。這被稱之為Java內存牆,如下圖所示(圖中表述Java應用服務器和常規Java應用的內存使用量的演變史)。
圖 1 Java內存牆(1980~2010)
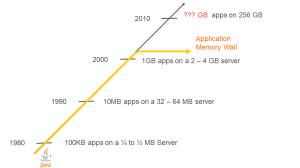
Java內存牆
這給我們帶來了如下JVM性能課題:
1) 如果分配給應用程序的內存太小,將導致內存不足。JVM 不能及時釋放內存空間給應用程序,最終將引發內存不足,或者JVM完全關閉。所以你必須提供更多的內存給應用程序。
2) 如果給對響應時間敏感的應用增加內存,如果不重啟你的系統或者優化你的應用,Java堆最終會碎片化。當碎片發生時,可能會導致應用中斷100毫秒~100秒,這取決與你的Java應用,Java堆的大小以及其他的JVM調優參數。
關於停頓的討論大部分都集中在平均停頓或者目標停頓,很少涉及到堆壓縮時的最壞停頓時間,在生產環境中堆中每千兆字節的有效數據的都將會發生大約1秒的停頓。
2~4秒的停頓對大多數企業應用來說都是不能接受的,所以盡管實際的Java應用實例可能需要更多的內存空間,但實際只分配2~4GB的內存。在一 些64位系統中帶有很多關於伸縮性的JVM調優項,使得這些系統可以運行16GB乃至20GB的堆空間,並能滿足典型響應時間的SLA。但是這些離現實較 遠,JVM目前的技術無法在進行堆壓縮時避免停頓應用程序。Java應用開發人員苦於處理這兩個為我們大多數人所抱怨的任務。
l 架構/建模在大量的實例池之上,隨之而來的是復雜的監控和管理操作。
l 反復的JVM和應用程序調優以避免“stop the world“引起的停頓。大多數程序員希望停頓不要發生在系統峰值負載期間。我稱之為不可能的目標。
現在讓我們深入一點Java的可伸縮性問題。
過度供給或過度實例化Java部署
為了充分利用內存資源,普通的做法是將Java應用部署在多個應用服務器實例上而不是一個或者少數應用服務器實例上。當一台Server上運行16 個應用服務器實例可以充分利用所有的內存資源,但如此無法解決的是多實例的監控以及管理所帶來的成本,尤其是當你的應用部署在多個Server上。
另一個問題來了,峰值負載時的內存資源不是每天都需要的,這樣就形成了巨大的浪費。有些情況下,一台物理機上可能只不是不超過3個“大應用服務器實例”,這樣的部署更加不夠經濟也不夠環保,尤其在非峰值負載期間。
讓我們來比較一下這兩種部署架構,下圖中左邊是多而小的應用服務器實例部署模式,右邊是少而大的應用服務器實例部署模式。兩種模式處理同樣的負載,究竟哪一種部署架構更具經濟性。
圖2 大應用服務器部署場景
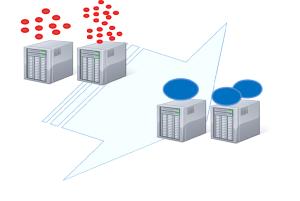
上圖源自:Azul Systems
如我之前說過的,並發壓縮使得大應用服務器部署模式變得可行,而且可以突破JVM可伸縮性的限制。目前只有Azul的Zing JVM可以提供並發壓縮的技術,另外Zing是Server側的JVM,我們很樂意看到越來越多的開發者在JVM層面去挑戰Java可伸縮性的問題。
由於性能調優仍然是我們解決Java可伸縮性問題的主要手段,我們先來看有哪些主要的調優參數以及通過它們能達到什麼樣的效果。
調優參數:一些事例
最著名的調優參數莫過於”-Xmx”了,通過該參數可以指定Java的堆空間大小,實際上可能不同的JVM執行結果不太一樣。
有的JVM包含了內部結構(如編譯器線程,垃圾回收器結構,代碼緩存等等)所需要的內存在“-Xmx”的設定中,而有的則不包含。因此用戶Java進程的大小不一定跟“-Xmx”的設定相吻合。
如果你的應用程序分配對象的速率,對象的生命周期,或者對象的大小超過了JVM內存相關配置,一旦達到最大可使用內存的阈值將會發生內存溢出,用戶進程則會停止。
當你的應用程序糾結於內存的可用性時,最有效的方法就是通過”-Xmx”指定更大的內存去重啟當前應用進程。為了避免頻繁的重啟,大多數企業生產環境都傾向於指定峰值負載時所需要的內存,造成過度配置優化。
提示:生產環境負載的調整
Java開發人員易犯的常見錯誤是在實驗下的做的堆內存設置,在移植到生產環境是忘記重新調整。生產環境和實驗室環境是不一樣的,謹記根據生產環境的負載重新調整堆內存設置。
分代垃圾回收器調優
還有一些其他的優化選項”-Xns”和”-XX: NewSize”,用來調整年輕代的大小,用來指定堆中專門負責新對象分配的空間大小。
大多數開發者都試圖基於實驗室環境調整年輕代的大小,這意味著在生產負載下存在失敗的風險。一般新生代的大小設置為堆大小的三分之一至二分之一左 右,但這不是一個准則,畢竟實際還要視應用程序邏輯而定。因此最好先調查清楚年輕代到年老代的蛻變率以及年老代對象的大小,在此基礎上(確保年老代的大 小,年老代過小會頻繁促發GC導致內存溢出錯誤)盡可能地調大年輕代的空間。
還有一個與年輕代相關的調優項”-XX:SurvivorRatio”,該選項用來指定年輕代中對象的生命周期,超過指定時長相關對象將被移至年老 代。為了”正確”地設定該值,你需要知道年輕代空間回收的頻率,能夠估算到新對象在應用程序進程中被引用的時長,同時也取決於分配率。
並發垃圾回收調優
針對對停頓敏感的應用,建議使用並發垃圾回收,雖然並行的辦法能夠帶來非常好的吞吐量基准測試分數,但是並行GC不利於縮短響應時間。並發 GC 是目前唯一有效的實現一致性和最少“stop the world”中斷的方法。不同的JVM提供不同的並發GC的設定,Oracle JVM(hotspot)提供”-XX:+UseConcMarkSweepGC”,今後G1將成為Oracle JVM默認的並發垃圾回收器。
性能調優並不是真正的解決辦法
或許你已經注意到上文中在討論如何“正確“地設定調優此參數時,我刻意在”正確“二字上加了雙引號。那是因為就我個人經驗而言一旦涉及到性能參數調 優,就沒有嚴格意義上的正確設定。每一個設定值都是針對特定的場景。考慮到應用場景會發生變化,JVM 性能調整充其量是一個權宜之計。
以堆的設置為例:如果2GB的堆可以應對20萬並發用戶,但是可能不能應付40萬的並發用戶。
我們再以”-XX:SurvivorRatio”為例:當設定符合一個負載持續增長最高至每毫秒10000個交易的場景,當壓力到達每毫秒50000個交易時又會發生什麼呢?
大多數企業級應用負載都是動態的,Java語言的動態內存管理以及動態編譯等技術使得Java更加適合企業級應用。我們來看看一下兩個配置清單。
清單1. 應用程序(1)的啟動選項
>java -Xmx12g -XX:MaxPermSize=64M -XX:PermSize=32M -XX:MaxNewSize=2g -XX:NewSize=1g -XX:SurvivorRatio=16 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=0 -XX:CMSInitiatingOccupancyFraction=60 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:ParallelGCThreads=12 -XX:LargePageSizeInBytes=256m …
清單 2. 應用程序(2)的啟動選項
>java –Xms8g –Xmx8g –Xmn2g -XX:PermSize=64M -XX:MaxPermSize=256M -XX:-OmitStackTraceInFastThrow -XX:SurvivorRatio=2 -XX:-UseAdaptiveSizePolicy -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:+CMSParallelRemarkEnabled -XX:+CMSParallelSurvivorRemarkEnabled -XX:CMSMaxAbortablePrecleanTime=10000 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=63 -XX:+UseParNewGC –Xnoclassgc …
兩者的配置區別很大,因為他們是兩個不同應用程序。感覺根據各自的應用特設都做了”正確“的配置與調優。在實驗室環境下都運行良好,但在生產環境中 最終會表現出疲態。清單1由於沒有考慮到動態負載,到了生產環境即表現不良。清單2沒有考慮到應用程序在生產環境中的特性變化。這兩種情況應該歸咎於開發 團隊,但是該歸咎於何處呢?
變通辦法可行嗎?
有些企業通過精確測量交易對象的大小定義極致的對象回收空間並”精簡“其架構來適配該空間。這也許是辦法來削減碎片以應對一整天的交易(在不做堆壓 縮的情況下)。還有一個辦法就是通過程序設計確保對象被引用的時間在一個比較短的時間內從而阻止其在SurvivorRatio時間之後不被遷往年老代而 直接被回收,避免內存壓縮的場景。這兩種辦法都可以,但是對應用開發人員和設計人員有一定的挑戰。
誰保障應用程序的性能?
一個門戶應用可能會在其活動負載峰值點出現故障;一個交易應用可能會在每次市場下跌和上升時無法正常運行;電子商務網站可能會無法應對節假日購物高 峰期。這些都是真實世界的案例基本都是JVM性能參數調優導致的。當產生了經濟損失,開發團隊就會受到責備。也許某些場合下開發團隊應該要受到責備,但是 JVM的提供商又應該負起什麼樣兒的責任呢?
首先JVM提供商應該要提供調優參數的優先順序,至少這在短期內還是很有意義的。有一些新的調優選項是針對特定的、 新興的企業應用程序場景。更多的調優選項是為了減輕JVM支持團隊的工作負荷而將性能優化轉嫁到應用開發者身上。但我個人認為這或將導致更加漫長的支持負 荷,一些針對最糟糕場景的調優選項也將被延期,當然不是無限延期。
毋庸置疑JVM的開發團隊也在努力地進行著他們的工作,同時也只有應用實施者才會更加清楚他們應用的特定需求。但是應用的實施者或開發者是無法預測 期動態的負載需求。在過去,JVM提供商也會去分析關於Java的性能與可擴展性問題,哪些是他們能夠解決的。不是提供調優參數,而是直接去優化或創新垃 圾回收的算法。更有趣是我們可以想象一下如果OpenJDK的社區聚集在一起重新考慮Java垃圾回收器將會發生什麼!
JVM性能的基准測試
調優參數有時被JVM提供商作為其競爭的工具,因為不同的調優可以改善他們的JVM在可預見的環境中的性能表現,本系列的最後一片文章中將調查這些基准測試來衡量JVM的性能。
JVM開發者的挑戰
真正的企業級可伸縮性需求是要求JVM能夠適應動態靈活的應用負載。這是在特定吞吐量和響應時間內保證持續穩定性能的關鍵。這是JVM開發者才能完成歷史使命,因此是時候號召我們Java開發者社區來迎接真正的Java可伸縮性的挑戰。
l 持續調優
對於給定的應用,在一開始需要告知其需要多大的內存,之後的工作都應該有JVM來負責 ,JVM需要適配動態的應用負載和運行場景。
l JVM實例數 vs. 實例的可擴展性
現在的服務器都支持很大的內存,那麼為什麼JVM實例不能有效地利用它呢?將應用拆分部署許多小的應用服務器實例上,這從經濟和環保角度都是一種浪費。現代的JVM需要跟上硬件和應用的發展潮流。
l 真實世界的性能和可伸縮性
企業不需要為其應用的性能需求去做極致的性能調優。JVM提供商和OpenJDK社區需要去解決Java可伸縮性的核心問題以及消除“stop the world“的操作。
結論
如果JVM做了這樣的工作,並且提供了並發壓縮的垃圾回收算法,JVM也不再成為Java可伸縮性的限制因素,Java應用開發者不需要花費痛苦的 時間理解怎樣配置JVM去獲得最佳性能,從而將會有更多的有趣的Java應用層面的創新,而不是無休止的JVM調優。我要挑戰JVM開發人員以及提供商所 需要做的事情來響應甲骨文所提倡的“Make the Java Future“的活動。
關於作者
Eva Andearsson對JVM技術、SOA、雲計算和其他企業級中間件解決方案有著10多年的從業經驗。在2001年,她以JRockit JVM開發者的身份加盟了創業公司Appeal Virtual Solutions(即BEA公司的前身)。在垃圾回收領域的研究和算法方面,EVA獲得了兩項專利。此外她還是提出了確定性垃圾回收 (Deterministic Garbage Collection),後來形成了JRockit實時系統(JRockit Real Time)。在技術上,Eva與SUN公司和Intel公司合作密切,涉及到很多將JRockit產品線、WebLogic和Coherence整合的項 目。2009年,Eva加盟了Azul System公,擔任產品經理。負責新的Zing Java平台的開發工作。最近,她改換門庭,以高級產品經理的身份加盟Cloudera公司,負責管理Cloudera公司Hadoop分布式系統,致力於高擴展性、分布式數據處理框架的開發。 很多程序員在解決JVM性能問題的時候,花開了很多時間去調優應用程序級別的性能瓶頸,當你讀完這本系列文章之後你會發現我可能更加系統地看待這類的問題。我說過JVM的自身技術限制了Java企業級應用的伸縮性。首先我們先列舉一些主導因素。
l 主流的硬件服務器提供了大量的內存
l 分布式系統有大量內存的需求,而且該需求在持續增長
l 一個普通Java應用程序所持有的對空間大概在1GB~4GB,這遠遠低於一個硬件服務器的內存管理能力以及一個分布式應用程序的內存需求量。這被稱之為Java內存牆,如下圖所示(圖中表述Java應用服務器和常規Java應用的內存使用量的演變史)。
圖 1 Java內存牆(1980~2010)
Java內存牆
這給我們帶來了如下JVM性能課題:
1) 如果分配給應用程序的內存太小,將導致內存不足。JVM 不能及時釋放內存空間給應用程序,最終將引發內存不足,或者JVM完全關閉。所以你必須提供更多的內存給應用程序。
2) 如果給對響應時間敏感的應用增加內存,如果不重啟你的系統或者優化你的應用,Java堆最終會碎片化。當碎片發生時,可能會導致應用中斷100毫秒~100秒,這取決與你的Java應用,Java堆的大小以及其他的JVM調優參數。
關於停頓的討論大部分都集中在平均停頓或者目標停頓,很少涉及到堆壓縮時的最壞停頓時間,在生產環境中堆中每千兆字節的有效數據的都將會發生大約1秒的停頓。
2~4秒的停頓對大多數企業應用來說都是不能接受的,所以盡管實際的Java應用實例可能需要更多的內存空間,但實際只分配2~4GB的內存。在一 些64位系統中帶有很多關於伸縮性的JVM調優項,使得這些系統可以運行16GB乃至20GB的堆空間,並能滿足典型響應時間的SLA。但是這些離現實較 遠,JVM目前的技術無法在進行堆壓縮時避免停頓應用程序。Java應用開發人員苦於處理這兩個為我們大多數人所抱怨的任務。
l 架構/建模在大量的實例池之上,隨之而來的是復雜的監控和管理操作。
l 反復的JVM和應用程序調優以避免“stop the world“引起的停頓。大多數程序員希望停頓不要發生在系統峰值負載期間。我稱之為不可能的目標。
現在讓我們深入一點Java的可伸縮性問題。
過度供給或過度實例化Java部署
為了充分利用內存資源,普通的做法是將Java應用部署在多個應用服務器實例上而不是一個或者少數應用服務器實例上。當一台Server上運行16 個應用服務器實例可以充分利用所有的內存資源,但如此無法解決的是多實例的監控以及管理所帶來的成本,尤其是當你的應用部署在多個Server上。
另一個問題來了,峰值負載時的內存資源不是每天都需要的,這樣就形成了巨大的浪費。有些情況下,一台物理機上可能只不是不超過3個“大應用服務器實例”,這樣的部署更加不夠經濟也不夠環保,尤其在非峰值負載期間。
讓我們來比較一下這兩種部署架構,下圖中左邊是多而小的應用服務器實例部署模式,右邊是少而大的應用服務器實例部署模式。兩種模式處理同樣的負載,究竟哪一種部署架構更具經濟性。
圖2 大應用服務器部署場景
上圖源自:Azul Systems
如我之前說過的,並發壓縮使得大應用服務器部署模式變得可行,而且可以突破JVM可伸縮性的限制。目前只有Azul的Zing JVM可以提供並發壓縮的技術,另外Zing是Server側的JVM,我們很樂意看到越來越多的開發者在JVM層面去挑戰Java可伸縮性的問題。
由於性能調優仍然是我們解決Java可伸縮性問題的主要手段,我們先來看有哪些主要的調優參數以及通過它們能達到什麼樣的效果。
調優參數:一些事例
最著名的調優參數莫過於”-Xmx”了,通過該參數可以指定Java的堆空間大小,實際上可能不同的JVM執行結果不太一樣。
有的JVM包含了內部結構(如編譯器線程,垃圾回收器結構,代碼緩存等等)所需要的內存在“-Xmx”的設定中,而有的則不包含。因此用戶Java進程的大小不一定跟“-Xmx”的設定相吻合。
如果你的應用程序分配對象的速率,對象的生命周期,或者對象的大小超過了JVM內存相關配置,一旦達到最大可使用內存的阈值將會發生內存溢出,用戶進程則會停止。
當你的應用程序糾結於內存的可用性時,最有效的方法就是通過”-Xmx”指定更大的內存去重啟當前應用進程。為了避免頻繁的重啟,大多數企業生產環境都傾向於指定峰值負載時所需要的內存,造成過度配置優化。
提示:生產環境負載的調整
Java開發人員易犯的常見錯誤是在實驗下的做的堆內存設置,在移植到生產環境是忘記重新調整。生產環境和實驗室環境是不一樣的,謹記根據生產環境的負載重新調整堆內存設置。
分代垃圾回收器調優
還有一些其他的優化選項”-Xns”和”-XX: NewSize”,用來調整年輕代的大小,用來指定堆中專門負責新對象分配的空間大小。
大多數開發者都試圖基於實驗室環境調整年輕代的大小,這意味著在生產負載下存在失敗的風險。一般新生代的大小設置為堆大小的三分之一至二分之一左 右,但這不是一個准則,畢竟實際還要視應用程序邏輯而定。因此最好先調查清楚年輕代到年老代的蛻變率以及年老代對象的大小,在此基礎上(確保年老代的大 小,年老代過小會頻繁促發GC導致內存溢出錯誤)盡可能地調大年輕代的空間。
還有一個與年輕代相關的調優項”-XX:SurvivorRatio”,該選項用來指定年輕代中對象的生命周期,超過指定時長相關對象將被移至年老 代。為了”正確”地設定該值,你需要知道年輕代空間回收的頻率,能夠估算到新對象在應用程序進程中被引用的時長,同時也取決於分配率。
並發垃圾回收調優
針對對停頓敏感的應用,建議使用並發垃圾回收,雖然並行的辦法能夠帶來非常好的吞吐量基准測試分數,但是並行GC不利於縮短響應時間。並發 GC 是目前唯一有效的實現一致性和最少“stop the world”中斷的方法。不同的JVM提供不同的並發GC的設定,Oracle JVM(hotspot)提供”-XX:+UseConcMarkSweepGC”,今後G1將成為Oracle JVM默認的並發垃圾回收器。
性能調優並不是真正的解決辦法
或許你已經注意到上文中在討論如何“正確“地設定調優此參數時,我刻意在”正確“二字上加了雙引號。那是因為就我個人經驗而言一旦涉及到性能參數調 優,就沒有嚴格意義上的正確設定。每一個設定值都是針對特定的場景。考慮到應用場景會發生變化,JVM 性能調整充其量是一個權宜之計。
以堆的設置為例:如果2GB的堆可以應對20萬並發用戶,但是可能不能應付40萬的並發用戶。
我們再以”-XX:SurvivorRatio”為例:當設定符合一個負載持續增長最高至每毫秒10000個交易的場景,當壓力到達每毫秒50000個交易時又會發生什麼呢?
大多數企業級應用負載都是動態的,Java語言的動態內存管理以及動態編譯等技術使得Java更加適合企業級應用。我們來看看一下兩個配置清單。
清單1. 應用程序(1)的啟動選項
>java -Xmx12g -XX:MaxPermSize=64M -XX:PermSize=32M -XX:MaxNewSize=2g -XX:NewSize=1g -XX:SurvivorRatio=16 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=0 -XX:CMSInitiatingOccupancyFraction=60 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:ParallelGCThreads=12 -XX:LargePageSizeInBytes=256m …
清單 2. 應用程序(2)的啟動選項
>java –Xms8g –Xmx8g –Xmn2g -XX:PermSize=64M -XX:MaxPermSize=256M -XX:-OmitStackTraceInFastThrow -XX:SurvivorRatio=2 -XX:-UseAdaptiveSizePolicy -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:+CMSParallelRemarkEnabled -XX:+CMSParallelSurvivorRemarkEnabled -XX:CMSMaxAbortablePrecleanTime=10000 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=63 -XX:+UseParNewGC –Xnoclassgc …
兩者的配置區別很大,因為他們是兩個不同應用程序。感覺根據各自的應用特設都做了”正確“的配置與調優。在實驗室環境下都運行良好,但在生產環境中 最終會表現出疲態。清單1由於沒有考慮到動態負載,到了生產環境即表現不良。清單2沒有考慮到應用程序在生產環境中的特性變化。這兩種情況應該歸咎於開發 團隊,但是該歸咎於何處呢?
變通辦法可行嗎?
有些企業通過精確測量交易對象的大小定義極致的對象回收空間並”精簡“其架構來適配該空間。這也許是辦法來削減碎片以應對一整天的交易(在不做堆壓 縮的情況下)。還有一個辦法就是通過程序設計確保對象被引用的時間在一個比較短的時間內從而阻止其在SurvivorRatio時間之後不被遷往年老代而 直接被回收,避免內存壓縮的場景。這兩種辦法都可以,但是對應用開發人員和設計人員有一定的挑戰。
誰保障應用程序的性能?
一個門戶應用可能會在其活動負載峰值點出現故障;一個交易應用可能會在每次市場下跌和上升時無法正常運行;電子商務網站可能會無法應對節假日購物高 峰期。這些都是真實世界的案例基本都是JVM性能參數調優導致的。當產生了經濟損失,開發團隊就會受到責備。也許某些場合下開發團隊應該要受到責備,但是 JVM的提供商又應該負起什麼樣兒的責任呢?
首先JVM提供商應該要提供調優參數的優先順序,至少這在短期內還是很有意義的。有一些新的調優選項是針對特定的、 新興的企業應用程序場景。更多的調優選項是為了減輕JVM支持團隊的工作負荷而將性能優化轉嫁到應用開發者身上。但我個人認為這或將導致更加漫長的支持負 荷,一些針對最糟糕場景的調優選項也將被延期,當然不是無限延期。
毋庸置疑JVM的開發團隊也在努力地進行著他們的工作,同時也只有應用實施者才會更加清楚他們應用的特定需求。但是應用的實施者或開發者是無法預測 期動態的負載需求。在過去,JVM提供商也會去分析關於Java的性能與可擴展性問題,哪些是他們能夠解決的。不是提供調優參數,而是直接去優化或創新垃 圾回收的算法。更有趣是我們可以想象一下如果OpenJDK的社區聚集在一起重新考慮Java垃圾回收器將會發生什麼!
JVM性能的基准測試
調優參數有時被JVM提供商作為其競爭的工具,因為不同的調優可以改善他們的JVM在可預見的環境中的性能表現,本系列的最後一片文章中將調查這些基准測試來衡量JVM的性能。
JVM開發者的挑戰
真正的企業級可伸縮性需求是要求JVM能夠適應動態靈活的應用負載。這是在特定吞吐量和響應時間內保證持續穩定性能的關鍵。這是JVM開發者才能完成歷史使命,因此是時候號召我們Java開發者社區來迎接真正的Java可伸縮性的挑戰。
l 持續調優
對於給定的應用,在一開始需要告知其需要多大的內存,之後的工作都應該有JVM來負責 ,JVM需要適配動態的應用負載和運行場景。
l JVM實例數 vs. 實例的可擴展性
現在的服務器都支持很大的內存,那麼為什麼JVM實例不能有效地利用它呢?將應用拆分部署許多小的應用服務器實例上,這從經濟和環保角度都是一種浪費。現代的JVM需要跟上硬件和應用的發展潮流。
l 真實世界的性能和可伸縮性
企業不需要為其應用的性能需求去做極致的性能調優。JVM提供商和OpenJDK社區需要去解決Java可伸縮性的核心問題以及消除“stop the world“的操作。
結論
如果JVM做了這樣的工作,並且提供了並發壓縮的垃圾回收算法,JVM也不再成為Java可伸縮性的限制因素,Java應用開發者不需要花費痛苦的 時間理解怎樣配置JVM去獲得最佳性能,從而將會有更多的有趣的Java應用層面的創新,而不是無休止的JVM調優。我要挑戰JVM開發人員以及提供商所 需要做的事情來響應甲骨文所提倡的“Make the Java Future“的活動。
關於作者
Eva Andearsson對JVM技術、SOA、雲計算和其他企業級中間件解決方案有著10多年的從業經驗。在2001年,她以JRockit JVM開發者的身份加盟了創業公司Appeal Virtual Solutions(即BEA公司的前身)。在垃圾回收領域的研究和算法方面,EVA獲得了兩項專利。此外她還是提出了確定性垃圾回收 (Deterministic Garbage Collection),後來形成了JRockit實時系統(JRockit Real Time)。在技術上,Eva與SUN公司和Intel公司合作密切,涉及到很多將JRockit產品線、WebLogic和Coherence整合的項 目。2009年,Eva加盟了Azul System公,擔任產品經理。負責新的Zing Java平台的開發工作。最近,她改換門庭,以高級產品經理的身份加盟Cloudera公司,負責管理Cloudera公司Hadoop分布式系統,致力於高擴展性、分布式數據處理框架的開發。