七、AJax開發
到這裡,已經可以清楚的知道AJAX是什麼,AJAX能做什麼,AJAX什麼地方不好。如果你覺得AJAX真的能給你的開發工作帶來改進的話,那麼繼續看看怎麼使用AJax吧。
AJax涉及到的7項技術中,個人認為Javascript、XMLHttpRequest、DOM、XML比較有用。
A、XMLHttpRequest對象
XMLHttpRequest是XMLHTTP組件的對象,通過這個對象,AJax可以像桌面應用程序一樣只同服務器進行數據層面的交換,而不用每次都刷新界面,也不用每次將數據處理的工作都交給服務器來做;這樣既減輕了服務器負擔又加快了響應速度、縮短了用戶等待的時間。
IE5.0開始,開發人員可以在Web頁面內部使用XMLHTTP ActiveX組件擴展自身的功能,不用從當前的Web頁面導航就可以直接傳輸數據到服務器或者從服務器接收數據。,Mozilla1.0以及NetScape7則是創建繼承XML的代理類XMLHttpRequest;對於大多數情況,XMLHttpRequest對象和XMLHTTP組件很相似,方法和屬性類似,只是部分屬性不同。
XMLHttpRequest對象初始化:<script language=”Javascript”>var http_request = false;//IE浏覽器http_request = new ActiveXObject("Msxml2.XMLHTTP");http_request = new ActiveXObject("Microsoft.XMLHTTP");//Mozilla浏覽器http_request = new XMLHttpRequest();</script>
XMLHttpRequest對象的方法:
方法 描述 abort()停止當前請求
getAllResponseHeaders()作為字符串返回完整的headers
getResponseHeader("headerLabel")作為字符串返回單個的header標簽
open("method","URL"[,asyncFlag[,"userName"[, "passWord"]]]) 設置未決的請求的目標 URL,方法,和其他參數 send(content) 發送請求 setRequestHeader("label", "value") 設置header並和請求一起發送XMLHttpRequest對象的屬性:
屬性 描述 onreadystatechange 狀態改變的事件觸發器 readyState 對象狀態(integer):0 = 未初始化
1 = 讀取中
2 = 已讀取
3 = 交互中
4 = 完成 responseText 服務器進程返回數據的文本版本 responseXML 服務器進程返回數據的兼容DOM的XML文檔對象 status 服務器返回的狀態碼, 如:404 = "文件未找到" 、200 ="成功" statusText 服務器返回的狀態文本信息
B、Javascript
Javascript一直被定位為客戶端的腳本語言,應用最多的地方是表單數據的校驗。現在,可以通過Javascript操作XMLHttpRequest,來跟數據庫打交道。
C、DOM
DOM(Document Object Model)是提供給Html和XML使用的一組API,提供了文件的表述結構,並可以利用它改變其中的內容和可見物。腳本語言通過DOM才可以跟頁面進行交互。web開發人員可操作及建立文件的屬性、方法以及事件都以對象來展現。比如,document就代表頁面對象本身。
D、XML
通過XML(Extensible Markup Language),可以規范的定義結構化數據,是網上傳輸的數據和文檔符合統一的標准。用XML表述的數據和文檔,可以很容易的讓所有程序共享。
7.2、AJax開發框架
這裡,我們通過一步步的解析,來形成一個發送和接收XMLHttpRequest請求的程序框架。AJax實質上也是遵循Request/Server模式,所以這個框架基本的流程也是:對象初始化à發送請求à服務器接收à服務器返回à客戶端接收à修改客戶端頁面內容。只不過這個過程是異步的。
A、初始化對象並發出XMLHttpRequest請求
為了讓Javascript可以向服務器發送HTTP請求,必須使用XMLHttpRequest對象。使用之前,要先將XMLHttpRequest對象實例化。之前說過,各個浏覽器對這個實例化過程實現不同。IE以ActiveX控件的形式提供,而Mozilla等浏覽器則直接以XMLHttpRequest類的形式提供。為了讓編寫的程序能夠跨浏覽器運行,要這樣寫:
if (window.XMLHttpRequest) { // Mozilla, Safari, ... http_request = new XMLHttpRequest(); } else if (window.ActiveXObject) { // IE http_request = new ActiveXObject("Microsoft.XMLHTTP");}
有些版本的Mozilla浏覽器處理服務器返回的未包含XML mime-type頭部信息的內容時會出錯。因此,要確保返回的內容包含text/XML信息。
http_request = new XMLHttpRequest();http_request.overrideMimeType('text/XML');B、指定響應處理函數接下來要指定當服務器返回信息時客戶端的處理方式。只要將相應的處理函數名稱賦給XMLHttpRequest對象的onreadystatechange屬性就可以了。比如:
http_request.onreadystatechange = processRequest;
需要指出的時,這個函數名稱不加括號,不指定參數。也可以用Javascript即時定義函數的方式定義響應函數。比如:
http_request.onreadystatechange = function() { };
C、發出HTTP請求指定響應處理函數之後,就可以向服務器發出HTTP請求了。這一步調用XMLHttpRequest對象的open和send方法。
http_request.open('GET', 'http://www.example.org/some.file', true);http_request.send(null);
open的第一個參數是HTTP請求的方法,為Get、Post或者Head。
open的第二個參數是目標URL。基於安全考慮,這個URL只能是同網域的,否則會提示“沒有權限”的錯誤。這個URL可以是任何的URL,包括需要服務器解釋執行的頁面,不僅僅是靜態頁面。目標URL處理請求XMLHttpRequest請求則跟處理普通的HTTP請求一樣,比如JSP可以用request.getParameter(“”)或者request.getAttribute(“”)來取得URL參數值。
open的第三個參數只是指定在等待服務器返回信息的時間內是否繼續執行下面的代碼。如果為True,則不會繼續執行,直到服務器返回信息。默認為True。
按照順序,open調用完畢之後要調用send方法。send的參數如果是以Post方式發出的話,可以是任何想傳給服務器的內容。不過,跟form一樣,如果要傳文件或者Post內容給服務器,必須先調用setRequestHeader方法,修改MIME類別。如下:
http_request.setRequestHeader(“Content-Type”,”application/x-www-form-urlencoded”);
這時資料則以查詢字符串的形式列出,作為sned的參數,例如:
name=value&anothername=othervalue&so=onD、處理服務器返回的信息
在第二步我們已經指定了響應處理函數,這一步,來看看這個響應處理函數都應該做什麼。
首先,它要檢查XMLHttpRequest對象的readyState值,判斷請求目前的狀態。參照前文的屬性表可以知道,readyState值為4的時候,代表服務器已經傳回所有的信息,可以開始處理信息並更新頁面內容了。如下:
if (http_request.readyState == 4) { // 信息已經返回,可以開始處理} else { // 信息還沒有返回,等待}
服務器返回信息後,還需要判斷返回的HTTP狀態碼,確定返回的頁面沒有錯誤。所有的狀態碼都可以在W3C的官方網站上查到。其中,200代表頁面正常。
if (http_request.status == 200) { // 頁面正常,可以開始處理信息} else { // 頁面有問題}
XMLHttpRequest對成功返回的信息有兩種處理方式:
responseText:將傳回的信息當字符串使用;
responseXML:將傳回的信息當XML文檔使用,可以用DOM處理。
總結上面的步驟,我們整理出一個初步的可用的開發框架,供以後調用;這裡,將服務器返回的信息用window.alert以字符串的形式顯示出來:
<script language="Javascript">var http_request = false;function send_request(url) {//初始化、指定處理函數、發送請求的函數http_request = false;//開始初始化XMLHttpRequest對象if(window.XMLHttpRequest) { //Mozilla 浏覽器http_request = new XMLHttpRequest();if (http_request.overrideMimeType) {//設置MiME類別http_request.overrideMimeType("text/xml");}}else if (window.ActiveXObject) { // IE浏覽器try {http_request = new ActiveXObject("Msxml2.XMLHTTP");} catch (e) {try {http_request = new ActiveXObject("Microsoft.XMLHTTP");} catch (e) {}}}if (!http_request) { // 異常,創建對象實例失敗window.alert("不能創建XMLHttpRequest對象實例.");return false;}http_request.onreadystatechange = processRequest;// 確定發送請求的方式和URL以及是否同步執行下段代碼http_request.open("GET", url, true);http_request.send(null);}// 處理返回信息的函數 function processRequest() { if (http_request.readyState == 4) { // 判斷對象狀態 if (http_request.status == 200) { // 信息已經成功返回,開始處理信息 alert(http_request.responseText); } else { //頁面不正常 alert("您所請求的頁面有異常。"); } } }</script>7.3、簡單的示例接下來,我們利用上面的開發框架來做兩個簡單的應用。
A、數據校驗
在用戶注冊的表單中,經常碰到要檢驗待注冊的用戶名是否唯一。傳統的做法是采用window.open的彈出窗口,或者window. showModalDialog的對話框。不過,這兩個都需要打開窗口。采用AJax後,采用異步方式直接將參數提交到服務器,用window.alert將服務器返回的校驗信息顯示出來。代碼如下:
在<body></body>之間增加一段form表單代碼:
<form name="form1" action="" method="post">
用戶名:<input type="text" name="username" value="">
<input type="button" name="check" value="唯一性檢查" >
<input type="submit" name="submit" value="提交">
</form>
在開發框架的基礎上再增加一個調用函數:
function userCheck() {var f = document.form1;var username = f.username.value;if(username=="") {window.alert("用戶名不能為空。");f.username.focus();return false;}else {send_request('sample1_2.JSP?username='+username);}}
看看sample1_2.JSP做了什麼:
<%@ page contentType="text/Html; charset=gb2312" errorPage="" %><%String username = request.getParameter("username");if("educhina".equals(username)) out.print("用戶名已經被注冊,請更換一個用戶名。");else out.print("用戶名尚未被使用,您可以繼續。");%>
運行一下,嗯,沒有彈出窗口,沒有頁面刷新,跟預想的效果一樣。如果需要的話,可以在sample1_2.JSP中實現更復雜的功能。最後,只要將反饋信息打印出來就可以了。


我們在第五部分提到利用AJax改進級聯菜單的設計。接下來,我們就演示一下如何“按需取數據”。
首先,在<body></body>中間增加如下Html代碼:
<table width="200" border="0" cellspacing="0" cellpadding="0"> <tr> <td height="20"><a href="Javascript:void(0)" >經理室</a></td> </tr> <tr style="display:none"> <td height="20" id="pos_1"> </td> </tr> <tr> <td height="20"><a href="Javascript:void(0)" >開發部</a></td> </tr> <tr style="display:none "> <td id="pos_2" height="20"> </td> </tr></table>
在框架的基礎上增加一個響應函數showRoles(obj):
//顯示部門下的崗位function showRoles(obj) {document.getElementById(obj).parentNode.style.display = "";document.getElementById(obj).innerHtml = "正在讀取數據..."currentPos = obj;send_request("sample2_2.JSP?playPos="+obj);}
修改框架的processRequest函數:
// 處理返回信息的函數function processRequest() { if (http_request.readyState == 4) { // 判斷對象狀態 if (http_request.status == 200) { // 信息已經成功返回,開始處理信息document.getElementById(currentPos).innerHtml = http_request.responseText; } else { //頁面不正常 alert("您所請求的頁面有異常。"); } }}
最後就是smaple2_2.JSP了:
<%@ page contentType="text/Html; charset=gb2312" errorPage="" %>
<%
String playPos = request.getParameter("playPos");if("pos_1".equals(playPos)) out.print(" 總經理<br> 副總經理");else if("pos_2".equals(playPos)) out.println(" 總工程師<br> 軟件工程師");
%>
運行一下看看效果:


文檔對象模型(DOM)是表示文檔(比如Html和XML)和訪問、操作構成文檔的各種元素的應用程序接口(API)。一般的,支持Javascript的所有浏覽器都支持DOM。本文所涉及的DOM,是指W3C定義的標准的文檔對象模型,它以樹形結構表示Html和XML文檔,定義了遍歷這個樹和檢查、修改樹的節點的方法和屬性。
7.4.1、DOM眼中的Html文檔:樹
在DOM眼中,HTML跟XML一樣是一種樹形結構的文檔,<html>是根(root)節點,<head>、<title>、<body>是<Html>的子(children)節點,互相之間是兄弟(sibling)節點;<body>下面才是子節點<table>、<span>、<p>等等。如下圖:
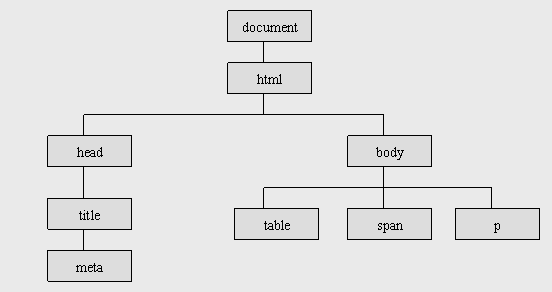
這個是不是跟XML的結構有點相似呢。不同的是,Html文檔的樹形主要包含表示元素、標記的節點和表示文本串的節點。
7.4.2、Html文檔的節點DOM下,HTML文檔各個節點被視為各種類型的Node對象。每個Node對象都有自己的屬性和方法,利用這些屬性和方法可以遍歷整個文檔樹。由於Html文檔的復雜性,DOM定義了nodeType來表示節點的類型。這裡列出Node常用的幾種節點類型: 接口 nodeType常量 nodeType值 備注 Element Node.ELEMENT_NODE 1 元素節點 Text Node.TEXT_NODE 3 文本節點 Document Node.DOCUMENT_NODE 9 document Comment Node.COMMENT_NODE 8 注釋的文本 DocumentFragment Node.DOCUMENT_FRAGMENT_NODE 11 document片斷 Attr Node.ATTRIBUTE_NODE 2 節點屬性
DOM樹的根節點是個Document對象,該對象的documentElement屬性引用表示文檔根元素的Element對象(對於HTML文檔,這個就是<html>標記)。Javascript操作Html文檔的時候,document即指向整個文檔,<body>、<table>等節點類型即為Element。Comment類型的節點則是指文檔的注釋。具體節點類型的含義,請參考《Javascript權威指南》,在此不贅述。
Document定義的方法大多數是生產型方法,主要用於創建可以插入文檔中的各種類型的節點。常用的Document方法有:
方法 描述 createAttribute() 用指定的名字創建新的Attr節點。 createComment() 用指定的字符串創建新的Comment節點。 createElement() 用指定的標記名創建新的Element節點。 createTextNode() 用指定的文本創建新的TextNode節點。 getElementById() 返回文檔中具有指定id屬性的Element節點。 getElementsByTagName() 返回文檔中具有指定標記名的所有Element節點。對於Element節點,可以通過調用getAttribute()、setAttribute()、removeAttribute()方法來查詢、設置或者刪除一個Element節點的性質,比如<table>標記的border屬性。下面列出Element常用的屬性:
屬性 描述 tagName 元素的標記名稱,比如<p>元素為P。Html文檔返回的tabName均為大寫。Element常用的方法:
方法 描述 getAttribute() 以字符串形式返回指定屬性的值。 getAttributeNode() 以Attr節點的形式返回指定屬性的值。 getElementsByTabName() 返回一個Node數組,包含具有指定標記名的所有Element節點的子孫節點,其順序為在文檔中出現的順序。 hasAttribute() 如果該元素具有指定名字的屬性,則返回true。 removeAttribute() 從元素中刪除指定的屬性。 removeAttributeNode() 從元素的屬性列表中刪除指定的Attr節點。 setAttribute() 把指定的屬性設置為指定的字符串值,如果該屬性不存在則添加一個新屬性。 setAttributeNode() 把指定的Attr節點添加到該元素的屬性列表中。Attr對象代表文檔元素的屬性,有name、value等屬性,可以通過Node接口的attributes屬性或者調用Element接口的getAttributeNode()方法來獲取。不過,在大多數情況下,使用Element元素屬性的最簡單方法是getAttribute()和setAttribute()兩個方法,而不是Attr對象。
7.4.3、使用DOM操作Html文檔Node對象定義了一系列屬性和方法,來方便遍歷整個文檔。用parentNode屬性和childNodes[]數組可以在文檔樹中上下移動;通過遍歷childNodes[]數組或者使用firstChild和nextSibling屬性進行循環操作,也可以使用lastChild和previousSibling進行逆向循環操作,也可以枚舉指定節點的子節點。而調用appendChild()、insertBefore()、removeChild()、replaceChild()方法可以改變一個節點的子節點從而改變文檔樹。
需要指出的是,childNodes[]的值實際上是一個NodeList對象。因此,可以通過遍歷childNodes[]數組的每個元素,來枚舉一個給定節點的所有子節點;通過遞歸,可以枚舉樹中的所有節點。下表列出了Node對象的一些常用屬性和方法:
Node對象常用屬性:
屬性 描述 attributes 如果該節點是一個Element,則以NamedNodeMap形式返回該元素的屬性。 childNodes 以Node[]的形式存放當前節點的子節點。如果沒有子節點,則返回空數組。 firstChild 以Node的形式返回當前節點的第一個子節點。如果沒有子節點,則為null。 lastChild 以Node的形式返回當前節點的最後一個子節點。如果沒有子節點,則為null。 nextSibling 以Node的形式返回當前節點的兄弟下一個節點。如果沒有這樣的節點,則返回null。 nodeName 節點的名字,Element節點則代表Element的標記名稱。 nodeType 代表節點的類型。 parentNode 以Node的形式返回當前節點的父節點。如果沒有父節點,則為null。 previousSibling 以Node的形式返回緊挨當前節點、位於它之前的兄弟節點。如果沒有這樣的節點,則返回null。Node對象常用方法:
方法 描述 appendChild() 通過把一個節點增加到當前節點的childNodes[]組,給文檔樹增加節點。 cloneNode() 復制當前節點,或者復制當前節點以及它的所有子孫節點。 hasChildNodes() 如果當前節點擁有子節點,則將返回true。 insertBefore() 給文檔樹插入一個節點,位置在當前節點的指定子節點之前。如果該節點已經存在,則刪除之再插入到它的位置。 removeChild() 從文檔樹中刪除並返回指定的子節點。 replaceChild() 從文檔樹中刪除並返回指定的子節點,用另一個節點替換它。接下來,讓我們使用上述的DOM應用編程接口,來試著操作Html文檔。
A、遍歷文檔的節點
DOM把一個Html文檔視為樹,因此,遍歷整個樹是應該是家常便飯。跟之前說過的一樣,這裡我們提供兩個遍歷樹的例子。通過它,我們能夠學會如何使用childNodes[]和firstChile、lastChild、nextSibling、previousSibling遍歷整棵樹。
例子1-- sample3_1.htm:
這個例子使用了childNodes[]和遞歸方式來遍歷整個文檔,統計文檔中出現的Element元素總數,並把Element標記名全部打印出來。需要特別注意的是,在使用DOM時,必須等文檔被裝載完畢再執行遍歷等行為操作文檔。sample3_1.htm具體代碼如下:
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">var elementName = ""; //全局變量,保存Element標記名,使用完畢要清空function countTotalElement(node) { //參數node是一個Node對象var total = 0;if(node.nodeType == 1) { //檢查node是否為Element對象total++;//如果是,計數器加1elementName = elementName + node.tagName + "\r\n"; //保存標記名}var childrens = node.childNodes;//獲取node的全部子節點for(var i=0;i<childrens.length;i++) {total += countTotalElement(childrens[i]); //在每個子節點上進行遞歸操作}return total;}</script></head><body><a href="Javascript:void(0)" >開始統計</a></body></Html>


例子2 – sample3_2.htm:
接下來使用firstChile、lastChild、nextSibling、previousSibling遍歷整個文檔樹。修改一下countTotalElement函數,其他跟sample3_1.htm一樣:
function countTotalElement(node) { //參數node是一個Node對象var total = 0;if(node.nodeType == 1) { //檢查node是否為Element對象total++;//如果是,計數器加1elementName = elementName + node.tagName + "\r\n"; //保存標記名}var childrens = node.childNodes;//獲取node的全部子節點for(var m=node.firstChild; m!=null;m=m.nextSibling) {total += countTotalElement(m); //在每個子節點上進行遞歸操作}return total;}
B、搜索文檔中特定的元素
在使用DOM的過程中,有時候需要定位到文檔中的某個特定節點,或者具有特定類型的節點列表。這種情況下,可以調用Document對象的getElementsByTagName()和getElementById()方法來實現。
document.getElementsByTagName()返回文檔中具有指定標記名的全部Element節點數組(也是NodeList類型)。Element出現在數組中的順序就是他們在文檔中出現的順序。傳遞給getElementsByTagName()的參數忽略大小寫。比如,想定位到第一個<table>標記,可以這樣寫:document.getElementsByTagName(“table”)[0]。例外的,可以使用document.body定位到<body>標記,因為它是唯一的。
getElementsByTagName()返回的數組取決於文檔。一旦文檔改變,返回結果也立即改變。相比,getElementById()則比較靈活,可以隨時定位到目標,只是要實現給目標元素一個唯一的id屬性值。這個我們在《AJax開發簡略》的“級聯菜單”例子中已經使用過了。
Element對象也支持getElementsByTagName()和getElementById()。不同的是,搜索領域只針對調用者的子節點。
C、修改文檔內容
遍歷整棵文檔樹、搜索特定的節點,我們最終目的之一是要修改文檔內容。接下來的三個例子將使用Node的幾個常用方法,來演示如何修改文檔內容。
例子3 -- sample4_1.htm:
這個例子包含三個文本節點和一個按鈕。點擊按鈕後,三個文本節點和按鈕的順序將被顛倒。程序使用了Node的appendChild()和removeChild()方法。
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">function reverseNode(node) { // 顛倒節點node的順序var kids = node.childNodes; //獲取子節點列表var kidsNum = kids.length; //統計子節點總數for(var i=kidsNum-1;i>=0;i--) { //逆向遍歷子節點列表var c = node.removeChild(kids[i]); //刪除指定子節點,保存在c中node.appendChild(c); //將c放在新位置上}}</script></head><body><p>第一行</p><p>第二行</p><p>第三行</p><p><input type="button" name="reverseGo" value="顛倒" ></p></body></Html>


例子4-- sample4_2.htm:
例子1通過直接操作body的子節點來修改文檔。在Html文檔中,布局和定位常常通過表格<table>來實現。因此,例子4將演示操作表格內容,將表格的四個單元行順序顛倒。如果沒有使用<tbody>標簽,則<table>把全部的<tr>當做是屬於一個子節點<tbody>,所以我們采用數組緩存的方式,把行數據顛倒一下。這個例子同時也演示了如何使用DOM創建表格單元行。
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">function reverseTable() {var node = document.getElementsByTagName("table")[0]; //第一個表格var child = node.getElementsByTagName("tr"); //取得表格內的所有行var newChild = new Array(); //定義緩存數組,保存行內容for(var i=0;i<child.length;i++) {newChild[i] = child[i].firstChild.innerHTML; }node.removeChild(node.childNodes[0]); //刪除全部單元行var header = node.createTHead(); //新建表格行頭for(var i=0;i<newChild.length;i++) {var headerrow = header.insertRow(i); //插入一個單元行var cell = headerrow.insertCell(0); //在單元行中插入一個單元格//在單元格中創建TextNode節點cell.appendChild(document.createTextNode(newChild[newChild.length-i-1]));}}</script></head><body><table width="200" border="1" cellpadding="4" cellspacing="0"> <tr> <td height="25">第一行</td> </tr> <tr> <td height="25">第二行</td> </tr> <tr> <td height="25">第三行</td> </tr> <tr> <td height="25">第四行</td> </tr></table><br><input type="button" name="reverse" value="開始顛倒" ></body></Html>


例子5 -- sample4_3.htm:
正如我們在Node節點介紹部分所指出的那樣,appendChild()、replaceChild()、removeChild()、insertBefore()方法會立即改變文檔的結構。下面的例子包含兩個表格,我們試著把表格二的內容替換表格一的內容。
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">function replaceContent() {var table1 = document.getElementsByTagName("table")[0];var table2 = document.getElementsByTagName("table")[1];var kid1 = table1.firstChild.firstChild.firstChild; //定位到<td>節點var kid2 = table2.firstChild.firstChild.firstChild; //定位到<td>節點var repKid = kid2.firstChild; //定位到表格二<td>內含的TextNode節點try {//用表格二的單元格內容替換表格一的單元格內容,表格二變成沒有單元格內容kid1.replaceChild(repKid,kid1.firstChild); //下面注釋如果開放,將出現object error,因為表格二已經被改變//kid2.replaceChild(kid1.firstChild,kid2.firstChild);}catch(e){alert(e);}}</script></head><body><table width="200" border="1" cellspacing="0" cellpadding="0"><tbody> <tr> <td>表格一</td> </tr></tbody></table><br><table width="200" border="1" cellspacing="0" cellpadding="0"><tbody> <tr> <td>表格二</td> </tr></tbody></table><br><input type="button" name="replaceNode" value="替換" ></body></Html>


注意,當執行kid1.replaceChild(repKid,kid1.firstChild);的時候,table2的子節點已經被轉移到table1了,table2已經沒有子節點,不能再調用table2的子節點。看看代碼的注釋,試著運行一下,應該就知道文檔是怎麼改變的了。
D、往文檔添加新內容
在學會遍歷、搜索、修改文檔之後,我們現在試著網文檔添加新的內容。其實沒有什麼新意,只是利用我們上述提到的Node的屬性和方法而已,還是操作<table>標記的內容。有新意的是,我們要實現一個留言簿。是的,留言簿,你可以往裡面留言,只是不能刷新噢。
例子6 – sample5_1.htm:
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">function insertStr() {var f = document.form1;var value = f.str.value;if(value!="") {// 從最終的TextNode節點開始,慢慢形成<tbody>結構var text = document.createTextNode(value); //新建一個TextNode節點var td = document.createElement("td"); //新建一個td類型的Element節點var tr = document.createElement("tr"); //新建一個tr類型的Element節點var tbody = document.createElement("tbody"); //新建一個tbody類型的Element節點td.appendChild(text); //將節點text加入td中tr.appendChild(td); //將節點td加入tr中tbody.appendChild(tr); //將節點tr加入tbody中var parNode = document.getElementById("table1"); //定位到table上parNode.insertBefore(tbody,parNode.firstChild); //將節點tbody插入到節點頂部//parNode.appendChild(tbody); //將節點tbody加入節點尾部}}</script></head><body><form name="form1" method="post" action=""> <input name="str" type="text" id="str" value=""> <input name="insert" type="button" id="insert" value="留言" ></form><table width="400" border="1" cellspacing="0" cellpadding="0" id="table1"><tbody> <tr> <td height="25">網友留言列表:</td> </tr></tbody></table></body></Html>
我們之前說過,<table>的子節點是<tbody>,<tbody>的子節點才是<tr>,<tr>是<td>的父節點,最後<td>內部的TextNode節點。所以,往<table>增加單元格行要逐級形成,就像往樹裡面添加一個枝桠一樣,要有葉子有徑。看看,這個留言簿是不是很簡單啊。這個例子同時也演示了往<table>表格標記裡面增加內容的另一種方法。


E、使用DOM操作XML文檔
在數據表示方面,XML文檔更加結構化。DOM在支持HTML的基礎上提供了一系列的API,支持針對XML的訪問和操作。利用這些API,我們可以從XML中提取信息,動態的創建這些信息的HTML呈現文檔。處理XML文檔,通常遵循“加載XML文檔à提取信息à加工信息à創建Html文檔”的過程。下面的例子演示了如何加載並處理XML文檔。
這個例子包含兩個JS函數。loadXML()負責加載XML文檔,其中既包含加載XML文檔的2級DOM代碼,又有實現同樣操作的Microsoft專有API代碼。需要提醒注意的是,文檔加載過程不是瞬間完成的,所以對loadXML()的調用將在加載文檔完成之前返回。因此,需要傳遞給loadXML()一個引用,以便文檔加載完成後調用。
例子中的另外一個函數makeTable(),則在XML文檔加載完畢之後,使用最後前介紹過的DOM應用編程接口讀取XML文檔信息,並利用這些信息形成一個新的table表格。
例子7 -- sample6_1.htm:
<html><head><meta http-equiv="Content-Type" content="text/Html; charset=gb2312"><title>無標題文檔</title><script language="Javascript">function loadXML(handler) {var url = "employees.xml";if(document.implementation&&document.implementation.createDocument) {var xmldoc = document.implementation.createDocument("", "", null);xmldoc.onload = handler(xmldoc, url);xmldoc.load(url);}else if(window.ActiveXObject) {var xmldoc = new ActiveXObject("Microsoft.XMLDOM");xmldoc.onreadystatechange = function() {if(xmldoc.readyState == 4) handler(xmldoc, url);}xmldoc.load(url);}}function makeTable(xmldoc, url) {var table = document.createElement("table");table.setAttribute("border","1");table.setAttribute("width","600");table.setAttribute("class","tab-content");document.body.appendChild(table);var caption = "Employee Data from " + url;table.createCaption().appendChild(document.createTextNode(caption));var header = table.createTHead();var headerrow = header.insertRow(0);headerrow.insertCell(0).appendChild(document.createTextNode("姓名"));headerrow.insertCell(1).appendChild(document.createTextNode("職業"));headerrow.insertCell(2).appendChild(document.createTextNode("工資"));var employees = XMLdoc.getElementsByTagName("employee");for(var i=0;i<employees.length;i++) {var e = employees[i];var name = e.getAttribute("name");var job = e.getElementsByTagName("job")[0].firstChild.data;var salary = e.getElementsByTagName("salary")[0].firstChild.data;var row = table.insertRow(i+1);row.insertCell(0).appendChild(document.createTextNode(name));row.insertCell(1).appendChild(document.createTextNode(job));row.insertCell(2).appendChild(document.createTextNode(salary));}}</script><link href="css/style.css" rel="stylesheet" type="text/CSS"></head><body ></body></Html>
供讀取調用的XML文檔 – employees.XML:
<?XML version="1.0" encoding="gb2312"?><employees><employee name="J.Doe"><job>Programmer</job><salary>32768</salary></employee><employee name="A.Baker"><job>Sales</job><salary>70000</salary></employee><employee name="Big Cheese"><job>CEO</job><salary>100000</salary></employee></employees>7.5、處理XML文檔脫離XML文檔的AJAX是不完整的。在本部分未完成之前,有讀者說AJax改名叫AJAH(H應該代表Html吧)比較合適。應該承認,XML文檔在數據的結構化表示以及接口對接上有先天的優勢,但也不是所有的數據都應該用XML表示。有些時候單純的文本表示可能會更合適。下面先舉個AJax處理返回XML文檔的例子再討論什麼時候使用XML。
7.5.1、處理返回的XML
例子8 -- sample7_1.htm:
在這個例子中,我們采用之前確定的AJax開發框架,稍微修改一下body內容和processRequest的相應方式,將先前的employees.XML的內容讀取出來並顯示。
body的內容如下:
<input type="button" name="read" value="讀取XML" >processRequest()方法修改如下:// 處理返回信息的函數 function processRequest() { if (http_request.readyState == 4) { // 判斷對象狀態 if (http_request.status == 200) { // 信息已經成功返回,開始處理信息var returnObj = http_request.responseXML;var xmlobj = http_request.responseXML;var employees = xmlobj.getElementsByTagName("employee");var feedbackStr = "";for(var i=0;i<employees.length;i++) { // 循環讀取employees.XML的內容var employee = employees[i];feedbackStr += "員工:" + employee.getAttribute("name");feedbackStr += " 職位:" + employee.getElementsByTagName("job")[0].firstChild.data;feedbackStr += " 工資:" + employee.getElementsByTagName("salary")[0].firstChild.data;feedbackStr += "\r\n";}alert(feedbackStr); } else { //頁面不正常 alert("您所請求的頁面有異常。"); } }}
運行一下,看來效果還不錯:

現在的web應用程序往往采用了MVC三層剝離的設計方式。XML作為一種數據保存、呈現、交互的文檔,其數據往往是動態生成的,通常由JavaBean轉換過來。由JavaBean轉換成XML文檔的方式有好幾種,選擇合適的轉換方式往往能達到事半功倍的效果。下面介紹兩種常用的方式,以便需要的時候根據情況取捨。
A、類自行序列化成XML
類自行序列化成XML即每個類都實現自己的toXML()方法,選擇合適的API、適當的XML結構、盡量便捷的生成邏輯快速生成相應的XML文檔。顯然,這種方式必須要求每個類編寫專門的XML生成代碼,每個類只能調用自己的toXML()方法。應用諸如JDOM等一些現成的API,可以減少不少開發投入。例子9是一個利用JDOM的API形成的toXML()方法。
例子9 -- toXml() 的 JDOM 實現 -- Employ類的toXML()方法:
public Element toXML() { Element employee = new Element(“employee”);Employee.setAttribute(“name”,name);Element jobE = new Element(“job”).addContent(job);employee.setContent(jobE);Element salaryE = new Element(“salary”).addContent(salary);employee.setContent(salaryE);return employee;}
JDOM提供了現成的API,使得序列化成XML的工作更加簡單,我們只需要把toXML()外面包裝一個Document,然後使用XMLOutputter把文檔寫入servlet就可以了。toXml()允許遞歸調用其子類的toXML()方法,以便生成包含子圖的XML文檔。
使用類自行序列化成XML的方式,要每個類都實現自己的toXML()方法,而且存在數據模型與視圖耦合的問題,即要麼為每個可能的視圖編寫獨立的toXML()方法,要麼心甘情願接收冗余的數據,一旦數據結構或者文檔發生改變,toXML()就要做必要的修改。
B、頁面模板生成XML方式
一般的,可以采用通用的頁面模板技術來生成XML文檔,這個XML文檔可以符合任何需要的數據模型,供AJax靈活的調用。另外,模板可以采用任何標記語言編寫,提高工作效率。下面是一個采用Struts標簽庫編寫的XML文檔,輸出之前提到的employees.XML:
Sample8_2.JSP:
<%@ page contentType="application/XML; charset=gb2312" import="Employee"%><%@ page import="java.util.Collection,Java.util.ArrayList"%><?XML version="1.0"?><%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic" %><%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%><%Employee em1 = new Employee();em1.setName("J.Doe");em1.setJob("Programmer");em1.setSalary("32768");Employee em2 = new Employee();em2.setName("A.Baker");em2.setJob("Sales");em2.setSalary("70000");Employee em3 = new Employee();em3.setName("Big Cheese");em3.setJob("CEO");em3.setSalary("100000");Collection employees = new ArrayList();employees.add(em1);employees.add(em2);employees.add(em3);pageContext.setAttribute("employees",employees);%><employees><logic:iterate name="employees" id="employee"><employee name="<bean:write name='employee' property='name'/>"><job><bean:write name="employee" property="job"/></job><salary><bean:write name="employee" property="salary"/></salary></employee></logic:iterate></employees>

采用頁面模板生成XML方式,需要為每個需要的的數據模型建立一個對立的JSP文件,用來生成符合規范的XML文檔,而不能僅僅在類的toXML()方法中組織對象圖來實現。不過,倒是可以更加方便的確保標記匹配、元素和屬性的順序正確以及XML實體正確轉義。
參考資料中Philip McCarthy的文章還描述了一種Javascript對象標注的生成方式,本文在此不贅述。有興趣的讀者可以自行查看了解。
7.5.3、如何在使用XML還是普通文本間權衡使用XML文檔確實有其方便之處。不過XML文檔的某些問題倒是要考慮一下,比如說延遲,即服務器不能立即解析XML文檔成為DOM模型。這個問題在一定程度上會影響AJax要求的快速反應能力。另外,某些情況下我們並不需要使用XML來表示數據,比如說數據足夠簡單成只有一個字符串而已。就好像我們之前提到的數據校驗和級聯菜單的例子一樣。所以,個人認為在下面這些情況下可以考慮使用XML來作為數據表示的介質:
- 數據比較復雜,需要用XML的結構化方式來表示
- 不用考慮帶寬和處理效率支出
- 與系統其他API或者其他系統交互,作為一種數據中轉中介
- 需要特定各式的輸出視圖而文本無法表示的
總之,要認真評估兩種表示方式的表示成本和效率,選擇合適的合理的表示方式。
在關於AJax的系列文章的下一篇,我們將綜合使用DOM和XML,來實現一個可以持久化的簡單留言簿。另外,還將試著模擬MSN Space的部分功能,來體會AJax的魅力。