前言
近年來各站點基於 Web 的多終端適配進行得如火如荼,行業間也發展出依賴各種技術的解決方案。有如基於浏覽器原生 CSS3 Media Query 的響應式設計、基於雲端智能重排的「雲適配」方案等。本文則主要探討在前後端分離基礎下的多終端適配方案。
關於前後端分離
關於前後端分離的方案,在《基於NodeJS的前後端分離的思考與實踐(一)》中有非常清晰的解釋。我們在服務端接口和浏覽器之間引入 NodeJS 作為渲染層,因為 NodeJS 層徹底與數據抽離,同時無需關心大量的業務邏輯,所以十分適合在這一層進行多終端的適配工作。
UA 探測
進行多終端適配首先要解決的是 UA 探測問題,對於一個過來的請求,我們需要知道這個設備的類型才能針對對它輸出對應的內容。現在市面上已經有非常成熟的兼容大量設備的 User Agent 特征庫和探測工具,這裡有 Mozilla 整理的一個列表。其中,既有運行在浏覽器端的,也有運行在服務端代碼層的,甚至有些工具提供了 Nginx/Apache 的模塊,負責解析每個請求的 UA 信息。
實際上我們推薦最後一種方式。基於前後端分離的方案決定了 UA 探測只能運行在服務器端,但如果把探測的代碼和特征庫耦合在業務代碼裡並不是一個足夠友好的方案。我們把這個行為再往前挪,掛在 Nginx/Apache 上,它們負責解析每個請求的 UA 信息,再通過如 HTTP Header 的方式傳遞給業務代碼。
這樣做有幾點好處:
我們的代碼裡面無需再去關注 UA 如何解析,直接從上層取出解析後的信息即可。如果在同一台服務器上有多個應用,則能夠共同使用同一個 Nginx 解析後的 UA 信息,節省了不同應用間的解析損耗。
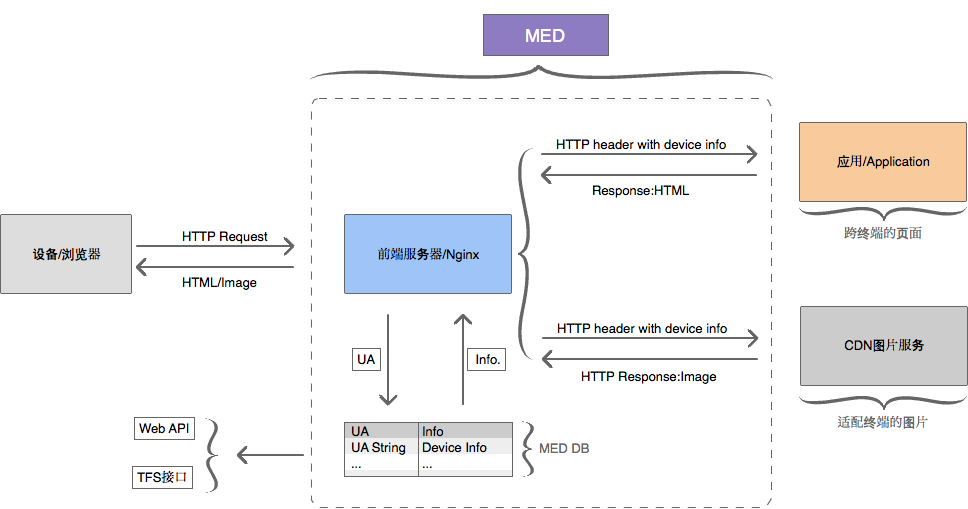
來自天貓分享的基於 Nginx 的 UA 探測方案
淘寶的 Tengine Web 服務器也提供了類似的模塊 ngx_http_user_agent_module。
值得一提的是,選用 UA 探測工具時必須要考慮特征庫的可維護性,因為市面上新增的設備類型越來越多,每個設備都會有獨立的 User Agent,所以該特征庫必須提供良好的更新和維護策略,以適應不斷變化的設備。
建立在 MVC 模式中的幾種適配方案
取得 UA 信息後,我們就要考慮如果根據指定的 UA 進行終端適配了。即使在 NodeJS 層,雖然沒有了大部分的業務邏輯,但我們依然把內部區分為 Model / Controller / View 三個模型。
我們先利用上面的圖,去解析一些已有的多終端適配方案。
建立在 Controller 上的適配方案
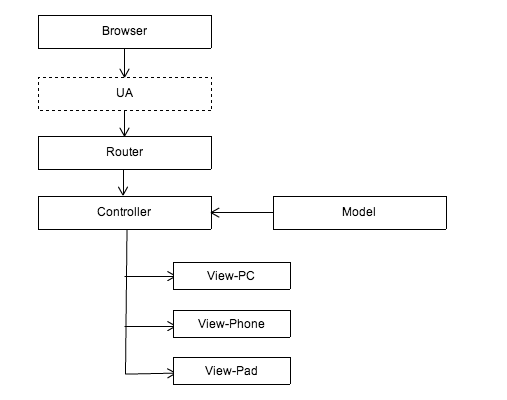
這種方案應該是最簡單粗暴的處理方法。通過路由(Router)將相同的 URL 統一傳遞到同一個控制層(Controller)。控制層再通過 UA 信息將數據和模型(Model)邏輯派發到對應的展現(View)進行渲染,渲染層則按預先的約定提供了適配幾個終端的模板。
這種方案的好處是,保持了數據和控制層的統一性,業務邏輯只需處理一次遍可以應用在所有終端上。但這種場景只適合如展示型頁面等低交互型的應用,一旦業務比較復雜,各個終端的 Controller 可能有各自的處理邏輯,如果還是共用一個 Controller ,會導致 Controller 非常的臃腫而且難以維護,這無疑是一個錯誤的選擇。
建立在 Router 上的適配方案
為了解決上面遇到的問題,我們可以在 Router 上就將設備區分,針對不同的終端分發到不同的 Controller 上:
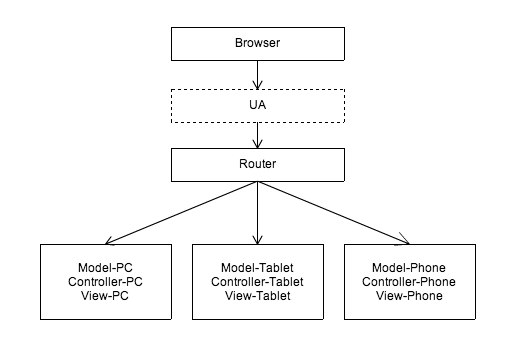
這也是最常見的方案之一,大多表現在針對不同終端使用各自獨立的一套應用。如 PC 淘寶首頁和 WAP 版的淘寶首頁,不同設備訪問 www.taobao.com ,服務器會通過 Router 的控制,重定向到 WAP 版的淘寶首頁或者 PC 版的淘寶首頁,它們各自是完全獨立的兩套應用。
但這種方案無疑帶來了數據和部分邏輯無法共用的問題,各種終端之間無法分享同一份數據和業務邏輯,產生大量重復性工作,效率低下。
為了緩解這個問題,有人提出了優化後的方案:依然是在同一套應用裡面,各個數據來源抽象成各個 Model,提供給不同終端的 Controller 組合使用:
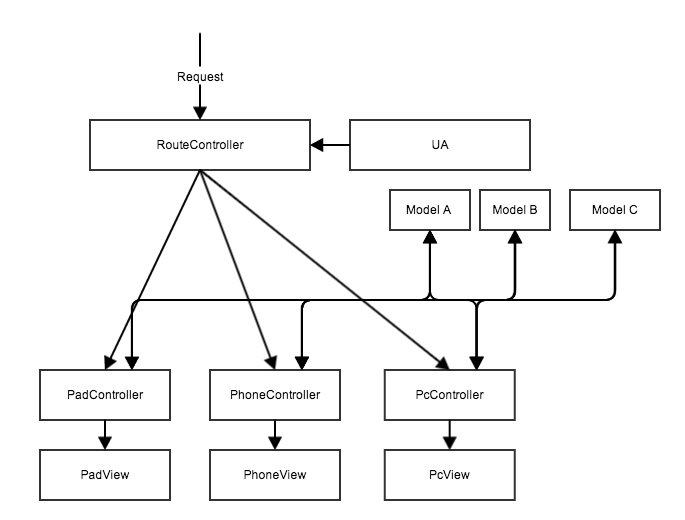
這個方案解決了前面數據無法共用的問題。在 Controller 上各個終端還是相互獨立,但能共同使用同一批數據源,至少在數據上無需再針對終端類型開發獨立的接口了。
以上兩種基於 Router 的方案,由於 Controller 的獨立,各個終端可以為自己的頁面實現不同的交互邏輯,保證了各終端自身足夠的靈活度,這也是為什麼大部分應用采用這種方案的主要原因。
建立在 View 層的適配方案
這是淘寶下單頁面使用的方案,不過區別是下單頁將整體的渲染層放在了浏覽器端,而不是 NodeJS 層。不過無論是浏覽器還是 NodeJS,整體設計思路還是一致的:
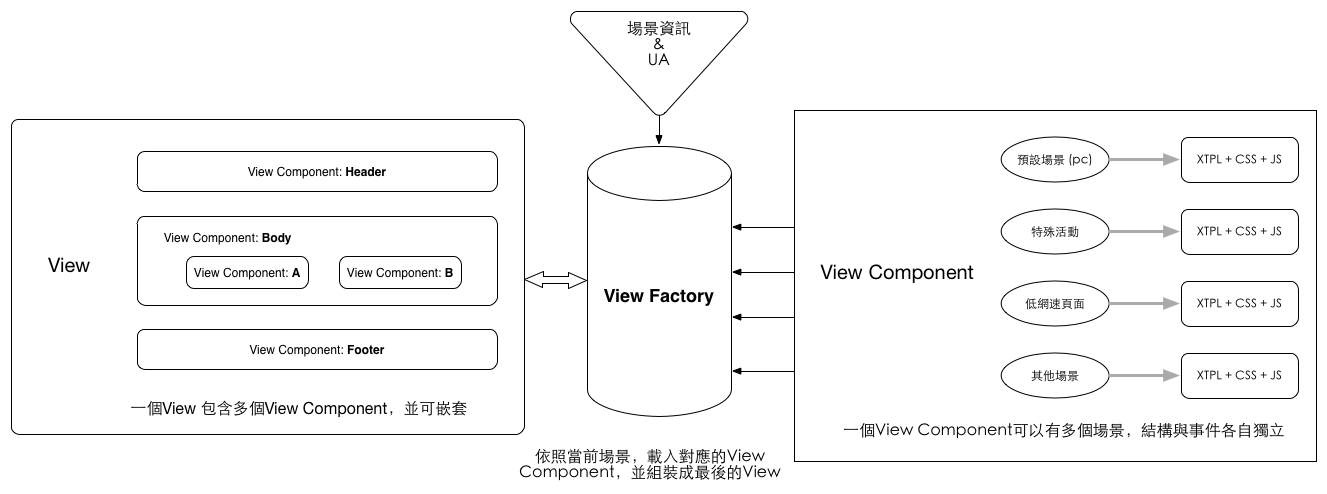
在這個方案裡面,Router、Controller 和 Model 都無需關注設備信息,終端類型的判斷完全交給展現層來處理。圖中主要的模塊是「View Factory」,Model 和 Controller 將數據和渲染邏輯傳遞過來之後,通過 View Factory 根據設備信息和其它狀態(不僅僅是 UA 信息、也可以是網絡環境、用戶地區等等)從一堆預設好的組件(View Component)中抓取特定的組件,再組合成最終的頁面。
這種方案有幾個優勢:
上層無需關注設備信息(UA),多終端的視頻還是交由和最終展現最大關系的 View 層來處理;不僅僅是多終端適配,除了 UA 信息,各個 View Component 還可以根據用戶狀態決定自身輸出何種模版,如低網速下默認隱藏圖片、指定地區輸出活動 Banner。每個 View Component 的不同模版間可以自行決定是否使用同一份數據、業務邏輯,提供十分靈活的實現方式。
但明顯的是,這個方案也是最復雜的,尤其是要考慮一些富交互的應用場景時,Router 和 Controller 也許無法保持這麼純粹。特別對於一些整體性比較強的業務,本身無法被拆分成組件,這種方案也許並不適用;而且對於一些簡單的業務,使用這種架構可能不是最佳的選擇。
總結
以上幾種方案,都各自體現在 MVC 模型中的一個或多個部分,在業務上如果一個方案不滿足需求,更可以采取多個方案同時采用的方式。或是可以理解為,業務上的復雜度和交互屬性決定了該產品更適合采用哪種多終端適配方案。
對比基於浏覽器的響應式設計方案,因為絕大部分終端探測和渲染邏輯遷移到了服務端,所以在 NodeJS 層進行適配無疑帶來了更好的性能和用戶體驗;另外,相對於一些所謂的「雲適配」方案帶來的轉換質量問題,在基於前後端分離的「定制式」方案中也不會存在。前後端分離的適配方案在這些方面有著天然優勢。
最後,為了適應更靈活的強大的適配需求,基於前後端分離的適配方案將會面臨更多挑戰!