本文目標
30分鐘內讓你明白正則表達式是什麼,並對它有一些基本的了解,讓你可以在自己的程序或網頁裡使用它。
如何使用本教程
別被下面那些復雜的表達式嚇倒,只要跟著我一步一步來,你會發現正則表達式其實並沒有你想像中的那麼困難。當然,如果你看完了這篇教程之後,發現自己明白了很多,卻又幾乎什麼都記不得,那也是很正常的——我認為,沒接觸過正則表達式的人在看完這篇教程後,能把提到過的語法記住80%以上的可能性為零。這裡只是讓你明白基本的原理,以後你還需要多練習,多使用,才能熟練掌握正則表達式。
除了作為入門教程之外,本文還試圖成為可以在日常工作中使用的正則表達式語法參考手冊。就作者本人的經歷來說,這個目標還是完成得不錯的——你看,我自己也沒能把所有的東西記下來,不是嗎?
正則表達式到底是什麼東西?
在編寫處理字符串的程序或網頁時,經常會有查找符合某些復雜規則的字符串的需要。正則表達式就是用於描述這些規則的工具。換句話說,正則表達式就是記錄文本規則的代碼。
很可能你使用過Windows/Dos下用於文件查找的通配符(wildcard),也就是*和?。如果你想查找某個目錄下的所有的Word文檔的話,你會搜索*.doc。在這裡,*會被解釋成任意的字符串。和通配符類似,正則表達式也是用來進行文本匹配的工具,只不過比起通配符,它能更精確地描述你的需求——當然,代價就是更復雜——比如你可以編寫一個正則表達式,用來查找所有以0開頭,後面跟著2-3個數字,然後是一個連字號“-”,最後是7或8位數字的字符串(像010-12345678或0376-7654321)。
入門
學習正則表達式的最好方法是從例子開始,理解例子之後再自己對例子進行修改,實驗。下面給出了不少簡單的例子,並對它們作了詳細的說明。
假設你在一篇英文小說裡查找hi,你可以使用正則表達式hi。
這幾乎是最簡單的正則表達式了,它可以精確匹配這樣的字符串:由兩個字符組成,前一個字符是h,後一個是i。通常,處理正則表達式的工具會提供一個忽略大小寫的選項,如果選中了這個選項,它可以匹配hi,HI,Hi,hI這四種情況中的任意一種。
不幸的是,很多單詞裡包含hi這兩個連續的字符,比如him,history,high等等。用hi來查找的話,這裡邊的hi也會被找出來。如果要精確地查找hi這個單詞的話,我們應該使用\bhi\b。
\b是正則表達式規定的一個特殊代碼(好吧,某些人叫它元字符,metacharacter),代表著單詞的開頭或結尾,也就是單詞的分界處。雖然通常英文的單詞是由空格,標點符號或者換行來分隔的,但是\b並不匹配這些單詞分隔字符中的任何一個,它只匹配一個位置。
假如你要找的是hi後面不遠處跟著一個Lucy,你應該用\bhi\b.*\bLucy\b。
這裡,.是另一個元字符,匹配除了換行符以外的任意字符。*同樣是元字符,不過它代表的不是字符,也不是位置,而是數量——它指定*前邊的內容可以連續重復使用任意次以使整個表達式得到匹配。因此,.*連在一起就意味著任意數量的不包含換行的字符。現在\bhi\b.*\bLucy\b的意思就很明顯了:先是一個單詞hi,然後是任意個任意字符(但不能是換行),最後是Lucy這個單詞。
如果同時使用其它元字符,我們就能構造出功能更強大的正則表達式。比如下面這個例子:
0\d\d-\d\d\d\d\d\d\d\d匹配這樣的字符串:以0開頭,然後是兩個數字,然後是一個連字號“-”,最後是8個數字(也就是中國的電話號碼。當然,這個例子只能匹配區號為3位的情形)。
這裡的\d是個新的元字符,匹配一位數字(0,或1,或2,或……)。-不是元字符,只匹配它本身——連字符(或者減號,或者中橫線,或者隨你怎麼稱呼它)。
為了避免那麼多煩人的重復,我們也可以這樣寫這個表達式:0\d{2}-\d{8}。 這裡\d後面的{2}({8})的意思是前面\d必須連續重復匹配2次(8次)。
測試正則表達式
如果你不覺得正則表達式很難讀寫的話,要麼你是一個天才,要麼,你不是地球人。正則表達式的語法很令人頭疼,即使對經常使用它的人來說也是如此。由於難於讀寫,容易出錯,所以找一種工具對正則表達式進行測試是很有必要的。
不同的環境下正則表達式的一些細節是不相同的,本教程介紹的是微軟 .Net Framework 4.0 下正則表達式的行為,所以,我向你推薦我編寫的.Net下的工具 正則表達式測試器。請參考該頁面的說明來安裝和運行該軟件。
下面是Regex Tester運行時的截圖:
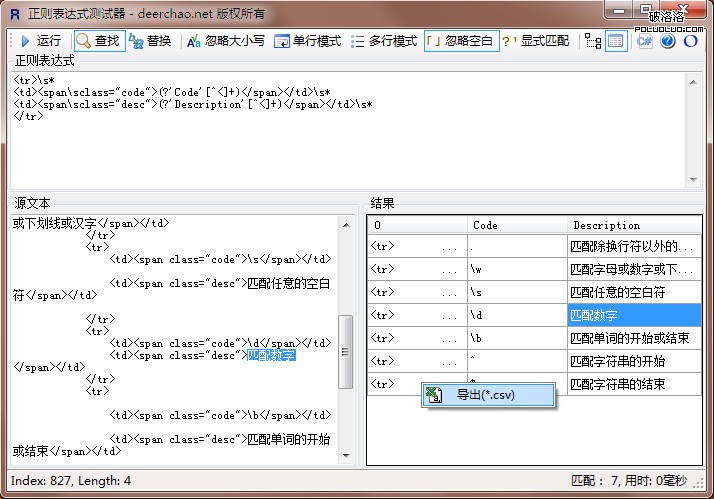
現在你已經知道幾個很有用的元字符了,如\b,.,*,還有\d.正則表達式裡還有更多的元字符,比如\s匹配任意的空白符,包括空格,制表符(Tab),換行符,中文全角空格等。\w匹配字母或數字或下劃線或漢字等。
下面來看看更多的例子:
\ba\w*\b匹配以字母a開頭的單詞——先是某個單詞開始處(\b),然後是字母a,然後是任意數量的字母或數字(\w*),最後是單詞結束處(\b)。
\d+匹配1個或更多連續的數字。這裡的+是和*類似的元字符,不同的是*匹配重復任意次(可能是0次),而+則匹配重復1次或更多次。
\b\w{6}\b 匹配剛好6個字符的單詞。
元字符^(和數字6在同一個鍵位上的符號)和$都匹配一個位置,這和\b有點類似。^匹配你要用來查找的字符串的開頭,$匹配結尾。這兩個代碼在驗證輸入的內容時非常有用,比如一個網站如果要求你填寫的QQ號必須為5位到12位數字時,可以使用:^\d{5,12}$。
這裡的{5,12}和前面介紹過的{2}是類似的,只不過{2}匹配只能不多不少重復2次,{5,12}則是重復的次數不能少於5次,不能多於12次,否則都不匹配。
因為使用了^和$,所以輸入的整個字符串都要用來和\d{5,12}來匹配,也就是說整個輸入必須是5到12個數字,因此如果輸入的QQ號能匹配這個正則表達式的話,那就符合要求了。
和忽略大小寫的選項類似,有些正則表達式處理工具還有一個處理多行的選項。如果選中了這個選項,^和$的意義就變成了匹配行的開始處和結束處。
字符轉義
如果你想查找元字符本身的話,比如你查找.,或者*,就出現了問題:你沒辦法指定它們,因為它們會被解釋成別的意思。這時你就得使用\來取消這些字符的特殊意義。因此,你應該使用\.和\*。當然,要查找\本身,你也得用\\.
例如:deerchao\.net匹配deerchao.net,C:\\Windows匹配C:\Windows。
重復
你已經看過了前面的*,+,{2},{5,12}這幾個匹配重復的方式了。下面是正則表達式中所有的限定符(指定數量的代碼,例如*,{5,12}等):
下面是一些使用重復的例子:
Windows\d+匹配Windows後面跟1個或更多數字
^\w+匹配一行的第一個單詞(或整個字符串的第一個單詞,具體匹配哪個意思得看選項設置)
字符類
要想查找數字,字母或數字,空白是很簡單的,因為已經有了對應這些字符集合的元字符,但是如果你想匹配沒有預定義元字符的字符集合(比如元音字母a,e,i,o,u),應該怎麼辦?
很簡單,你只需要在方括號裡列出它們就行了,像[aeiou]就匹配任何一個英文元音字母,[.?!]匹配標點符號(.或?或!)。
我們也可以輕松地指定一個字符范圍,像[0-9]代表的含意與\d就是完全一致的:一位數字;同理[a-z0-9A-Z_]也完全等同於\w(如果只考慮英文的話)。
下面是一個更復雜的表達式:\(?0\d{2}[) -]?\d{8}。
“(”和“)”也是元字符,後面的分組節裡會提到,所以在這裡需要使用轉義。
這個表達式可以匹配幾種格式的電話號碼,像(010)88886666,或022-22334455,或02912345678等。我們對它進行一些分析吧:首先是一個轉義字符\(,它能出現0次或1次(?),然後是一個0,後面跟著2個數字(\d{2}),然後是)或-或空格中的一個,它出現1次或不出現(?),最後是8個數字(\d{8})。
分枝條件
不幸的是,剛才那個表達式也能匹配010)12345678或(022-87654321這樣的“不正確”的格式。要解決這個問題,我們需要用到分枝條件。正則表達式裡的分枝條件指的是有幾種規則,如果滿足其中任意一種規則都應該當成匹配,具體方法是用|把不同的規則分隔開。聽不明白?沒關系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}這個表達式能匹配兩種以連字號分隔的電話號碼:一種是三位區號,8位本地號(如010-12345678),一種是4位區號,7位本地號(0376-2233445)。
\(?0\d{2}\)?[- ]?\d{8}|0\d{2}[- ]?\d{8}這個表達式匹配3位區號的電話號碼,其中區號可以用小括號括起來,也可以不用,區號與本地號間可以用連字號或空格間隔,也可以沒有間隔。你可以試試用分枝條件把這個表達式擴展成也支持4位區號的。
\d{5}-\d{4}|\d{5}這個表達式用於匹配美國的郵政編碼。美國郵編的規則是5位數字,或者用連字號間隔的9位數字。之所以要給出這個例子是因為它能說明一個問題:使用分枝條件時,要注意各個條件的順序。如果你把它改成\d{5}|\d{5}-\d{4}的話,那麼就只會匹配5位的郵編(以及9位郵編的前5位)。原因是匹配分枝條件時,將會從左到右地測試每個條件,如果滿足了某個分枝的話,就不會去再管其它的條件了。
分組
我們已經提到了怎麼重復單個字符(直接在字符後面加上限定符就行了);但如果想要重復多個字符又該怎麼辦?你可以用小括號來指定子表達式(也叫做分組),然後你就可以指定這個子表達式的重復次數了,你也可以對子表達式進行其它一些操作(後面會有介紹)。
(\d{1,3}\.){3}\d{1,3}是一個簡單的IP地址匹配表達式。要理解這個表達式,請按下列順序分析它:\d{1,3}匹配1到3位的數字,(\d{1,3}\.){3}匹配三位數字加上一個英文句號(這個整體也就是這個分組)重復3次,最後再加上一個一到三位的數字(\d{1,3})。
IP地址中每個數字都不能大於255,大家千萬不要被《24》第三季的編劇給忽悠了……
不幸的是,它也將匹配256.300.888.999這種不可能存在的IP地址。如果能使用算術比較的話,或許能簡單地解決這個問題,但是正則表達式中並不提供關於數學的任何功能,所以只能使用冗長的分組,選擇,字符類來描述一個正確的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解這個表達式的關鍵是理解2[0-4]\d|25[0-5]|[01]?\d\d?,這裡我就不細說了,你自己應該能分析得出來它的意義。
反義
有時需要查找不屬於某個能簡單定義的字符類的字符。比如想查找除了數字以外,其它任意字符都行的情況,這時需要用到反義:
例子:\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括號括起來的以a開頭的字符串。
後向引用
使用小括號指定一個子表達式後,匹配這個子表達式的文本(也就是此分組捕獲的內容)可以在表達式或其它程序中作進一步的處理。默認情況下,每個分組會自動擁有一個組號,規則是:從左向右,以分組的左括號為標志,第一個出現的分組的組號為1,第二個為2,以此類推。
呃……其實,組號分配還不像我剛說得那麼簡單:
1、分組0對應整個正則表達式
2、實際上組號分配過程是要從左向右掃描兩遍的:第一遍只給未命名組分配,第二遍只給命名組分配--因此所有命名組的組號都大於未命名的組號
3、你可以使用(?:exp)這樣的語法來剝奪一個分組對組號分配的參與權.
後向引用用於重復搜索前面某個分組匹配的文本。例如,\1代表分組1匹配的文本。難以理解?請看示例:
\b(\w+)\b\s+\1\b可以用來匹配重復的單詞,像go go, 或者kitty kitty。這個表達式首先是一個單詞,也就是單詞開始處和結束處之間的多於一個的字母或數字(\b(\w+)\b),這個單詞會被捕獲到編號為1的分組中,然後是1個或幾個空白符(\s+),最後是分組1中捕獲的內容(也就是前面匹配的那個單詞)(\1)。
你也可以自己指定子表達式的組名。要指定一個子表達式的組名,請使用這樣的語法:(?<Word>\w+)(或者把尖括號換成'也行:(?'Word'\w+)),這樣就把\w+的組名指定為Word了。要反向引用這個分組捕獲的內容,你可以使用\k<Word>,所以上一個例子也可以寫成這樣:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括號的時候,還有很多特定用途的語法。下面列出了最常用的一些:
我們已經討論了前兩種語法。第三個(?:exp)不會改變正則表達式的處理方式,只是這樣的組匹配的內容不會像前兩種那樣被捕獲到某個組裡面,也不會擁有組號。“我為什麼會想要這樣做?”——好問題,你覺得為什麼呢?
零寬斷言
地球人,是不是覺得這些術語名稱太復雜,太難記了?我也有同感。知道有這麼一種東西就行了,它叫什麼,隨它去吧!人若無名,便可專心練劍;物若無名,便可隨意取捨……
接下來的四個用於查找在某些內容(但並不包括這些內容)之前或之後的東西,也就是說它們像\b,^,$那樣用於指定一個位置,這個位置應該滿足一定的條件(即斷言),因此它們也被稱為零寬斷言。最好還是拿例子來說明吧:
斷言用來聲明一個應該為真的事實。正則表達式中只有當斷言為真時才會繼續進行匹配。
(?=exp)也叫零寬度正預測先行斷言,它斷言自身出現的位置的後面能匹配表達式exp。比如\b\w+(?=ing\b),匹配以ing結尾的單詞的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.時,它會匹配sing和danc。
(?<=exp)也叫零寬度正回顧後發斷言,它斷言自身出現的位置的前面能匹配表達式exp。比如(?<=\bre)\w+\b會匹配以re開頭的單詞的後半部分(除了re以外的部分),例如在查找reading a book時,它匹配ading。
假如你想要給一個很長的數字中每三位間加一個逗號(當然是從右邊加起了),你可以這樣查找需要在前面和裡面添加逗號的部分:((?<=\d)\d{3})+\b,用它對1234567890進行查找時結果是234567890。
下面這個例子同時使用了這兩種斷言:(?<=\s)\d+(?=\s)匹配以空白符間隔的數字(再次強調,不包括這些空白符)。
負向零寬斷言
前面我們提到過怎麼查找不是某個字符或不在某個字符類裡的字符的方法(反義)。但是如果我們只是想要確保某個字符沒有出現,但並不想去匹配它時怎麼辦?例如,如果我們想查找這樣的單詞--它裡面出現了字母q,但是q後面跟的不是字母u,我們可以嘗試這樣:
\b\w*q[^u]\w*\b匹配包含後面不是字母u的字母q的單詞。但是如果多做測試(或者你思維足夠敏銳,直接就觀察出來了),你會發現,如果q出現在單詞的結尾的話,像Iraq,Benq,這個表達式就會出錯。這是因為[^u]總要匹配一個字符,所以如果q是單詞的最後一個字符的話,後面的[^u]將會匹配q後面的單詞分隔符(可能是空格,或者是句號或其它的什麼),後面的\w*\b將會匹配下一個單詞,於是\b\w*q[^u]\w*\b就能匹配整個Iraq fighting。負向零寬斷言能解決這樣的問題,因為它只匹配一個位置,並不消費任何字符。現在,我們可以這樣來解決這個問題:\b\w*q(?!u)\w*\b。
零寬度負預測先行斷言(?!exp),斷言此位置的後面不能匹配表達式exp。例如:\d{3}(?!\d)匹配三位數字,而且這三位數字的後面不能是數字;\b((?!abc)\w)+\b匹配不包含連續字符串abc的單詞。
同理,我們可以用(?<!exp),零寬度負回顧後發斷言來斷言此位置的前面不能匹配表達式exp:(?<![a-z])\d{7}匹配前面不是小寫字母的七位數字。
請詳細分析表達式(?<=<(\w+)>).*(?=<\/\1>),這個表達式最能表現零寬斷言的真正用途。
一個更復雜的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含屬性的簡單HTML標簽內裡的內容。(?<=<(\w+)>)指定了這樣的前綴:被尖括號括起來的單詞(比如可能是<b>),然後是.*(任意的字符串),最後是一個後綴(?=<\/\1>)。注意後綴裡的\/,它用到了前面提過的字符轉義;\1則是一個反向引用,引用的正是捕獲的第一組,前面的(\w+)匹配的內容,這樣如果前綴實際上是<b>的話,後綴就是</b>了。整個表達式匹配的是<b>和</b>之間的內容(再次提醒,不包括前綴和後綴本身)。
注釋
小括號的另一種用途是通過語法(?#comment)來包含注釋。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注釋的話,最好是啟用“忽略模式裡的空白符”選項,這樣在編寫表達式時能任意的添加空格,Tab,換行,而實際使用時這些都將被忽略。啟用這個選項後,在#後面到這一行結束的所有文本都將被當成注釋忽略掉。例如,我們可以前面的一個表達式寫成這樣:
(?<= # 斷言要匹配的文本的前綴
<(\w+)> # 查找尖括號括起來的字母或數字(即HTML/XML標簽)
) # 前綴結束
.* # 匹配任意文本
(?= # 斷言要匹配的文本的後綴
<\/\1> # 查找尖括號括起來的內容:前面是一個"/",後面是先前捕獲的標簽
)# 後綴結束
貪婪與懶惰
當正則表達式中包含能接受重復的限定符時,通常的行為是(在使整個表達式能得到匹配的前提下)匹配盡可能多的字符。以這個表達式為例:a.*b,它將會匹配最長的以a開始,以b結束的字符串。如果用它來搜索aabab的話,它會匹配整個字符串aabab。這被稱為貪婪匹配。
有時,我們更需要懶惰匹配,也就是匹配盡可能少的字符。前面給出的限定符都可以被轉化為懶惰匹配模式,只要在它後面加上一個問號?。這樣.*?就意味著匹配任意數量的重復,但是在能使整個匹配成功的前提下使用最少的重復。現在看看懶惰版的例子吧:
a.*?b匹配最短的,以a開始,以b結束的字符串。如果把它應用於aabab的話,它會匹配aab(第一到第三個字符)和ab(第四到第五個字符)。
為什麼第一個匹配是aab(第一到第三個字符)而不是ab(第二到第三個字符)?簡單地說,因為正則表達式有另一條規則,比懶惰/貪婪規則的優先級更高:最先開始的匹配擁有最高的優先權——The match that begins earliest wins。
在C#中,你可以使用Regex(String, RegexOptions)構造函數來設置正則表達式的處理選項。如:Regex regex = new Regex(@"\ba\w{6}\b", RegexOptions.IgnoreCase);
上面介紹了幾個選項如忽略大小寫,處理多行等,這些選項能用來改變處理正則表達式的方式。下面是.Net中常用的正則表達式選項:
一個經常被問到的問題是:是不是只能同時使用多行模式和單行模式中的一種?答案是:不是。這兩個選項之間沒有任何關系,除了它們的名字比較相似(以至於讓人感到疑惑)以外。
平衡組/遞歸匹配
這裡介紹的平衡組語法是由.Net Framework支持的;其它語言/庫不一定支持這種功能,或者支持此功能但需要使用不同的語法。
有時我們需要匹配像( 100 * ( 50 + 15 ) )這樣的可嵌套的層次性結構,這時簡單地使用\(.+\)則只會匹配到最左邊的左括號和最右邊的右括號之間的內容(這裡我們討論的是貪婪模式,懶惰模式也有下面的問題)。假如原來的字符串裡的左括號和右括號出現的次數不相等,比如( 5 / ( 3 + 2 ) ) ),那我們的匹配結果裡兩者的個數也不會相等。有沒有辦法在這樣的字符串裡匹配到最長的,配對的括號之間的內容呢?
為了避免(和\(把你的大腦徹底搞糊塗,我們還是用尖括號代替圓括號吧。現在我們的問題變成了如何把xx <aa <bbb> <bbb> aa> yy這樣的字符串裡,最長的配對的尖括號內的內容捕獲出來?
這裡需要用到以下的語法構造:
(?'group') 把捕獲的內容命名為group,並壓入堆棧(Stack)
(?'-group') 從堆棧上彈出最後壓入堆棧的名為group的捕獲內容,如果堆棧本來為空,則本分組的匹配失敗
(?(group)yes|no) 如果堆棧上存在以名為group的捕獲內容的話,繼續匹配yes部分的表達式,否則繼續匹配no部分
(?!) 零寬負向先行斷言,由於沒有後綴表達式,試圖匹配總是失敗
如果你不是一個程序員(或者你自稱程序員但是不知道堆棧是什麼東西),你就這樣理解上面的三種語法吧:第一個就是在黑板上寫一個"group",第二個就是從黑板上擦掉一個"group",第三個就是看黑板上寫的還有沒有"group",如果有就繼續匹配yes部分,否則就匹配no部分。
我們需要做的是每碰到了左括號,就在壓入一個"Open",每碰到一個右括號,就彈出一個,到了最後就看看堆棧是否為空--如果不為空那就證明左括號比右括號多,那匹配就應該失敗。正則表達式引擎會進行回溯(放棄最前面或最後面的一些字符),盡量使整個表達式得到匹配。
< #最外層的左括號
[^<>]* #最外層的左括號後面的不是括號的內容
(
(
(?'Open'<) #碰到了左括號,在黑板上寫一個"Open"
[^<>]* #匹配左括號後面的不是括號的內容
)+
(
(?'-Open'>) #碰到了右括號,擦掉一個"Open"
[^<>]* #匹配右括號後面不是括號的內容
)+
)*
(?(Open)(?!)) #在遇到最外層的右括號前面,判斷黑板上還有沒有沒擦掉的"Open";如果還有,則匹配失敗
> #最外層的右括號
平衡組的一個最常見的應用就是匹配HTML,下面這個例子可以匹配嵌套的<div>標簽:<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
還有些什麼東西沒提到
上邊已經描述了構造正則表達式的大量元素,但是還有很多沒有提到的東西。下面是一些未提到的元素的列表,包含語法和簡單的說明。你可以在網上找到更詳細的參考資料來學習它們--當你需要用到它們的時候。如果你安裝了MSDN Library,你也可以在裡面找到.net下正則表達式詳細的文檔。
這裡的介紹很簡略,如果你需要更詳細的信息,而又沒有在電腦上安裝MSDN Library,可以查看關於正則表達式語言元素的MSDN在線文檔。
聯系作者
好吧,我承認,我騙了你,讀到這裡你肯定花了不止30分鐘.相信我,這是我的錯,而不是因為你太笨.我之所以說"30分鐘",是為了讓你有信心,有耐心繼續下去.既然你看到了這裡,那證明我的陰謀成功了.被忽悠的感覺很爽吧?
要投訴我,或者覺得我其實可以忽悠得更高明,或者有任何其它問題,歡迎來我的博客讓我知道。