淺析如何利用JavaScript進行語音識別
編輯:關於JavaScript
一、基礎用法
var recognition = new webkitSpeechRecognition();
recognition.onresult = function(event) {
console.log(event)
}
recognition.start();
這裡操作實際會讓用戶授權頁面開啟麥克風,如果用戶允許的話,用戶可以開始說話了,如果你停說話了,onresult注冊的時間 則會被觸發,並會講捕獲的音頻返回成一個JavaScript對象。
二、響應流
你需要等待用戶准備好對話,並且知道對話結束;
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = function(event) {
console.log(event)
}
recognition.start();
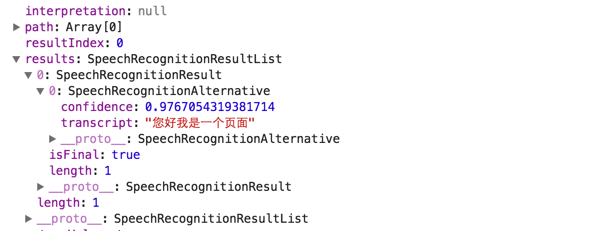
這樣你可以在用戶開始講話時,提前渲染結果。
你可以自動以識別的語言,默認情況為所在地區語言。
三、x-webkit-speech
Webkit 內核的浏覽器支持語音輸入
<input type="text" x-webkit-speech />
它會識別音頻並進行轉化為文字
四、安全性
http協議下浏覽器每次都會提醒用戶去確認語音操作,然而https的頁面,沒有這樣一個麻煩的操作。
JavaScript上下文,整個頁面,都能過訪問到捕獲的音頻。
總結
JavaScript的語音識別總體還並未大范圍使用,而且受限於浏覽器支持,因此只有少數需求或許能夠使用到吧。以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流。
小編推薦
熱門推薦