鄰近算法,或者說K最近鄰(kNN,k-NearestNeighbor)分類算法是數據挖掘分類技術中最簡單的方法之一。所謂K最近鄰,就是k個最近的鄰居的意思,說的是每個樣本都可以用它最接近的k個鄰居來代表。
kNN算法的核心思想是如果一個樣本在特征空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。 kNN方法在類別決策時,只與極少量的相鄰樣本有關。由於kNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對於類域的交叉或重疊較多的待分樣本集來說,kNN方法較其他方法更為適合。
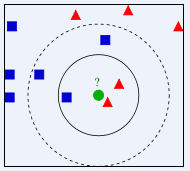
上圖中,綠色圓要被決定賦予哪個類,是紅色三角形還是藍色四方形?如果K=3,由於紅色三角形所占比例為2/3,綠色圓將被賦予紅色三角形那個類,如果K=5,由於藍色四方形比例為3/5,因此綠色圓被賦予藍色四方形類。
K最近鄰(k-Nearest Neighbor,KNN)分類算法,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。該方法的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。 KNN方法雖然從原理上也依賴於極限定理,但在類別決策時,只與極少量的相鄰樣本有關。由於KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對於類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
KNN算法不僅可以用於分類,還可以用於回歸。通過找出一個樣本的k個最近鄰居,將這些鄰居的屬性的平均值賦給該樣本,就可以得到該樣本的屬性。更有用的方法是將不同距離的鄰居對該樣本產生的影響給予不同的權值(weight),如權值與距離成反比。
用 kNN 算法預測豆瓣電影用戶的性別
摘要
本文認為不同性別的人偏好的電影類型會有所不同,因此進行了此實驗。利用較為活躍的274位豆瓣用戶最近觀看的100部電影,對其類型進行統計,以得到的37種電影類型作為屬性特征,以用戶性別作為標簽構建樣本集。使用kNN算法構建豆瓣電影用戶性別分類器,使用樣本中的90%作為訓練樣本,10%作為測試樣本,准確率可以達到81.48%。
實驗數據
本次實驗所用數據為豆瓣用戶標記的看過的電影,選取了274位豆瓣用戶最近看過的100部電影。對每個用戶的電影類型進行統計。本次實驗所用數據中共有37個電影類型,因此將這37個類型作為用戶的屬性特征,各特征的值即為用戶100部電影中該類型電影的數量。用戶的標簽為其性別,由於豆瓣沒有用戶性別信息,因此均為人工標注。
數據格式如下所示:
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
示例:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像這樣的數據一共有274行,表示274個樣本。每一個的前37個數據是該樣本的37個特征值,最後一個數據為標簽,即性別:0表示男性,1表示女性。
在此次試驗中取樣本的前10%作為測試樣本,其余作為訓練樣本。
首先對所有數據歸一化。對矩陣中的每一列求取最大值(max_j)、最小值(min_j),對矩陣中的數據X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然後對於每一條測試樣本,計算其與所有訓練樣本的歐氏距離。測試樣本i與訓練樣本j之間的距離為:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
對樣本i的所有距離從小到大排序,在前k個中選擇出現次數最多的標簽,即為樣本i的預測值。
實驗結果
首先選擇一個合適的k值。 對於k=1,3,5,7,均使用同一個測試樣本和訓練樣本,測試其正確率,結果如下表所示。
選取不同k值的正確率表
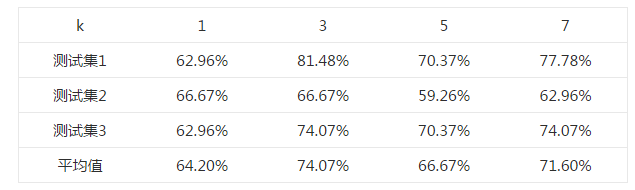
由上述結果可知,在k=3時,測試的平均正確率最高,為74.07%,最高可以達到81.48%。
上述不同的測試集均來自同一樣本集中,為隨機選取所得。
Python代碼
這段代碼並非原創,來自《機器學習實戰》(Peter Harrington,2013),並有所改動。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))