JavaScript的語法有多坑,算是眾人皆知了。
先來上張圖
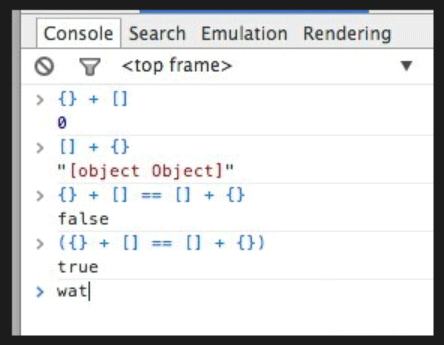
代碼如下:
復制代碼 代碼如下:
{} + []; // 0
[] + {}; // "[object Object]"
{} + [] == [] + {}; // false
({} + [] == [] + {}); // true
這麼蛋疼的語法坑估計也只有 JavaScript 這樣的奇葩才有。
相信對於絕大部分不研究 JavaScript 編譯器的童鞋,根本無法理解。(至少我也是覺得不可思議)
後來專門去度娘了一下,才有點恍然大悟!
下面,我們先看看這個代碼:
復制代碼 代碼如下:
{
a: 1
}
相信大部分童鞋,第一眼都會認為這是一個 對象直接量 。
那這個代碼呢?
復制代碼 代碼如下:
{
var a = 1;
}
浏覽器會提示語法錯誤嗎?
顯然不會!細想一下,我們就會明白到,這是一個 語句塊 。
復制代碼 代碼如下:
if (isNumber) {
var a = 1;
}
說到這裡,敏銳的你可能已經發現:JavaScript 中以 { 開頭,會存在二義性。
那 JavaScript 的編譯器是怎麼處理這個二義性的?
了解決這個問題,ECMA 的方法十分簡單粗暴:在語法解析的時候,如果一個語句以「{」開頭,就只把它解釋成語句塊。
這真心是一個坑爹的處理方式!
那既然都是語句塊,那為什麼 {a:1} 卻沒有語法錯誤?
其實在這裡,a 被解析器理解為了 標簽。標簽 是用來配合 break 和 continue 語句作定向跳轉的。
因此,這樣的寫法就會拋出異常:
復制代碼 代碼如下:
{
a: function () {}
}
因為 function () {} 不是函數聲明,也不是函數表達式。
到這裡,大家應該對 {} 的奇葩處理有了基本的概念。我們再看回文章開始所提到的幾條語句:
復制代碼 代碼如下:
{} + []; // 0
[] + {}; // "[object Object]"
{} + [] == [] + {}; // false
({} + [] == [] + {}); // true
第一條,因為 {} 是 語句塊,代碼可以理解為:
復制代碼 代碼如下:
if (1) {}
+[]
所以返回值是 0 。
第二條,由於 {} 並不在語句的開頭,所以是一個正常的 對象直接量,空數組和空對象直接相加,返回 "[object Object]" 。
理解了第一第二條,第三條已經無需解釋了。
第四條,因為是 () 開始,第一個 {} 被解析為 對象直接量 ,因而兩條公式相等,返回 true。