JavaScript是區分大小寫的:
關鍵字、變量、函數名、和所有的標識符都必須采用一致的大小寫(一般我們都是寫成小寫的),這樣和當初學C#的多樣式寫法有很大的區別。
比如:(這裡以變量str和Str為例)
復制代碼 代碼如下:
var str='abc';
var Str='ABC';
alert(str);//輸出abc
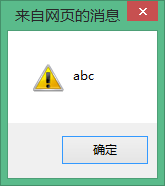
假如str與Str為同一變量,那麼alert(str);,輸出的結果應為為ABC而不是如上圖所示abc。這恰恰說明:JavaScript是區分大小寫的。
Unicode轉義序列
Unicode字符集的出現是為了彌補ASCII碼只能表示128個字符的限制,而日常中我們想顯示漢字和日文的話,顯然ASCII是不可能的了。所以說Unicode是ASCII和Latin-1的超集。首先,JavaScript程序都是用Unicode字符集編寫而成的,但在一些計算機硬件和軟件裡根本無法完整地顯示或者輸入Unicode字符全集(比如:é),為了解決這一現象JavaScript定義了一種特殊序列,這種序列使用6個ASCII字符來代表任意16位Unicode內碼,這種特殊序列統稱為Unicode轉義序列,它均以\u為前綴,其後跟隨4個十六進制數
比如:
復制代碼 代碼如下:
var str='caf\u00e9';
var Str='café';
alert(Str+' '+str);// 可以看出顯示都是一樣的效果。
alert (Str===str);//輸出true
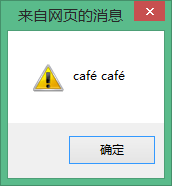
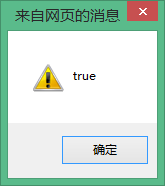
但我們應該注意一點,Unicode是允許多種方法對同一字符進行編碼的,用上述的é轉義的例子來說明:
é:
1.可以使用Unicode字符\u00E9表示
2.亦可用e\u0301(語調字符)表示
復制代碼 代碼如下:
var str='caf\u00e9';
var Str='cafe\u0301';
alert(str+' '+Str); //如下圖所示,Str和str所輸出的結果都是一樣的
alert(Str===str); //結果是一樣的,可它們的二進制編碼表示根本不一樣,所以輸出false
雖然顯示在文本編輯器上的結果是一樣的,可是它們的二進制編碼表示根本不一樣,而編程語言最終都會轉化為本地平台的計算機機械碼(二進制編碼),計算機只能通過對二進制編碼的比較才能得知結果,所以它們比較最終的結果只能是false
所以這正是 “Unicode是允許多種方法對同一字符進行編碼的”最好的解釋,因為Unicode標准為所有字符定義了一個首選的編碼格式以便於將文本轉化成統一格式的Unicode轉義序列以合適比較
再次以é為例:
比較facé與café中的é是否相同?
facé與café中的é都轉化為\u00E9或者都轉化為e\u0301,才能比較facé與café中的é