Javascript中的正則表達式
剛開始接觸正則表達式的時候,覺得這是個很死板的東西(沒辦法,計算機不能像人眼一樣能很快的辨認出我們需要的結果,它需要一定的規則來對它進行限制),了解的越多,發現這個其實很靈活,在我們好多小數據的處理上它都起著很重要的作用,下面,我們再來重新認識它。
創建正則表達式的兩種方法:
1.字面量方法
var b=/\bam\b/; alert( "i am lily".replace(b,'AM')); //i AM lily
2.構造函數方法
var reg=new RegExp(/\bis\b/);
alert("she is beautiful".replace(reg,"is not")); // she is not beautiful
正則表達式匹配模式支持的三個標志
g:global 全文搜索,不添加則搜索到第一個匹配停止;
i:ignore case 忽略大小寫,默認大小寫敏感;
m:multiple lines 多行搜索
舉例:
/*字面量方法*/
//匹配字符串中所有“at”的實例
var patten1 = /at/g;
//匹配第一個“aat”或“bat”不區分大小寫
var patten2 = /at/i;
//匹配所有以“at”結尾的3個字符的組合,不區分大小寫
var patten3 = /.at/gi;
/*構造函數方法*/
//匹配字符串中所有“at”的實例
var patten1 = new RegExp("at","g");
//匹配第一個“aat”或“bat”不區分大小寫
var patten2 = new RegExp("at","i");
//匹配所有以“at”結尾的3個字符的組合,不區分大小寫
var patten3 = new RegExp("\.at","gi");
二者間的區別:
//比較字面量方法和構建函數方法的區別
var re = null,i;
for(i=0;i<10;i++){
re = /cat/g;
re.test("catastrophe");
}
for(i=0;i<10;i++){
re = new RegExp("/cat/","g");
re.test("catastrophe");
}
在第一個循環中,即使是循環體中指定的,但是實際上只為/cat/創建了一個RegExp實例。由於實例屬性不會重置,所以在循環中再次調用test方法會失敗。 這是因為第一次調用test找到了“cat”,但是第二次調用的時候是從索引為3的字符開始的,所以就找不到它了。
在第二個循環中,因為每次迭代都會創建一個新的RegExp實例,所以每次調用test都會返回true。(後面會詳細介紹關於test方法)
補充:這個和對象的創建有點相似,因為RegExp本身及時一類特殊的對象,後面我們還會說它具有對象的一些特征。
正則表達式的基本組成
正則表達式由兩種基本字符類型組成
1.原義文本字符:代表它原來含義的字符 例如:abc、123
2.元字符:在正則表達式中有特殊意義的非字母字符 例如:\b表示匹配單詞邊界,而非\b
在正則表達式中具體特殊含義的字符:* + ? $ ^ . \ () {} []
【元字符】
\t:水平制表符;
\v:垂直制表符;
\n:換行符;
\r:回車符;
\0:空字符;
\f:換頁符;
\cX:與X對應的控制字符
正則表達式中的幾種常用類
字符類
一般情況下正則表達式一個字符對應字符串一個字符
表達式 ab\t 的含義是: 一個字母a一個字母b加一個水平制表符
可以使用元字符[]來構建一個簡單的類,所謂類是指符合某些特征的對象,一個泛指,而不是特指某個字符
表達式[abc]:把字符 a 或 b 或 c 歸為一類,表達式可以匹配這類的字符,即匹配abc中的一個
'a1b2c3d4'.replace(/[abc]/g,'字符'); "字符1字符2字符3d4"
字符類取反
使用元字符 ^ 創建 反向類/負向類,反向類的意思是:不屬於某類的內容
表達式 [^abc] 表示 不是字符a或b或c 的內容
'a1b2c3d4'.replace(/[^abc]/g,'字符'); "a字符b字符c字符字符字符"
范圍類
使用字符類匹配數字 [0123456789] 簡寫[0-9]
可以使用 [a-z] 來連接兩個字符表示 從a到z的任意字符,閉區間,包含a和z本身
如:
'a1b2c3zx4z9'.replace(/[a-z]/g,'Q'); "Q1Q2Q3QQ4Q9"
在[]組成的類內部是可以連寫的 [a-zA-Z]
如:
'a1b2c3zx4z9ADG'.replace(/[a-zA-Z]/g,'Q'); "Q1Q2Q3QQ4Q9QQQ"
注意:
當-在兩個字符之間,表示范圍,想匹配-,直接在後面加-即可
'2016-08-08'.replace(/[0-9-]/g,'Q'); "QQQQQQQQQQ"
預定義類
\D 等價於 [^0-9] 非數字字符
\s 等價於 [\t\n\x0B\f\r] 空白符 s:space
\S 等價於 [^\t\n\x0B\f\r] 非空白符
\w 等價於 [a-zA-Z_0-9] 單詞字符(字母、數字下劃線) w:word
\W 等價於 [^a-zA-Z_0-9] 非單詞字符
提示:大寫的表示取反
\b 單詞邊界
\B非單詞邊界
例子:
1. '@123@abc@'.replace(/^@./g,'Q'); "Q23@abc@" 2.'@123@abc@'.replace(/.@$/g,'Q'); "@123@abQ" 3.'@123@abc@'.replace(/.@/g,'Q'); "@12QabQ"
量詞
? 出現0次或者一次,最多出現一次。。
+ 出現一次或者多次,至少出現一次。。
* 出現零次或者多次 可以是任意次數。。
{n} 出現了n次。
{n,m} 出現了n到m次。。
{n,} 至少出現n次。
如果要表示最多10次,則用{0,10}
貪婪模式和非貪婪模式
貪婪模式(默認)
正則表達式在匹配時,盡可能多的匹配,直到匹配失敗
'1234568'.replace(/\d{3,6}/g,'Q');
"Q8"
非貪婪模式
正則表達式盡可能少的匹配,即一旦成功匹配就不再繼續匹配
做法:在量詞後加上 ? 即可,例子:
'123456789'.match(/\d{3,5}?/g)
["123", "456", "789"]
分組
匹配字符串 Byron 連續出現 3 此的場景
1. 使用()可以達到分組的功能,使量詞作用於分組 (Byron){3},如果直接Byron{3}則匹配到的三Byronnn
例子:小寫字母連續出現3次
'a1b2c3d4'.replace(/([a-z]\d){3}/g,'Q');
//"Qd4"
2. 使用 將正則表達式分成前後兩部分,可以達到 或 的效果isIS ByronCasper Byr(onCa)sper,例子:
'ByronCasper'.replace(/ByronCasper/g,'Q'); //"Q" 'ByrCasperByronsper'.replace(/Byr(onCa)sper/g,'Q'); //"QQ"
3.反向引用
2015-12-25 => 12/25/2015
在分組的基礎上,分組取值使用'$1 $2....'代表捕獲分組內容,實現:
'2015-09-09'.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$2/$3/$1');
//"09/09/2015"
忽略分組
不希望捕獲某些分組,只需要在分組內加上 ?:即可
(?:Byron).(ok)
'2016-10-06'.replace(/(?:\d{4})-(\d{2})-(\d{2})/g,'$2/$3/$1');
//"06/$3/10"
前瞻
正則表達式從文本頭部向尾部開始解析,文本尾部方向,成為“前”
前瞻 就是在正則表達式匹配到規則的時候,向前檢查是否符合斷言。比如找到兒子為張三,還得看看他的父親是否是李四
後顧/後瞻方向相反,注意:JavaScript不支持後顧
符合特定斷言稱為 肯定/正向 匹配
不符合特定斷言稱為 否定/負向 匹配
正向前瞻 exp(?=assert) 先判斷是否符合正則,再符合正則的基礎上判斷是否符合斷言
負向前瞻 exp(?!asseret)
例如:
\w(?=\d) 正向前瞻 符合斷言 匹配單詞字符,要求首先是一個單詞,並且這個單詞符合斷言,後跟一個數字 'a2*3'.replace(/\w(?=\d)/g,'A') "A2*3" 'a2*3bb'.replace(/\w(?=\d)/g,'A') "A2*3bb"
RegExp實例屬性
global:是否全文搜索,默認false
ignore case:是否大小寫敏感,默認是false
multiline:多行搜索,默認值是false
lastIndex:是當前表達式匹配內容的最後一個字符的下一個位置
source:正則表達式的文本字符串
注意: 實例屬性是不可以修改的
var pattern1 = /\[bc\]at/;
console.log(pattern1.global); //false
console.log(pattern1.ignoreCase); //false
console.log(pattern1.multiline); //false
console.log(pattern1.lastIndex); //0
console.log(pattern1.source); //\[bc\]at
var pattern2 = new RegExp("\\[bc\\]at","i")
console.log(pattern2.global); //false
console.log(pattern2.ignoreCase); //true
console.log(pattern2.multiline); //false
console.log(pattern2.lastIndex); //0
console.log(pattern2.source); //\[bc\]at
正則表達式本身的兩個方法
1.test方法
RegExp.prototype.test(str)
它接受一個字符串參數,用於測試字符串參數中是否存在匹配正則表達式模式的字符串,如果存在則返回true,否則返回false
例子:
var text = "0000-00-00";
var pattern = /\d{4}-\d{2}-\d{2}/;
if(pattern.test(text)){
console.log("the pattern was matched");//the pattern was matched
}
多次執行test()方法,會在true、false之間循環
(/\w/g).test('a')每次執行都是正確的,但是通過實例化對象,需要很大的開銷
test()方法:原意就是測試有沒有、能不能匹配上,當使用test原意時,沒必要加g
2.exec方法
RegExp.prototype.exec(str)
使用正則表達式模式對字符串執行搜索,並將更新全局RegExp對象的屬性一反映匹配結果
如果沒有匹配的文本則返回 null,否則返回一個結果數組:
- index 聲明匹配文本的第一個字符位置
- input 存放被檢索的字符串 string
vra text = "mom and dad and baby"; var pattern = /mom( and dad( and baby)?)?/gi; var matches = pattern.exec(text); console.log(matches.index); //0 console.log(matches.input); //"mom and dad and baby" console.log(matches[0]); //"mom and dad and baby" console.log(matches[1]); //" and dad and baby" console.log(matches[2]); //" and baby"
再如:
var text = "cat, bat, dat, eat"; var pattern1 = /.at/g; var matches = pattern1.exec(text); console.log(matches.index); //0 console.log(matches[0]); //cat console.log(matches.lastIndex); //undefined,(理論上上是3) matches = pattern1.exec(text); console.log(matches.index); //5 console.log(matches[0]); //bat console.log(matches.lastIndex); //undefined,(理論上上是8) var pattern2 = /.at/; var matches = pattern2.exec(text); console.log(matches.index); //0 console.log(matches[0]); //cat console.log(matches.lastIndex); //undefined,(理論上上是0) matches = pattern2.exec(text); console.log(matches.index); //0 console.log(matches[0]); //cat console.log(matches.lastIndex); //undefined,(理論上上是0)
lastIndex 記錄當前匹配結果的、最後一個字符的、下一個字符的位置
注意:test()方法在匹配的時候當匹配到一個結果時,會從lastIndex位置開始匹配下一個結果,直到不存在的時候才置為0。因此,當使用全局g屬性標識時,當匹配到最後一個結果時,lastIndex值指向不存在的位置,此時再執行test()會返回false。
非全局調用
調用非全局的RegExp對象的 exec()時,返回數組
第一個元素是與正則表達式相匹配的文本
第二個元素是與RegExpObject的第一個子表達式相匹配的文本(如果有的話)
第三個元素是與RegExp對象的第二個子表達式相匹配的文本(如果有的話),以此類推
字符串對象方法
1.search
String.prototype.search(reg)
search()方法用於檢索字符串中指定的子字符串,或檢索與正則表達式相匹配的子字符串
方法返回第一個匹配結果 index,查找不到返回 -1
search()並不執行全局匹配,它將忽略標志 g ,並且總是從字符串的開始進行檢索
例子:
'A11B2C3D4'.search(/\d/) //1
2.match
String.prototype.match(reg)
match()方法將檢索字符串,以找到一個或多個與RegExp匹配的文本
RegExp是否具有標志 g 對結果影響跟大
非全局調用,即沒有 g
如果RegExp沒有標志 g,那麼 match()方法就只能在字符串中執行一次匹配
如果沒有找到任何匹配的文本,將返回null
否則它將返回一個數組,其中存放了與它找到的匹配文本有關的信息
返回數組的第一個元素存放的是匹配文本,而其余的元素存放的是與正則表達式的子表達式匹配的文本
除了常規的數組元素之外,返回的數組還含有2個對象屬性
index 聲明匹配文本的起始字符在字符串的位置
input 聲明對 stringObject的引用
全局調用
如果RegExp具有標志 g,則match()方法將執行全局檢索,找到字符串中的所有匹配子字符串
沒有找到任何匹配的子串,則返回null
如果找到了一個或多個匹配的子串,則返回一個數組
數組元素中存放地字符串中所有的匹配子串,而且也沒有index 屬性或input屬性
var str = 'abc123def456ghi789'; var re = /\d+/g; // 每次匹配至少一個數字 且全局匹配 如果不是全局匹配,當找到數字123,它就會停止了。就只會彈出123.加上全局匹配,就會從開始到結束一直去搜索符合規則的。 console.log( str.match(re) ); // [123,456,789] //如果沒有加號,匹配的結果就是1,2,3,5,4,3,3,8,7,9並不是我們想要的,有了加號,每次匹配的數字就是至少一個了。
3.replace
String.prototype.replace(str,replaceStr)
String.prototype.replace(reg,replaceStr)
String.prototype.replace(reg,function)
function參數含義
function會在每次匹配替換的時候調用,有四個參數
匹配字符串
正則表達式分組內容,沒有分組則沒有該參數
匹配項在字符串中 index
原字符串
var str = "鋤禾日當午,汗滴禾下土。"; var re = /日當午|汗滴/g; // 找到日當午 或者汗滴 全局匹配 var str2 = str.replace(re,'*'); console.log(str2) //鋤禾*,*禾下土。 //這種只是把找到的變成了一個*,並不能幾個字就對應幾個*。
想要把每個漢字都變成*,我們可以用如下辦法:
var str = "鋤禾日當午,汗滴禾下土。";
var re = /日當午|汗滴/g; // 找到日當午 或者汗滴全局匹配
var str2 = str.replace(re,function(str){
console.log(str); //用來測試:函數的第一個參數代表每次搜索到的符合正則的字符,所以第一次str指的是鋤禾 第二次str是日當午 第三次str是汗滴"
var result = '';
for(var i=0;i<str.length;i++){
result += '*';
}
return result; //所以搜索到了幾個字就返回幾個*
});
console.log(str2) //鋤禾***,**禾下土。
例子:將2016-10-06變為2016.10.06,代碼如下
var str = '2016-10-06';
var re = /(\d+)(-)/g;
str = str.replace(re,function($0,$1,$2){
//replace()中如果有子項,
//第一個參數:$0(匹配成功後的整體結果 2016- 10-),
// 第二個參數 : $1(匹配成功的第一個分組,這裡指的是\d 2016, 10)
//第三個參數 : $1(匹配成功的第二個分組,這裡指的是- - - )
return $1 + '.'; //分別返回2016. 10.
});
alert( str ); //2016.10.06
正則表達式的一些特別用法
1、找重復項最多的字符個數
var str = 'assssjdssskssalsssdkjsssdss';
var arr = str.split(''); //把字符串轉換為數組
str = arr.sort().join(''); //首先進行排序,這樣結果會把相同的字符放在一起,然後再轉換為字符串
//alert(str); // aaddjjkklsssssssssssssssss
var value = '';
var index = 0;
var re = /(\w)\1+/g; //匹配字符,且重復這個字符,重復次數至少一次。
str.replace(re,function($0,$1){
//alert($0); 代表每次匹配成功的結果 : aa dd jj kk l sssssssssssssssss
//alert($1); 代表每次匹配成功的第一個子項,也就是\w: a d j k l S
if(index<$0.length){ //如果index保存的值小於$0的長度就進行下面的操作
index = $0.length; // 這樣index一直保存的就在最大的長度
value = $1; //value保存的是出現最多的這個字符
}
});
alert('最多的字符:'+value+',重復的次數:'+index); // s 17
2、去掉前後空格
var str = ' hello ';
console.log(str); // hello
alert( '('+trim(str)+')' );//為了看出區別所以加的括號。 (hello)
function trim(str){
var re = /^\s+|\s+$/g; // |代表或者 \s代表空格 +至少一個 前面有至少一個空格 或者後面有至少一個空格 且全局匹配
return str.replace(re,''); //把空格替換成空
}
3、其他
還有很多正則表達式的用法,主要在表單驗證上。比如說手機號碼驗證,身份證號碼驗證,郵箱驗證等。在這裡,推薦兩個比較實用的網站:
正則表達式調試工具:http://www1.w3cfuns.com/tools.php?mod=regex
正則表達式結構分析工具:https://regexper.com/#%2F%5E%5B1-9%5D%5Cd*%24%2F
在正則表達式調試工具中,我們能調試我們想要的結果,在旁邊還附有幫助文檔,能幫助我們很好的使用;而結構分析工具能幫助我們更好的分析其中的結構。以電話號碼的匹配為例
在調試工具中我們查看常用規則,點擊手機,得到如下效果: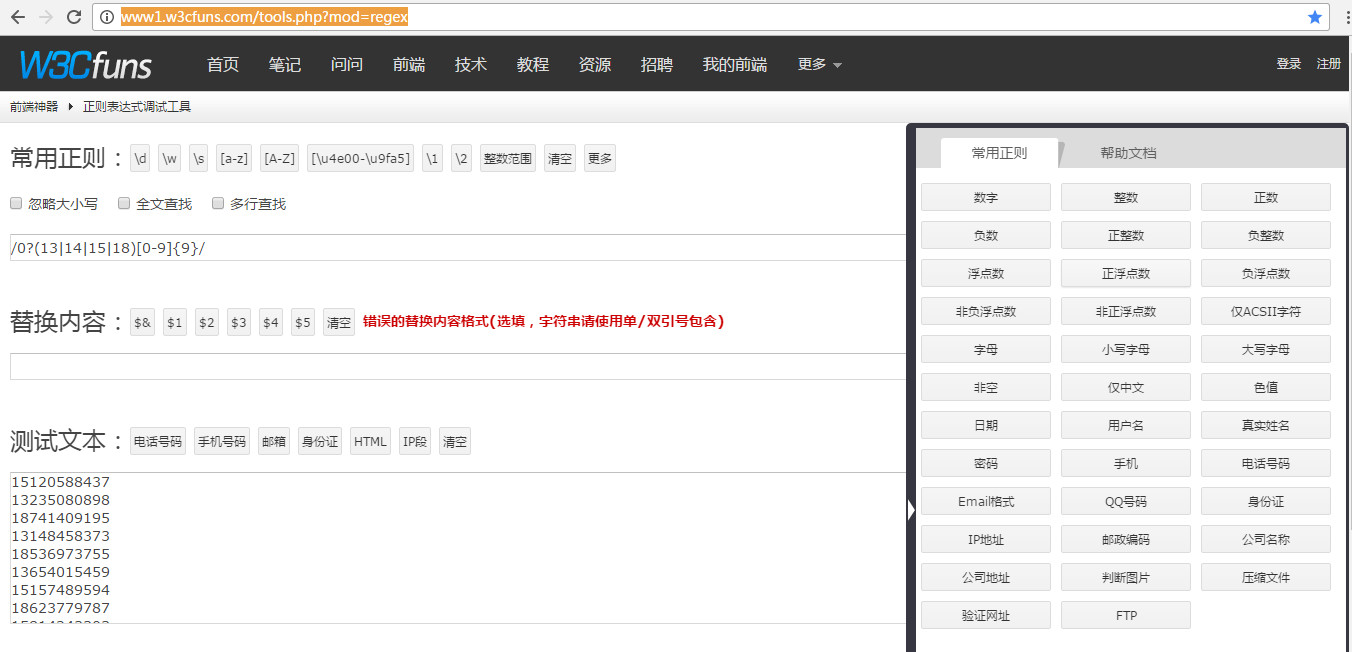 在解析工具中我們可以根據結果分析它的結構,效果如圖:
在解析工具中我們可以根據結果分析它的結構,效果如圖: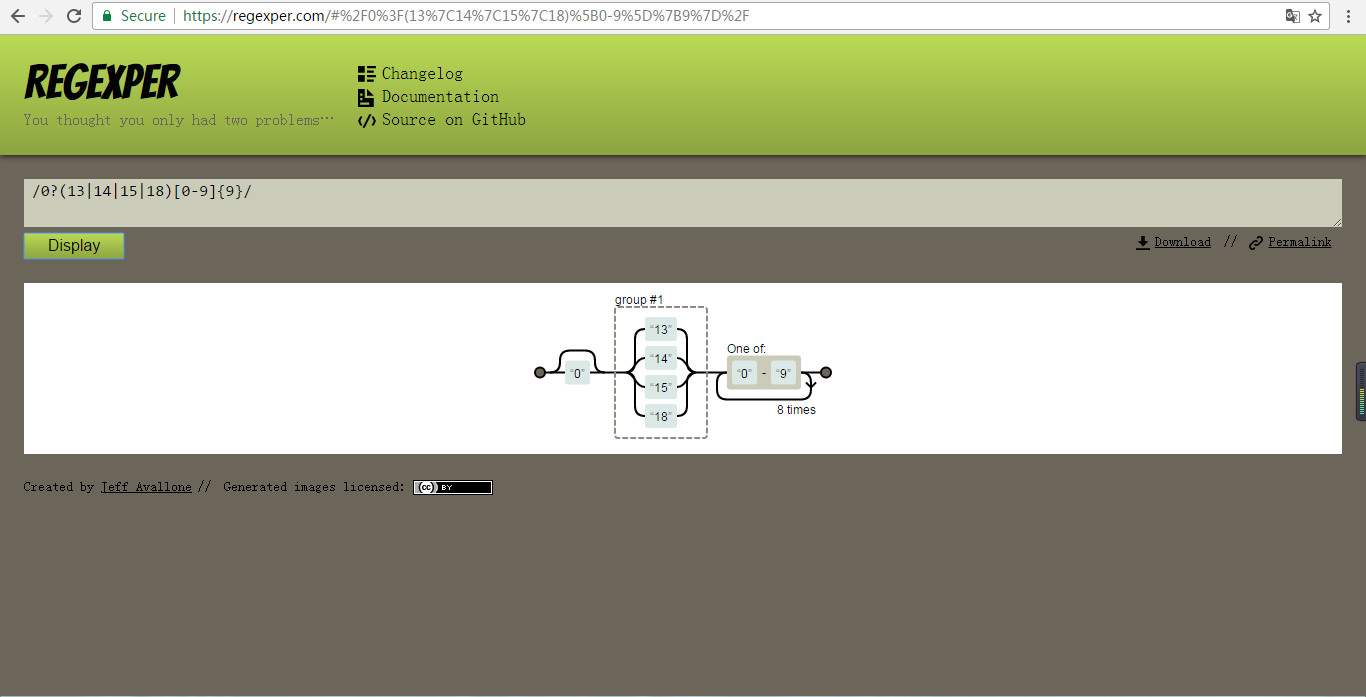 剛開始學習的時候可以多借助工具,奪取分析結構,比較幾個常用正則表達式的區別,然後進行歸納。
剛開始學習的時候可以多借助工具,奪取分析結構,比較幾個常用正則表達式的區別,然後進行歸納。
補充:RegExp實例繼承的toLocaleString()和toString()方法都會返回正則表達式的面向字面量,與創建的表達式無關。
var reg = new RegExp("\\[bc\\]at","g");
console.log(reg.toLocaleString());
console.log(reg.toString());
var reg = /\[bc\]at/g;
console.log(reg.toLocaleString());
console.log(reg.toString())
輸出的結果都為:/\[bc\]at/g