本文示例源代碼或素材下載
開始之前
這一節介紹本教程的主要內容以及如何充分利用它。
關於本系列
本系列教程 分為五部分,幫助您准備參加 IBM 認證考試 142(XML and Related Technologies),通過 IBM Certified Solution Developer - XML and Related TechnologIEs 認證。通過該認證表明達到了中級開發人員的水平,能夠使用 XML 及相關技術設計和實現應用程序,比如 XML Schema、可擴展樣式表語言轉換(XSLT)和 XPath。這些開發人員對 XML 基礎有深刻的理解;清楚 XML 概念和相關技術;了解數據和 XML 的關系,特別適合信息建模、XML 處理、XML 呈現以及與 Web 服務有關的問題;對核心的、與 XML 有關的萬維網聯盟(W3C)推薦標准了然於心,熟悉常見的最佳實踐。
在過去幾年中從事軟件開發的任何人都知道,XML 為數據 提供了跨平台能力,就像 Java® 編程語言為應用程序邏輯提供跨平台能力一樣。本系列教程適合於希望在使用 XML 技術方面超越入門階段的任何人。
關於本教程
本教程是 “准備 XML 及相關技術認證” 系列的第三部分,該系列教程介紹了在 Java 項目中有效使用 XML 技術的各個重要方面。第三期教程主要討論 XML 處理,即如何解析和驗證 XML 文檔。本教程主要討論轉換,包括 XSLT、XPath 和級聯樣式表(CSS)的使用,為第 4 部分做好鋪墊。
本教程是為那些對 XML 有基本的了解、技能和經驗接近中級水平的 Java 程序員編寫的。讀者應該比較熟悉 XML 文檔的定義、驗證和讀取,並有使用 Java 語言的實際經驗。
目標
學完本教程後讀者應該能夠:
使用 Simple API for XML 2(SAX2)和文檔對象模型 2(DOM2)解析器解析 XML 文檔
用文檔類型定義(DTD)和 XML Schemas 驗證 XML 文檔
使用 XQuery 從數據庫中訪問 XML 內容
前提條件
本教程是為那些具有編程和腳本背景,了解計算機科學基本模型和數據結構的開發人員編寫的。您應該熟悉下列與 XML 有關的計算機科學概念:樹遍歷、遞歸和數據重用。應該熟悉 Internet 標准和概念,比如 Web 浏覽器、客戶機-服務器、文檔化、格式化、電子商務和 Web 應用程序。最後,具有設計和實現基於 Java 的計算機應用程序和使用關系數據庫的經驗。
系統需求
要運行本教程中的例子,需要 Linux® 或 Microsoft® Windows® 操作系統,至少 50MB 空閒空間和安裝軟件的管理權限。本教程使用了(但不是必需的)下列軟件:
Java 軟件開發工具箱(JDK) 1.4.2 或更高版本
Eclipse 3.1 或更高版本
XMLBuddy 2.0 或更高版本(注意:本系列教程的部分內容使用了 XMLBuddy Pro 的功能,該版本不是免費的。)
解析 XML 文檔
解析 XML 文檔有多種方式(請參閱本系列的第 1 部分,那篇教程討論了體系結構),不過 SAX 解析器和 DOM 解析器是最基本的。第 1 部分從較高層次上比較了這兩種方法。
XML 實例文檔
本教程使用一個 DVD 商店的庫存目錄作為示例文檔。從概念上說,目錄是 DVD 以及關於每個 DVD 的信息的集合。實際的文檔很短,只有四張 DVD,但是對於學習 XML 處理(包括驗證)而言已經足夠復雜了。清單 1 顯示了該文件。
清單 1. DVD 目錄的 XML 實例文檔
<?XML version="1.0"?>
<!DOCTYPE catalog SYSTEM "dvd.dtd">
<!-- DVD inventory -->
<catalog>
<dvd code="_1234567">
<title>Terminator 2</title>
<description>
A shape-shifting cyborg is sent back from the future
to kill the leader of the resistance.
</description>
<price>19.95</price>
<year>1991</year>
</dvd>
<dvd code="_7654321">
<title>The Matrix</title>
<price>12.95</price>
<year>1999</year>
</dvd>
<dvd code="_2255577" genre="Drama">
<title>Life as a House</title>
<description>
When a man is diagnosed with terminal cancer,
he takes custody of his misanthropic teenage son.
</description>
<price>15.95</price>
<year>2001</year>
</dvd>
<dvd code="_7755522" genre="Action">
<title>Raiders of the Lost Ark</title>
<price>14.95</price>
<year>1981</year>
</dvd>
</catalog>
使用 SAX 解析器
本系列教程的第 1 部分已經討論過,SAX 解析器是一種基於事件的解析器。這意味著,解析器在解析文檔的時候向回調方法發送事件(如 圖 1 所示)。為了簡化起見,圖 1 中沒有顯示發生的所有事件。
圖 1. SAX 解析器事件
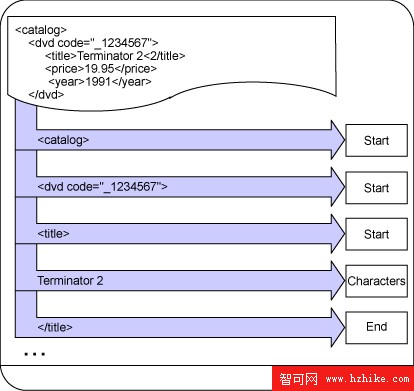
隨著解析器讀入文檔內容,這些事件被實時地推給應用程序。這種處理模型的好處是可以用相對較少的內存處理很大的文檔。缺點是處理所有這些事件要做更多的工作。
org.xml.sax 包提供了一組接口。其中之一提供了解析器的 XMLReader 接口。可以這樣建立解析:
try {
XMLReader parser = XMLReaderFactory.createXMLReader();
parser.parse( "myDocument.XML" ); //complete path
} catch ( SAXParseException e ) {
//document is not well-formed
} catch ( SAXException e ) {
//could not find an implementation of XMLReader
} catch ( IOException e ) {
//problem reading document file
}
技巧:重用解析器實例是可能的。創建解析器需要大量資源。如果運行多個線程,可以從資源池中重用解析器實例。
這樣當然好,但是應用程序如何從解析器得到事件呢?很高興您能問這個問題。
處理 SAX 事件
為了從解析器接收事件,需要實現 ContentHandler 接口。可以實現該接口的很多方法以便處理文檔。或者,如果只需要處理一兩個回調,也可以實現 DefaultHandler 的子類,該類實現了所有 ContentHandler 方法(什麼也不做),然後覆蓋需要的方法。
無論哪種方式,都要編寫邏輯,從而在收到 startElement、characters、endDocument 和 SAX 解析器激活的其他回調方法時進行所需要的處理。XML in a Nutshell, Third Edition(請參閱 參考資料)的第 351-355 頁列出了文檔中可能出現的所有方法調用。
這些回調事件是文檔解析過程中的正常 事件。還可以實現 ErrorHandler 來處理有效性 回調。介紹有效性之後我再討論這個話題,暫時先放一放。
要進一步了解 SAX 解析,請閱讀 XML in a Nutshell, Third Edition 的第 20 章或者 “Serial Access with the Simple API for XML (SAX)”(請參閱 參考資料)。
SAX 解析器異常處理
在默認情況下,SAX 解析器忽略錯誤。為了應付無效的或者非結構良好的文檔,必須實現 ErrorHandler(要注意,DefaultHandler 同時實現了該接口和 ContentHandler 接口)並定義 error() 方法:
public class SAXEcho extends DefaultHandler {
...
//Handle validity errors
public void error( SAXParseException e ) {
echo( e.getMessage() );
echo( "Line " + e.getLineNumber() +
" Column " + e.getColumnNumber();
}
然後必須打開驗證特性:
parser.setFeature( "http://XML.org/sax/features/validation", true );
最後調用下列代碼:
parser.setErrorHandler( saxEcho );
要記住,parser 是 XMLReader 的一個實例。如果文檔違反了模式(DTD 或 XML Schema)規則,解析器就會調用 error() 方法。
回顯 SAX 事件
作為上面所學 SAX 解析器應用技巧的一個練習,使用 清單 2 中的 SAXEcho.Java 代碼輸出 catalog.XML 文件的解析器事件。
清單 2. 回顯 SAX 事件
package com.XML.tutorial;
import Java.io.IOException;
import Java.io.OutputStreamWriter;
import Java.io.Writer;
import org.XML.sax.Attributes;
import org.XML.sax.SAXException;
import org.XML.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.XML.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
/**
* A handler for SAX parser events that outputs certain event
* information to standard output.
*
* @author mlorenz
*/
public class SAXEcho extends DefaultHandler {
public static final String XML_DOCUMENT_DTD = "catalogDTD.XML";
//validates via catalog.dtd
public static final String XML_DOCUMENT_XSD = "catalogXSD.XML";
//validates via catalog.xsd
public static final String NEW_LINE = System.getProperty("line.separator");
protected static Writer writer;
/**
* Constructor
*/
public SAXEcho() {
super();
}
/**
* @param args
*/
public static void main(String[] args) {
//-- Set up my instance to handle SAX events
DefaultHandler eventHandler = new SAXEcho();
//-- Echo to standard output
writer = new OutputStreamWriter( System.out );
try {
//-- Create a SAX parser
XMLReader parser = XMLReaderFactory.createXMLReader();
parser.setContentHandler( eventHandler );
parser.setErrorHandler( eventHandler );
parser.setFeature(
"http://XML.org/sax/features/validation", true );
//-- Validation via DTD --
echo( "=== Parsing " + XML_DOCUMENT_DTD + " ===" + NEW_LINE );
//-- Parse my XML document, reporting DTD-related errors
parser.parse( XML_DOCUMENT_DTD );
//-- Validation via XSD --
parser.setFeature(
"http://apache.org/XML/features/validation/schema",
true );
echo( NEW_LINE + NEW_LINE + "=== Parsing " +
XML_DOCUMENT_XSD + " ===" + NEW_LINE );
//-- Parse my XML document, reporting XSD-related errors
parser.parse( XML_DOCUMENT_XSD );
} catch (SAXException e) {
System.out.println( "Parsing Exception occurred" );
e.printStackTrace();
} catch (IOException e) {
System.out.println( "Could not read the file" );
e.printStackTrace();
}
System.exit(0);
}
//--Implement SAX callback events of interest (default is do nothing) --
/* (non-Javadoc)
* @see org.XML.sax.helpers.DefaultHandler#startElement(Java.lang.String,
* java.lang.String, Java.lang.String, org.XML.sax.Attributes)
* @see org.XML.sax.ContentHandler interface
* Element and its attributes
*/
@Override
public void startElement( String uri,
String localName,
String qName,
Attributes attributes)
throws SAXException {
if( localName.length() == 0 )
echo( "<" + qName );
else
echo( "<" + localName );
if( attributes != null ) {
for( int i=0; i < attributes.getLength(); i++ ) {
if( attributes.getLocalName(i).length() == 0 ) {
echo( " " + attributes.getQName(i) +
"="" + attributes.getValue(i) + """ );
}
}
}
echo( ">" );
}
/* (non-Javadoc)
* @see org.XML.sax.helpers.DefaultHandler#endElement(Java.lang.String,
* java.lang.String, Java.lang.String)
* End tag
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
echo( "</" + qName + ">" );
}
/* (non-Javadoc)
* @see org.XML.sax.helpers.DefaultHandler#characters(char[], int, int)
* Character data inside an element
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String s = new String(ch, start, length);
echo(s);
}
//-- Add additional event echoing at your discretion --
/**
* Output aString to standard output
* @param aString
*/
protected static void echo( String aString ) {
try {
writer.write( aString );
writer.flush();
} catch (IOException e) {
System.out.println( "I/O error during echo()" );
e.printStackTrace();
}
}
/* (non-Javadoc)
* @see org.xml.sax.helpers.DefaultHandler#error(org.XML.sax.SAXParseException)
* @see org.XML.sax.ErrorHandler interface
*/
@Override
public void error(SAXParseException e) throws SAXException {
echo( NEW_LINE + "*** Failed validation ***" + NEW_LINE );
super.error(e);
echo( "* " + e.getMessage() + NEW_LINE +
"* Line " + e.getLineNumber() +
" Column " + e.getColumnNumber() + NEW_LINE +
"*************************" + NEW_LINE );
try {
Thread.sleep( 10 );
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
}
可以利用 SAXEcho.Java 中的代碼觀察 SAX 解析是如何進行的。要注意,這段代碼沒有處理所有的事件,因此並非原始文檔中的所有事件都回顯出來(請參閱 清單 3)。觀察 ContentHandler 接口了解可能遇到的其他消息。
清單 3. 執行 SAXEcho 的輸出
=== Parsing catalogDTD.XML ===
<catalog><dvd><title>Terminator 2</title><description>
A shape-shifting cyborg is sent back from the future to kill the leader of the resistance.
|-------10--------20--------30--------40--------50--------60--------70--------80--------9|
|-------- XML error: The previous line is longer than the max of 90 characters ---------|
</description><price>19.95</price><year>1991</year></dvd><dvd><title>The Matrix</title><price>10.95</price>
|-------10--------20--------30--------40--------50--------60--------70--------80--------9|
|-------- XML error: The previous line is longer than the max of 90 characters ---------|
<year>1999</year></dvd><dvd><title>Life as a House</title><description> When a man is diagnosed with terminal cancer, he takes custody of his misanthropic teenage son.
|-------10--------20--------30--------40--------50--------60--------70--------80--------9|
|-------- XML error: The previous line is longer than the max of 90 characters ---------|
</description><price>15.95</price><year>2001</year></dvd><dvd><title>Raiders of the Lost Ark</title><price>
|-------10--------20--------30--------40--------50--------60--------70--------80--------9|
|-------- XML error: The previous line is longer than the max of 90 characters ---------|
14.95</price><year>1981</year></dvd></catalog>
=== Parsing catalogXSD.XML ===
<catalog>
<dvd>
<title>Terminator 2</title>
<description>
A shape-shifting cyborg is sent back from the future to kill the leader of the resistance.
|-------10--------20--------30--------40--------50--------60--------70--------80--------9|
|-------- XML error: The previous line is longer than the max of 90 characters ---------|
</description>
<price>19.95</price>
<year>1991</year>
</dvd>
<dvd>
<title>The Matrix</title>
<price>10.95</price>
<year>1999</year>
</dvd>
<dvd>
<title>Life as a House</title>
<description>
When a man is diagnosed with terminal cancer,
he takes custody of his misanthropic teenage son.
</description>
<price>15.95</price>
<year>2001</year>
</dvd>
<dvd>
<title>Raiders of the Lost Ark</title>
<price>14.95</price>
<year>1981</year>
</dvd>
</catalog>
使用 DOM 解析器
和 SAX 解析器不同,DOM 解析器根據 XML 文檔內容創建樹結構(如 圖 2 所示)。為了簡化起見,部分解析動作沒有顯示出來。
圖 2. DOM 解析樹
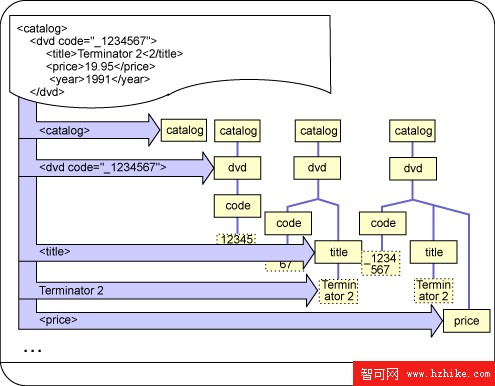
DOM 沒有為 XML 解析器指定接口,因此不同的廠商有不同的解析器類。我將繼續使用 Xerces 解析器,它包含一個 DOMParser 類。
可以像下面這樣建立 DOM 解析器:
DOMParser parser = new DOMParser();
try {
parser.parse( "myDocument.XML" );
Document document = parser.getDocument();
} catch (DOMException e) {
// take validity action here
} catch (SAXException e) {
// well-formedness action here
} catch (IOException e) {
// take I/O action here
}
遍歷 DOM 樹
由於要構造整個文檔樹,DOM 需要更多的時間和內存。這些開銷的好處是可以利用樹結構通過多種方式遍歷和操縱文檔的內容。圖 3 顯示了 DVD catalog 文檔的一部分。
圖 3. 遍歷 DOM 樹
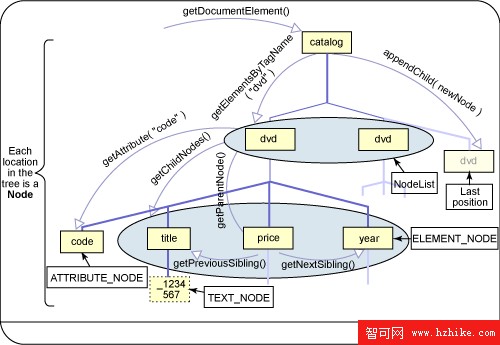
樹有一個根,可以通過 Document.getDocumentElement() 方法來訪問它。從任何 Node 出發,都可使用 Node.getChildNodes() 獲得當前 Node 的所有孩子的 NodeList。要注意,屬性不 被看作包含它的 Node 的孩子。可以創建新的 Node、追加、插入、按名查找和刪除節點。這些還僅僅是所有功能的一小部分。
一個更強大的方法是 Document.getElementsByTagName(),它返回一個 NodeList,包含後代元素中與 Node 匹配的所有孩子。DOM 既可在客戶機上使用,也可在服務器上使用。
客戶機遍歷
可以在客戶機上遍歷 DOM 樹,而且可以在浏覽器中通過 JavaScript 驗證 XHtml 頁面上的動作。比如,客戶機可能需要確定是否存在特定名稱的 Node:
//-- make sure a new DVD's title is unique
var titles = document.getElementsByTagName("title");
var newTitleValue = newTitle.getNodeValue();
var nextTitle;
for( i=0; i < titles.getLength(); i++ ) {
nextTitle = titles.item(i); //NodeList Access by index
if( nextTitle.getNodeValue().equals( newTitleValue ) {
//take some action
}
}
服務器遍歷
在服務器上肯定會需要操縱樹,比如在一個 Node 中增加新的孩子:
//-- add a new DVD with aName and description
public void createNewDvd( String aName, String description ) {
Element catalog = document.getDocumentElement(); //root
Element newDvd = document.createElement( aName );
Element dvdDescription =
document.createTextNode( description );
newDvd.appendChild( dvdDescription );
catalog.appendChild( newDvd ); //as last element
}
忠告: 一定要使用 DOM 接口,如 NodeList 或 NamedNodeMap 來操縱樹。DOM 樹是動態的,就是說隨著所做的修改立刻更新,因此如果使用本地變量,緩沖的數據有可能是錯誤的。比如,在調用 removeChild() 之後, Node.getLength() 將返回不同的值。
DOM 解析器異常處理
如果在解析過程中遇到問題,DOM 解析器將拋出 DOMException。這是一種 RuntimeException,雖然有些語言不支持檢查異常,但在 Java 代碼中應該始終捕獲並拋出異常。
為了確定操作中出現的問題,應該使用 DOMException 的 code。這些 code 說明什麼地方出現了問題,比如嘗試的修改使文檔變得無效(DOMException.INVALID_MODIFICATION_ERR)或者找不到目標 Node(DOMException.NOT_FOUND_ERR)。Processing XML with Java: A Guide to SAX, DOM, JDOM, JAXP, and TrAX 第 9 章的 DOMException 一節提供了完整的 DOMException code 列表,包括有關說明。
回顯 DOM 樹
作為上面所學 DOM 解析器使用技巧的一個練習,可以使用 清單 4 中的 DOMEcho.Java 代碼輸出 catalog.XML 文件 DOM 樹的內容。這段代碼回顯樹的信息,然後修改並回顯更新後的樹。
清單 4. 回顯 DOM 樹
package com.XML.tutorial;
import Java.io.IOException;
import Java.io.OutputStreamWriter;
import Java.io.Writer;
import org.w3c.dom.DOMException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.TreeWalker;
import org.XML.sax.SAXException;
import com.sun.org.apache.xerces.internal.parsers.DOMParser;
/**
* A handler to output certain information about a DOM tree
* to standard output.
*
* @author lorenzm
*/
public class DOMEcho {
public static final String XML_DOCUMENT_DTD =
"catalogDTD.XML"; //validates via catalog.dtd
public static final String NEW_LINE = System.getProperty("line.separator");
protected static Writer writer;
// Types of DOM nodes, indexed by nodeType value (e.g. Attr = 2)
protected static final String[] nodeTypeNames = {
"none", //0
"Element", //1
"Attr", //2
"Text", //3
"CDATA", //4
"EntityRef", //5
"Entity", //6
"ProcInstr", //7
"Comment", //8
"Document", //9
"DocType", //10
"DocFragment", //11
"Notation", //12
};
//-- DOMImplementation features (we only need one for now)
protected static final String TRAVERSAL_FEATURE = "Traversal";
//-- DOM versions (we're using DOM2)
protected static final String DOM_2 = "2.0";
/**
* Constructor
*/
public DOMEcho() {
super();
}
/**
* @param args
*/
public static void main(String[] args) {
//Echo to standard output
writer = new OutputStreamWriter( System.out );
//use the Xerces parser
try {
DOMParser parser = new DOMParser();
parser.setFeature( "http://XML.org/sax/features/validation", true );
parser.parse( XML_DOCUMENT_DTD ); //use DTD grammar for validation
Document document = parser.getDocument();
echoAll( document );
//-- add description for Indiana Jones movIE
//---- find parent Node
Element indianaJones = document.getElementById("_7755522");
//---- insert a description before the price
// (anywhere else would be invalid)
NodeList prices = indianaJones.getElementsByTagName("price");
Node desc = document.createElement("description");
desc.setTextContent(
"Indiana Jones is hired to find the Ark of the Covenant");
indianaJones.insertBefore( desc, prices.item(0) );
//-- now, echo the document again to see the change
echoAll( document );
} catch (DOMException e) { //handle invalid manipulations
short code = e.code;
if( code == DOMException.INVALID_MODIFICATION_ERR ) {
//take action when invalid manipulation attempted
} else if( code == DOMException.NOT_FOUND_ERR ) {
//take action when element or attribute not found
} //add more checks here as desired
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* Echo all the Nodes, in preorder traversal order, for aDocument
* @param aDocument
*/
protected static void echoAll(Document aDocument) {
if( aDocument.getImplementation().hasFeature(
TRAVERSAL_FEATURE,DOM_2) ) {
echo( "=== Echoing " + XML_DOCUMENT_DTD + " ===" + NEW_LINE );
Node root = (Node) aDocument.getDocumentElement();
int whatToShow = NodeFilter.SHOW_ALL;
NodeFilter filter = null;
boolean expandRefs = false;
//-- depth first, preorder traversal
DocumentTraversal traversal = (DocumentTraversal)aDocument;
TreeWalker walker = traversal.createTreeWalker(
(org.w3c.dom.Node) root, //where to start
//(cannot go "above" the root)
whatToShow, //what to include
filter, //what to exclude
expandRefs); //include referenced entitIEs or not
for( Node nextNode = (Node) walker.nextNode(); nextNode != null;
nextNode = (Node) walker.nextNode() ) {
echoNode( nextNode );
}
} else {
echo( NEW_LINE + "*** " + TRAVERSAL_FEATURE +
" feature is not supported" + NEW_LINE );
}
}
/**
* Output aNode's name, type, and value to standard output.
* @param aNode
*/
protected static void echoNode( Node aNode ) {
String type = nodeTypeNames[aNode.getNodeType()];
String name = aNode.getNodeName();
StringBuffer echoBuf = new StringBuffer();
echoBuf.append(type);
if( !name.startsWith("#") ) { //do not output duplicate names
echoBuf.append(": ");
echoBuf.append(name);
}
if( aNode.getNodeValue() != null ) {
if( echoBuf.indexOf("ProcInst") == 0 )
echoBuf.append( ", " );
else
echoBuf.append( ": " ); //output only to first newline
String trimmedValue = aNode.getNodeValue().trim();
int nlIndex = trimmedValue.indexOf("n");
if( nlIndex >= 0 ) //found newline
trimmedValue = trimmedValue.substring(0,nlIndex);
echoBuf.append(trimmedValue);
}
echo( echoBuf.toString() + NEW_LINE );
echoAttributes( aNode );
}
/**
* Output aNode's attributes to standard output.
* @param aNode
*/
protected static void echoAttributes(Node aNode) {
NamedNodeMap attr = aNode.getAttributes();
if( attr != null ) {
StringBuffer attrBuf = new StringBuffer();
for( int i = 0; i < attr.getLength(); i++ ) {
String type = nodeTypeNames[attr.item(i).getNodeType()];
attrBuf.append(type);
attrBuf.append( ": " + attr.item(i).getNodeName() + "=" );
attrBuf.append( """ + attr.item(i).getNodeValue() + """ +
NEW_LINE );
}
echo( attrBuf.toString() );
}
}
/**
* Output aString to standard output
* @param aString
*/
protected static void echo( String aString ) {
try {
writer.write( aString );
writer.flush();
} catch (IOException e) {
System.out.println( "I/O error during echo()" );
e.printStackTrace();
}
}
}
看看其中的部分邏輯:
protected static final String[] nodeTypeNames = {
...
};
該數組將 Node.getNodeType() int 值映射到可能遇到的每種 Node 類型:
if( aDocument.getImplementation().hasFeature(
TRAVERSAL_FEATURE,DOM_2) ) {
DOMEcho 利用了 DOM2(參見 DOM 1 與 DOM 2)的 TreeWalker 接口。為了安全起見,一定要檢查您的解析器是否支持該特性。閱讀 Processing XML with Java: A Guide to SAX, DOM, JDOM, JAXP, and TrAX(請參閱 參考資料)的第 9 章可以了解所有這些特性。
簡而言之,DOMEcho 有一個 echoAll(Document aDoc) 方法,該方法使用不帶篩選的 TreeWalker 按照先序遍歷順序訪問 Node(請參閱 DOM 1 與 DOM 2)。然後對每個節點調用 echoNode(Node aNode)。接著 echoNode 對它的 Node 調用 echoAttributes(Node aNode):
//---- find parent Node
Element indianaJones = document.getElementById("_7755522");
//---- insert a description before the price
// (anywhere else would be invalid)
NodeList prices = indianaJones.getElementsByTagName("price");
Node desc = document.createElement("description");
desc.setTextContent(
"Indiana Jones is hired to find the Ark of the Covenant");
indianaJones.insertBefore( desc, prices.item(0) );
就是這部分代碼修改了 DOM 樹。它在適當的位置添加了描述來保證樹按照文檔模式仍然是有效的。
清單 5 顯示了 DOMEcho 的輸出結果。
清單 5. DOMEcho 的輸出
=== Echoing catalogDTD.XML ===
Text:
Comment: DVD inventory
Text:
Element: dvd
Attr: code="_1234567"
Text:
Element: title
Text: Terminator 2
Text:
Element: description
Text: A shape-shifting cyborg is sent back from the future
to kill the leader of the resistance.
Text:
Element: price
Text: 19.95
Text:
Element: year
Text: 1991
Text:
Text:
Element: dvd
Attr: code="_7654321"
Text:
Element: title
Text: The Matrix
Text:
Element: price
Text: 10.95
Text:
Element: year
Text: 1999
Text:
Text:
Element: dvd
Attr: code="_2255577"
Attr: genre="Drama"
Text:
Element: title
Text: Life as a House
Text:
Element: description
Text: When a man is diagnosed with terminal cancer,
he takes custody of his misanthropic teenage son.
Text:
Element: price
Text: 15.95
Text:
Element: year
Text: 2001
Text:
Text:
Element: dvd
Attr: code="_7755522"
Attr: genre="Action"
Text:
Element: title
Text: Raiders of the Lost Ark
Text:
Element: price
Text: 14.95
Text:
Element: year
Text: 1981
Text:
Text:
=== Echoing catalogDTD.XML ===
Text:
Comment: DVD inventory
Text:
Element: dvd
Attr: code="_1234567"
Text:
Element: title
Text: Terminator 2
Text:
Element: description
Text: A shape-shifting cyborg is sent back from the future
to kill the leader of the resistance.
Text:
Element: price
Text: 19.95
Text:
Element: year
Text: 1991
Text:
Text:
Element: dvd
Attr: code="_7654321"
Text:
Element: title
Text: The Matrix
Text:
Element: price
Text: 10.95
Text:
Element: year
Text: 1999
Text:
Text:
Element: dvd
Attr: code="_2255577"
Attr: genre="Drama"
Text:
Element: title
Text: Life as a House
Text:
Element: description
Text: When a man is diagnosed with terminal cancer,
he takes custody of his misanthropic teenage son.
Text:
Element: price
Text: 15.95
Text:
Element: year
Text: 2001
Text:
Text:
Element: dvd
Attr: code="_7755522"
Attr: genre="Action"
Text:
Element: title
Text: Raiders of the Lost Ark
Text:
Element: description
Text: Indiana Jones is hired to find the Ark of the Covenant
Element: price
Text: 14.95
Text:
Element: year
Text: 1981
Text:
Text:
空白
您將注意到 DOMEcho 輸出(清單 6)中有大量 Text Node,其中很多看起來沒有內容。為什麼會這樣呢?
解析器報告文檔元素內容中出現的空白(多余的空白、制表符和回車換行)。
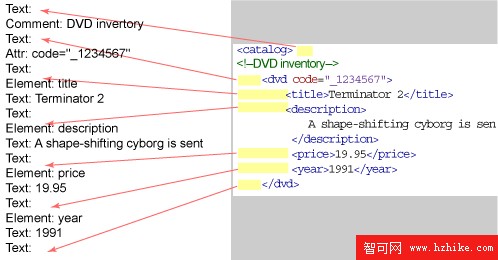
需要注意的是沒有 報告的東西:元素中的空白,比如屬性周圍的空格。這裡沒有顯示,但是也不會報告的是序言中的空白。要注意,description 有 一個 Text Element,但是空白被規范化 從而去掉了非空白內容之前和之後的多余字符。
由 Element 內容中的空白造成的 Text 元素稱為不可忽略的 空白。不可忽略的空白是驗證的一部分,如 圖 4 所示。
圖 4. 空白處理
驗證 XML 文檔
驗證包括使用文法保證 XML 文檔具有正確的結構和內容。可以使用 XML 模式來指定文法,形式包括 DTD 或 XML Schema 文件(請參閱 模式)。教程的這一節討論 DTD 和 XML Schema 文件。
使用 DTD 驗證
DTD 定義了應用於 XML 實例文檔上的約束。這些約束與結構良好性無關。事實上,非結構良好的文檔根本不被看作是 XML 文檔。約束與關於內容的業務規則有關,為了保證應用程序能夠使用文檔,文檔必須滿足這些規則。
DTD 規定了為了保證有效 XML 實例文檔必須包含的元素和屬性。可以通過在文檔開始部分包含 DOCTYPE 語句把文檔和 DTD 聯系起來:
<!DOCTYPE catalog SYSTEM "catalog.dtd">
現在來看看 catalog.dtd 文件。為了驗證該文檔,需要啟用驗證並使用驗證解析器。下面的代碼啟用 SAX 解析器的驗證特性:
saxParser.setFeature(
"http://XML.org/sax/features/validation", true );
下面的代碼啟用 DOM 解析器的驗證特性:
domParser.setFeature(
"http://XML.org/dom/features/validation", true );
圖 5 顯示了 catalog.dtd 文件。
圖 5. Catalog DTD
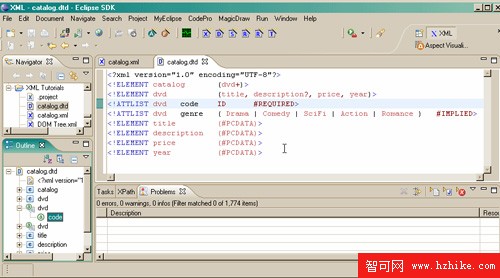
我們逐行地來分析這個 DTD,看看規定了什麼:
<!ELEMENT catalog (dvd+)>
dvd+ 指定 <catalog> 元素包含一個或多個 <dvd>。這樣做是合理的,否則就不可能賣掉多少 DVD!
<!ELEMENT dvd (title, description?, price, year)>
title, ..., year 稱為序列。就是說這些命名的元素必須按照這種 順序作為 <dvd> 元素的孩子出現。description 後面的問號表明 <dvd> 可以有零個或一個描述元素 —— 換句話說,它是可選的,但如果指定的話也只能有一個(星號表示零個或多個,加號表示 1 個或多個)。
<!ATTLIST dvd code ID #REQUIRED>
ID 類型的屬性在文檔中的名稱必須是惟一的。您將看到 catalog.xml 文件中的 ID 都是以下劃線開始的。XML 名稱不能以數字開始,但是下劃線(以及字母或者其他非數字字符)可以。一個元素只能有一個 ID 類型的屬性。您可能已經猜到了,REQUIRED 意味著 <dvd> 必須 有一個 code。
<!ATTLIST dvd genre ( Drama | Comedy | SciFi | Action | Romance ) #IMPLIED>
這是一個枚舉。由於指定為 IMPLIED,因而是可選的。但是,如果在文檔中出現 了,則必須是枚舉值中的一個(讀作 “Drama 或 Comedy 或……”)。
<!ELEMENT title (#PCDATA)>
<!ELEMENT description (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT year (#PCDATA)>
剩下的行都用於指定可解析字符數據。這些元素都不能有孩子。
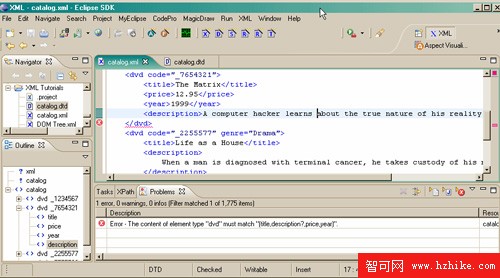
現在嘗試修改實例文檔以便保證這些規則能夠正常工作。首先增加一個 <description>,但是將其放在 <dvd> 的最後。如您所料,結果得到了一條錯誤消息(如圖 6 所示)。
圖 6. Description 錯誤
現在增加一個 genre(如 圖 7 所示)。
圖 7. Genre 錯誤
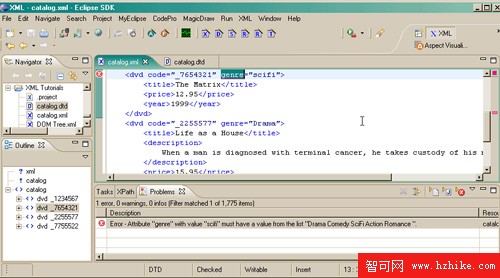
為什麼不行呢?列表中有科幻小說啊!不過,您知道,XML 是大小寫敏感的,因此 "scifi" 是無效的,而必須是 "SciFi"。
現在看看 ID 是否必須是惟一的。將 code 復制到另一個 <dvd> 中(如 圖 8 所示)。
圖 8. ID 錯誤
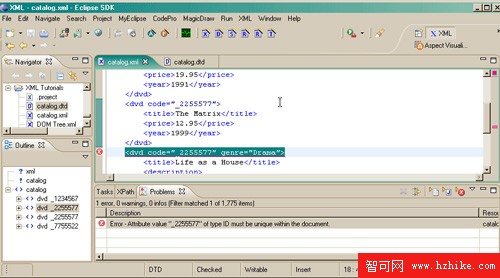
毫無疑問都看到了適當的錯誤。您應該清楚了。可使用這裡的 DTD 和 XML 文件嘗試其他修改(源文件請參閱 下載 部分)。
DTD 異常處理
為了處理 DTD 操作錯誤必須啟用驗證。對於 Xerces,只要將模式驗證特性設置為 true:
parser.setFeature(
"http://apache.org/XML/features/validation/schema",
true );
通過 apache Software Foundation 網站(請參閱 參考資料)可以了解 Xerces 解析器的各種特性。關於 DTD 驗證的更多信息,請參閱 XML in a Nutshell, Third Edition(參見 參考資料)的第 3 章。