本文示例源代碼或素材下載
需要准備什麼
開始之前需要保證具備了本文所需要的前提條件。確保滿足這些要求最簡單的辦法就是按照 本系列第一篇文章(鏈接參見本文 參考資料 部分)介紹的步驟操作。第一篇文章介紹了如何下載、安裝和配置 Castor,並用一些簡單的類進行了測試。
從您手頭的項目中選擇一些類轉換成 XML 然後再轉換回來也沒有問題。本文(以及上一期文章)提供了一些例子,但是要掌握 Castor,最好的辦法是把這裡學到的東西應用到您自己的項目中。首先從一些簡單的對象類開始,比如代表人、唱片、圖書或者某種其他具體對象的類。然後可以閱讀本文中關於映射的內容,從而增加一些更復雜的類。
編組 101
Castor 最基本的操作是取一個 Java 類然後將類的實例編組成 XML。可以把類本身作為頂層容器元素。比如 Book 類很可能在 XML 文檔中得到一個名為 “book” 的根元素。
類的每個屬性也表示在 XML 文檔中。因此值為 “Power Play” 的 title 屬性將生成這樣的 XML:
<title>Power Play</title>
很容易由此推出一個簡單 Java 類所生成的 XML 文檔的其余部分。
編組類的實例
開始編組代碼之前有幾點需要注意。第一,只能編組類的實例而不能編組類本身。類是一種結構,等同於 XML 約束模型,如 DTD 或 XML Schema。類本身沒有數據,僅僅定義了所存儲的數據的結構和訪問方法。
實例化類(或者通過工廠以及其他實例生成機制獲得)將賦予它具體的形式。然後用實際數據填充實例的字段。實例是惟一的,它和同一類的實例具有相同的結構,但數據是不同的。圖 1 直觀地說明了這種關系。
圖 1. 類提供結構,實例即數據
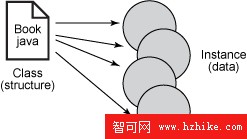
因而編組的只能是實例。後面將看到如何使用約束模型和映射文件改變 XML 的結構。但是現在要做的是讓 XML 結構(元素和屬性)和 Java 結構(屬性)匹配。
基本的編組
清單 1 是本文中將使用的一個簡單的 Book 類。
清單 1. Book 類
package ibm.XML.castor;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The author's name */
private String authorName;
public Book(String isbn, String title, String authorName) {
this.isbn = isbn;
this.title = title;
this.authorName = authorName;
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getAuthorName() {
return authorName;
}
}
編譯上述代碼將得到 Book.class 文件。這個類非常簡單,只有三個屬性:ISBN、標題和作者姓名(這裡有些問題,暫時先不管)。僅僅這一個文件還不夠,Castor 還需要幾行代碼將 Book 類的實例轉化成 XML 文檔。清單 2 中的小程序創建了一個新的 Book 實例並使用 Castor 轉化成 XML。
清單 2. Book 編組器類
package ibm.XML.castor;
import Java.io.FileWriter;
import org.exolab.castor.XML.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Book book = new Book("9780312347482", "Power Play", "Joseph Finder");
FileWriter writer = new FileWriter("book.XML");
Marshaller.marshal(book, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
編譯然後運行該程序。將得到一個新文件 book.XML。打開該文件將看到如下所示的內容:
清單 3. 編譯後的程序創建的 XML
<?XML version="1.0" encoding="UTF-8"?>
<book><author-name>Joseph Finder</author-name>
<isbn>9780312347482</isbn><title>Power Play</title></book>
為了清晰起見我增加了斷行。實際生成的 XML 文檔在 author-name 元素的結束標記和 isbn 元素的開始標記之間沒有斷行。
Castor 遺漏了什麼
在改進這個例子之前 — 很有必要改進— 先看看 Castor 在 XML 中漏掉 了什麼:
Java 類的包。Java 包不屬於類結構。這實際上是一個語義問題,和 Java 名稱空間有關。因此可以將這個 XML 文檔解組 — 從 XML 轉換為 Java 代碼 — 到任何具有相同的三個屬性的 Book 實例,不論是什麼包。
字段順序。這是 XML 的順序問題,和 Java 編程無關。因此盡管源文件按某種順序列出字段,但 XML 文檔可能完全不同。這對於 XML 來說至關重要,但是和 Book 類聲明無關。
方法。和包聲明一樣,方法也和數據結構無關。因此 XML 文檔沒有涉及到這些方面,將其忽略了。
那麼就要問 “那又怎麼樣呢?” 如果不重要,XML 忽略這些細節又有什麼關系呢?但是這些信息很 重要。之所以重要是因為它們提供了超出預想的更大的靈活性。可以將這些 XML 解組為滿足最低要求的任何類:
類名為 “Book”(使用映射文件可以改變,但這一點後面再說)。
這個類包括三個字段:authorName、title 和 isbn。
僅此而已!看看能否編寫滿足這些要求的幾個類,並改變類的其他 字段或者包聲明、方法……很快您就會發現這種方法使得 Castor 多麼靈活。
添加更復雜的類型
Book 類最明顯的不足是不能存儲多個作者。修改類使其能處理多個作者也很容易:
清單 4. 存儲多個作者的 Book 類
package ibm.XML.castor;
import Java.util.LinkedList;
import Java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List authorNames;
public Book(String isbn, String title, List authorNames) {
this.isbn = isbn;
this.title = title;
this.authorNames = authorNames;
}
public Book(String isbn, String title, String authorName) {
this.isbn = isbn;
this.title = title;
this.authorNames = new LinkedList();
authorNames.add(authorName);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthorNames(List authorNames) {
this.authorNames = authorNames;
}
public List getAuthorNames() {
return authorNames;
}
public void addAuthorName(String authorName) {
authorNames.add(authorName);
}
}
如果使用 Java 5 或 6 技術,將會顯示一些未檢查/不安全操作的錯誤,因為這段代碼沒有使用參數化的 Lists。如果願意可以自己增加這些代碼。
這樣的修改很簡單,不需要對編組代碼作任何修改。但是,有必要用一本多人編寫的圖書來驗證 Castor 編組器能否處理集合。修改 BookMarshaller 類如下:
清單 5. 處理收集器的 Book 類
package ibm.XML.castor;
import Java.io.FileWriter;
import Java.util.ArrayList;
import Java.util.List;
import org.exolab.castor.XML.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Book book = new Book("9780312347482", "Power Play", "Joseph Finder");
FileWriter writer = new FileWriter("book.XML");
Marshaller.marshal(book, writer);
List book2Authors = new ArrayList();
book2Authors.add("Douglas Preston");
book2Authors.add("Lincoln Child");
Book book2 = new Book("9780446618502", "The Book of the Dead",
book2Authors);
writer = new FileWriter("book2.XML");
Marshaller.marshal(book2, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
第一本書的處理方式沒有變,重新打開 book.xml 將看到和原來相同的結果。打開 book2.XML 看看 Castor 如何處理集合:
清單 6. 帶有收集器的 XML 結果
<?XML version="1.0" encoding="UTF-8"?>
<book><isbn>9780446618502</isbn><title>The Book of the Dead</title>
<author-names xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="java:Java.lang.String">Douglas Preston</author-names>
<author-names xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="java:Java.lang.String">Lincoln Child</author-names>
</book>
顯然,Castor 處理作者姓名列表沒有問題。更重要的是,Castor 不僅為作者名稱創建了一個 blanket 容器,這個框架實際上看到了列表的內部,並認識到內容是字符串(要記住,這不是參數化列表,Castor 必須自己確定列表成員的類型)。因此 XML 進行了一些非常具體的類型化工作。這是個不錯的特性,尤其是如果需要將 XML 轉化回 Java 代碼之前進行一些處理的話。
添加自定義類
我們朝著真正實用的程序再前進一步。存儲字符串作者姓名肯定最終會出現重復的數據(多數作者寫了不只一本書)。清單 7 增加了一個新的類 Author。
清單 7. Author 類
package ibm.XML.castor;
public class Author {
private String firstName, lastName;
private int totalSales;
public Author(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setTotalSales(int totalSales) {
this.totalSales = totalSales;
}
public void addToSales(int additionalSales) {
this.totalSales += additionalSales;
}
public int getTotalSales() {
return totalSales;
}
}
是不是很簡單?在 Book 類的下面作上述修改以便能夠使用新的 Author 類。
清單 8. 使用自定義作者類的 Book 類
package ibm.XML.castor;
import Java.util.LinkedList;
import Java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List authors;
public Book(String isbn, String title, List authors) {
this.isbn = isbn;
this.title = title;
this.authors = authors;
}
public Book(String isbn, String title, Author author) {
this.isbn = isbn;
this.title = title;
this.authors = new LinkedList();
authors.add(author);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthors(List authors) {
this.authors = authors;
}
public List getAuthors() {
return authors;
}
public void addAuthor(Author author) {
authors.add(author);
}
}
測試上述代碼需要對 BookMarshaller 略加修改:
清單 9. 增加了作者信息的 BookMarshaller 類
package ibm.XML.castor;
import Java.io.FileWriter;
import Java.util.ArrayList;
import Java.util.List;
import org.exolab.castor.XML.Marshaller;
public class BookMarshaller {
public static void main(String[] args) {
try {
Author finder = new Author("Joseph", "Finder");
Book book = new Book("9780312347482", "Power Play", finder);
FileWriter writer = new FileWriter("book.XML");
Marshaller.marshal(book, writer);
List book2Authors = new ArrayList();
book2Authors.add(new Author("Douglas", "Preston"));
book2Authors.add(new Author("Lincoln", "Child"));
Book book2 = new Book("9780446618502", "The Book of the Dead",
book2Authors);
writer = new FileWriter("book2.XML");
Marshaller.marshal(book2, writer);
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
僅此而已!編譯然後運行編組器。看看兩個結果文件,這裡僅列出 book2.XML,因為這個文件更有趣一點。
清單 10. 包括作者和圖書信息的 XML 結果
<?XML version="1.0" encoding="UTF-8"?>
<book><authors xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
total-sales="0" xsi:type="Java:ibm.XML.castor.Author"><last-name>Preston</last-name>
<first-name>Douglas</first-name></authors><authors
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" total-sales="0"
xsi:type="Java:ibm.XML.castor.Author"><last-name>Child</last-name>
<first-name>Lincoln</first-name></authors><isbn>9780446618502</isbn>
<title>The Book of the Dead</title></book>
Castor 同樣能辦到。它說明了如何同時編組 Book 和 Author 類(再看看 authors 列表)。Castor 甚至為 Author 增加了 totalSales 屬性,可以試試看結果如何。
Castor 對泛型的處理
也許聽起來像是全天候的推銷頻道,但 Castor 確實支持泛型和參數化列表。因此如果習慣 Java 5 或 Java 6,可以這樣修改 Book:
清單 11. 處理泛型和參數化列表的 Book 類
package ibm.XML.castor;
import Java.util.LinkedList;
import Java.util.List;
public class Book {
/** The book's ISBN */
private String isbn;
/** The book's title */
private String title;
/** The authors' names */
private List<Author> authors;
public Book(String isbn, String title, List<Author> authors) {
this.isbn = isbn;
this.title = title;
this.authors = authors;
}
public Book(String isbn, String title, Author author) {
this.isbn = isbn;
this.title = title;
this.authors = new LinkedList<Author>();
authors.add(author);
}
public String getIsbn() {
return isbn;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setAuthors(List<Author> authors) {
this.authors = authors;
}
public List<Author> getAuthors() {
return authors;
}
public void addAuthor(Author author) {
authors.add(author);
}
}
這樣作者列表就只 接受 Author 實例了,這是一個非常重要的改進。可以對 BookMarshaller 作類似的修改,重新編譯,並得到相同的 XML 輸出。換句話說,可以為 Castor 建立非常具體的類。
類變了但 Castor 沒有變
在最終討論解組之前,還需要做一項重要的觀察。前面對類作的所有修改都沒有改變編組代碼!我們增加了泛型、自定義類、集合等等,但是編組 XML,Castor API 只需要一次簡單的調用。太令人吃驚了!
解組
花了很多時間詳細討論完編組以後,解組非常簡單。有了 XML 文檔,並保證具有和數據匹配的 Java 類之後,剩下的工作交給 Castor 就行了。我們來解組前面生成的兩個 XML 文檔。如清單 12 所示。
清單 12. 解組圖書
package ibm.XML.castor;
import Java.io.FileReader;
import Java.util.Iterator;
import Java.util.List;
import org.exolab.castor.XML.Unmarshaller;
public class BookUnmarshaller {
public static void main(String[] args) {
try {
FileReader reader = new FileReader("book.XML");
Book book = (Book)Unmarshaller.unmarshal(Book.class, reader);
System.out.println("Book ISBN: " + book.getIsbn());
System.out.println("Book Title: " + book.getTitle());
List authors = book.getAuthors();
for (Iterator i = authors.iterator(); i.hasNext(); ) {
Author author = (Author)i.next();
System.out.println("Author: " + author.getFirstName() + " " +
author.getLastName());
}
System.out.println();
reader = new FileReader("book2.XML");
book = (Book)Unmarshaller.unmarshal(Book.class, reader);
System.out.println("Book ISBN: " + book.getIsbn());
System.out.println("Book Title: " + book.getTitle());
authors = book.getAuthors();
for (Iterator i = authors.iterator(); i.hasNext(); ) {
Author author = (Author)i.next();
System.out.println("Author: " + author.getFirstName() + " " +
author.getLastName());
}
} catch (Exception e) {
System.err.println(e.getMessage());
e.printStackTrace(System.err);
}
}
}
編譯代碼並運行。您可能會得到意料之外的結果!我遇到的錯誤和堆棧記錄如下所示:
清單 13. 解組遇到的錯誤和堆棧記錄
[bmclaugh:~/Documents/developerworks/castor-2]
Java ibm.XML.castor.BookUnmarshaller
ibm.XML.castor.Book
org.exolab.castor.xml.MarshalException: ibm.XML.castor.Book{File:
[not available]; line: 2; column: 7}
at org.exolab.castor.XML.Unmarshaller.
convertSAXExceptionToMarshalException(Unmarshaller.Java:755)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:721)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:610)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:812)
at ibm.XML.castor.BookUnmarshaller.main
(BookUnmarshaller.Java:14)
Caused by: Java.lang.InstantiationException: ibm.XML.castor.Book
at java.lang.Class.newInstance0(Class.Java:335)
at java.lang.Class.newInstance(Class.Java:303)
at org.exolab.castor.util.DefaultObjectFactory.createInstance(
DefaultObjectFactory.Java:107)
at org.exolab.castor.XML.UnmarshalHandler.createInstance(
UnmarshalHandler.Java:2489)
at org.exolab.castor.XML.UnmarshalHandler.startElement(
UnmarshalHandler.Java:1622)
at org.exolab.castor.XML.UnmarshalHandler.startElement(
UnmarshalHandler.Java:1353)
at org.apache.xerces.parsers.AbstractSAXParser.startElement
(Unknown Source)
at org.apache.xerces.impl.dtd.XMLDTDValidator.startElement
(Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanStartElement(
Unknown Source)
at org.apache.xerces.impl.XMLDocumentScannerImpl
$ContentDispatcher.
scanRootElementHook(Unknown Source)
at org.apache.xerces.impl.
XMLDocumentFragmentScannerImpl
$FragmentContentDispatcher.dispatch(
Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanDocument(
Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XMLParser.parse(Unknown Source)
at org.apache.xerces.parsers.AbstractSAXParser.parse(Unknown
Source)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:709)
... 3 more
Caused by: Java.lang.InstantiationException: ibm.XML.castor.Book
at java.lang.Class.newInstance0(Class.Java:335)
at java.lang.Class.newInstance(Class.Java:303)
at org.exolab.castor.util.DefaultObjectFactory.createInstance(
DefaultObjectFactory.Java:107)
at org.exolab.castor.XML.UnmarshalHandler.createInstance(
UnmarshalHandler.Java:2489)
at org.exolab.castor.XML.UnmarshalHandler.startElement
(UnmarshalHandler.Java:1622)
at org.exolab.castor.XML.UnmarshalHandler.startElement
(UnmarshalHandler.Java:1353)
at org.apache.xerces.parsers.AbstractSAXParser.startElement
(Unknown Source)
at org.apache.xerces.impl.dtd.XMLDTDValidator.startElement
(Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanStartElement(
Unknown Source)
at org.apache.xerces.impl.XMLDocumentScannerImpl
$ContentDispatcher.
scanRootElementHook(Unknown Source)
at org.apache.xerces.impl.
XMLDocumentFragmentScannerImpl
$FragmentContentDispatcher.dispatch(
Unknown Source)
at
org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanDocument(
Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XML11Configuration.parse
(Unknown Source)
at org.apache.xerces.parsers.XMLParser.parse(Unknown Source)
at org.apache.xerces.parsers.AbstractSAXParser.parse(Unknown
Source)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:709)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:610)
at org.exolab.castor.XML.Unmarshaller.unmarshal
(Unmarshaller.Java:812)
at ibm.XML.castor.BookUnmarshaller.main
(BookUnmarshaller.Java:14)
那麼到底是怎麼回事呢?您遇到了直接使用 Castor 進行數據綁定必須要做出的幾個讓步中的第一個。
Castor 要求使用無參數的構造器
Castor 主要通過反射和調用 Class.forName(類名).newInstance() 這樣的方法進行解組,因而 Castor 不需要了解很多就能實例化類。但是,它還要求類必須能通過不帶參數的構造器實例化。
好消息是 Book 和 Author 類只需簡單修改就能避免這些錯誤。只需要為兩個類增加不帶參數的構造器,public Book() { } 和 public Author() { }。重新編譯並運行代碼。
想想這意味著什麼。有了無參數的構造器,不僅僅是 Castor,任何 類或者程序都能創建類的新實例。對於圖書和作者來說,可以創建沒有 ISBN、標題和作者的圖書,或者沒有姓和名的作者 — 這肯定會造成問題。如果 Castor 沒有更先進的特性(下一期再討論)這種缺陷就不可避免,因此必須非常注意類的使用。還必須考慮為任何可能造成 NullPointerException 錯誤的數據類型設置具體的值(字符串可以設為空串或者默認值,對象必須初始化等等)。
第二步:null 引起的更多問題
為 Book 和 Author 類增加無參數構造器,重新運行解組器。結果如下:
清單 14. 添加無參數構造器後的結果
[bmclaugh:~/Documents/developerworks/castor-2] Java ibm.XML.castor.BookUnmarshaller
Book ISBN: null
Book Title: Power Play
Author: null null
Book ISBN: null
Book Title: The Book of the Dead
Author: null null
Author: null null
看來還有問題沒解決(不是說解組很簡單嗎?先等等,後面還要說)。值得注意的是,有幾個字段為空。把這些字段和 XML 比較,會發現這些字段在 XML 文檔都有正確的表示。那麼是什麼原因呢?
為了找出根源,首先注意圖書的標題都 設置正確。此外仔細觀察第二本書 The Book of the Dead。雖然初看起來似乎兩本書的作者都沒有設置,但問題不在這裡。事實上,第二本書正確引用了兩個 Author 對象。因此它引用了這兩個對象,但是這些對象本身沒有設置姓和名。因此圖書的標題設置了,作者也一樣。但是 ISBN 是空的,作者的姓和名也是空的。這是另一條線索:如果顯示作者圖書的總銷售量,這些值就不會 是空。
發現了嗎?空值字段都沒有 setter(或 mutator)方法。沒有 setIsbn()、setFirstName() 等等。這是因為類被設計成需要構造信息(一旦書有了自己的 ISBN,這個 ISBN 實際上就不能改變了,基本上就意味著一本書形成了,因此最好要求構造/實例化新圖書的時候提供新的 ISBN)。
還記得嗎?Castor 使用反射機制。恰恰因為只有對象提供無參數構造器的時候它才能創建對象,因為沒有 setFIEldName() 方法就無法設置字段的值。因此需要為 Book 和 Author 類增加一些方法。下面是需要添加的方法(實現很簡單,留給讀者自己完成):
setIsbn(String isbn)(Book 類)
setFirstName(String firstName)(Author 類)
setLastName(String lastName)(Author 類)
增加上述方法之後重新編譯就行了。
第三步:成功解組
再次嘗試運行解組器,將得到如下所示的結果:
清單 15. 增加作者和 ISBN setter 方法後的解組結果
[bmclaugh:~/Documents/developerworks/castor-2] Java ibm.XML.castor.BookUnmarshaller
Book ISBN: 9780312347482
Book Title: Power Play
Author: Joseph Finder
Book ISBN: 9780446618502
Book Title: The Book of the Dead
Author: Douglas Preston
Author: Lincoln Child
終於得到了我們需要的結果。必須對類作幾方面的修改。但是前面我曾提到解組非常簡單。但是這和上面的情況不符,解組不是需要對類作很多修改嗎?
實際上的確很簡單。修改都是在您的類中,而和 Castor 解組過程無關。Castor 用起來非常簡單,只要類的結構符合 Castor 的要求 — 每個類都要有無參數構造器,每個字段都要有 get/set 方法。
代價是值得的
現在的類和最初相比沒有很大變化。Book 和 Author 沒有面目全非,功能上沒有很大不同(實際上沒有什麼區別)。但是現在設計還有一點問題。圖書必須 有 ISBN(至少在我看來),因此能夠創建沒有 ISBN 的圖書 — 無參數構造器 — 令我感到困擾。此外,我也不願意別人隨便改動圖書的 ISBN,這樣不能正確地表示圖書對象。
作者的修改不那麼嚴重,因為對於作者這個對象來說姓名可能不是很重要的標識符。名字可以改,現在甚至姓都可以改。另外,兩位作者如果同名,目前也沒有區分的現成辦法。但即使增加了更具唯一性、更合適的標識符(社會安全號碼、駕駛證號、其他標識符),仍然需要無參數構造器和字段 setter 方法。因此問題仍然存在。
這就變成了效益和控制的問題:
Castor 是否提供了足夠的好處 — 簡化數據綁定 — 足以抵得上設計所要做出的讓步?
對代碼庫是否有足夠的控制權,避免濫用為 Castor 增加的方法?
只有您才能代表您的企業回答這些問題。對於多數開發人員來說,權衡的結果傾向於 Castor,就必須做出適當的讓步。對於那些沉醉於設計或者由於特殊需求無法做出這些讓步的少數人,可能更願意自己編寫簡單的 XML 序列化工具。無論如何,應該將 Castor 放到您的工具包裡。如果它不適合當前的項目,也許下一個用得上。
結束語
到目前為止還沒有提到的 Castor 的一大特性是映射文件。我們是直接從 Java 代碼翻譯成 XML。但是有幾個假定:
需要把 Java 類中的所有字段持久到 XML。
需要在 XML 中保留類名和字段名。
有一個類模型和需要反序列化的 XML 文檔中的數據匹配。
對於企業級編程,這些假定都有可能不成立。如果將字段名和類名存儲到 XML 文檔中被認為是一種安全風險,可能會過多洩露應用程序的結構,該怎麼辦?如果交給您一個 XML 文檔需要轉化成 Java 代碼,但希望使用不同的方法名稱和字段名稱,怎麼辦?如果只需要少數類屬性存儲到 XML 中,怎麼辦?
所有這些問題的答案都是一個:Castor 提供了進一步控制 Java 代碼和 XML 之間映射關系的方式。下一期文章我們將詳細介紹映射。現在,不要只考慮編組和解組,還要花時間想想為了讓 Castor 正常工作所作的那些修改意味著什麼。在思考的同時,不要忘記回來看看下一期文章。到時候再見。