前言
時代變了。
以往數據更多的通過人工錄入,從專用網絡協議的終端轉移到“玻璃房子”裡的大鐵盒子,現在信息無所不在、無時不在,不過不一定都會匯總到您公司裡,很多時候大家是在一個“平”的世界裡分享數據,信息來源的渠道多了、信息本身的變化也更加頻繁。不僅如此隨著Web 2.0、Enterprise 2.0和Internet Service Bus等一系列概念的出現,您發現單單從自己的“玻璃房子”裡找供貨商提供的倉庫地址遠不如Google Map方便。
似乎以往桎梏數據的各種枷鎖在互聯網下被一一打破,但作為IT從業者,我們的工作是為用戶提供它們所需的數據和他們希望獲取信息的手段,因此應用必須能夠經得起各種變化,包括以往我們關心的用戶界面的變化、應用間調用的變化、應用內部邏輯的變化,還有步伐越來越快但又是最根本變化——數據自身的變化。
關系模型告訴我們要用二維表格描述信息世界,但這是太“不”自然不過了,看看手邊的一本書或是家裡的裝修計劃、馬上要開工項目的任務分解,好像套到一個二維表格裡總不合適,而且即便通過“實體——關系”生硬的削足適履後,在快速變化的環境下又總是要牽涉到“數據——應用——前端交互”一系列變動,而且經常是牽一發動全身。
似乎很多新一代應用已經找到了更適合新趨勢的方案——XML,用一種更貼近我們自己思維的方式組織應用、組織用戶體驗。那麼對於企業而言,組織數據這種相對基礎性的工作是否也可以用XML的思維進行呢?應該可以。
應對數據實體自身的變化
數據實體以往總是被假設為應用中最為穩定的部分,無論我們用設計模式還是采用各種開源的開發框架(包括這些框架本身)都是盡量在適應應用本身變化的問題,那麼現實的情況如何呢?
l 我們需要交換的數據實體經常要根據自身、合作方的需要變化;
l 合作方給我們的數據實體也常常變化;
l 隨著SOA和Enterprise 2.0概念的推出,數據實體本身從多個源mash up出來,同時數據實體本身也被反復的拼裝和組合;
l 隨著業務的細化,我們自己的員工總是希望獲取越來越豐富,同時也越來越詳盡的信息;
因此,以往視需求也好、設計也好認為可以最早固定下來的數據實體在愈發敏捷的技術和業務現狀前需要不斷調整。為了適應這個要求我們可以自頂向下入手,不斷調整應用自身的柔性;另一個方式是從“根”上處理這個問題,采用自身就可以不斷適應這些變化的新數據模型,例如:XML數據模型和XML相關技術家族。
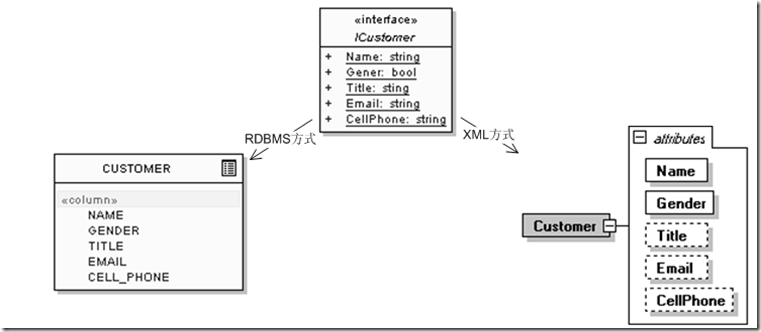
例如,定義用戶實體的時候,最初下面的信息就夠了,其中ICustomer是應用會使用的用戶接口,而CUSTOMER為關系數據庫方式下的表示,<Customer>為XML方式:
不過緊接著我們就發現這個實體設計有些問題,因為還要增加用戶的辦公室電話、住宅電話,還有可能1、2個電子郵件,他的MSN或Skype號碼等。不考慮其他問題,僅僅從關系模型范1的要求,那麼RDBMS和XML兩個模型發展的結果就成了:
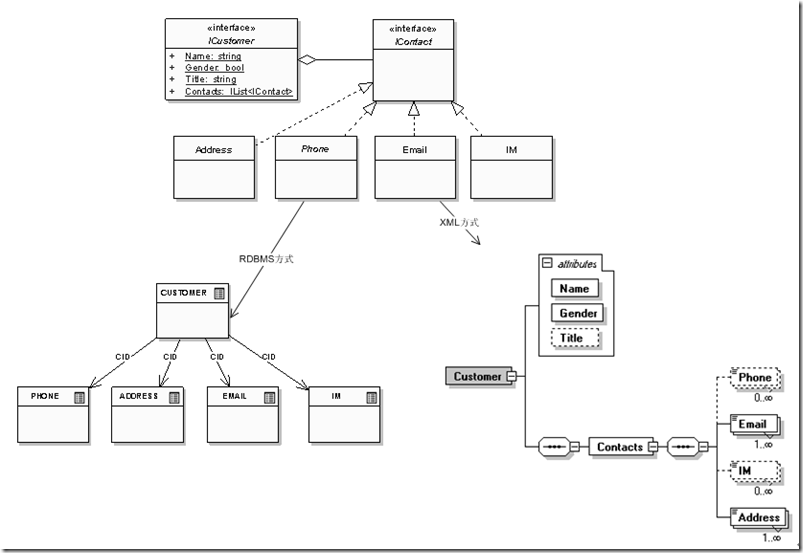
不難看出,雖然僅僅只是“客戶”數據實體末節“聯系信息”的一個變化,關系模型和XML模型在適應性方面就有非常大的區別,關系模型需要不斷擴展出新的關系用來描述不斷細化的數據實體,而XML模型自身的層次性可以提供變化條件下,自身的不斷延伸和擴展。實際項目中,“學歷情況”、“工作經驗情況”等信息也存在類似的問題,關系模型下即便某位客戶希望把某階段工作情況的“借調”方式補充進去,也會發現因為設計上沒有預留相應的字段,因此只好把它作為字符串“揉”在“工作單位”字段裡,後面補充個“(借調)”,這等於僵化的數據模型本身抹殺了數據的業務語義中包括的信息;而層次模型可以把它作為一個子節點或屬性來描述,這樣不僅可以把關系模型下需要多個關系(客戶、學歷情況、工作經驗、聯系信息)集中在一個數據實體內部,而且可以把每個實體自身的擴展信息(例如“工作模式”:借調、交流、短期集中)等也描述在數據實體內部,同時從外部應用看“客戶”實體本身依然是一個實體,這樣用更貼近現實業務情景的數據實體才能更有效的適應外部變化。
上面我們討論的僅僅是一個數據實體,進一步發展到具體業務領域模型模型的時候,往往需要同時綜合多個數據實體協作完成業務功能,這時候情形又如何呢?比如:保單需要客戶提供除了上述信息外的個人健康信息,子女、父母、伴侶家庭主要成員信息,同時會從其他從業機構獲取用戶的信用信息等,而且不同的數據實體組合主要用於企業內部的各異的應用領域,因此從數據使用角度看為了盡量讓應用部分穩定,最好是數據實體穩定,但僅僅用戶信息的聯系方式部分就可能會反復的變化,如果讓應用完全依賴這些變化因素組合後的結果,那麼應用的穩定性確實難以保證,那麼從源頭上第一步先盡量保證不同應用盡量僅依賴於具體一個實體也許是有效改進的第一步,這時候XML的層次特性優勢又顯示出來了,比如我們可以根據不同的應用主題,自由組合這些信息:
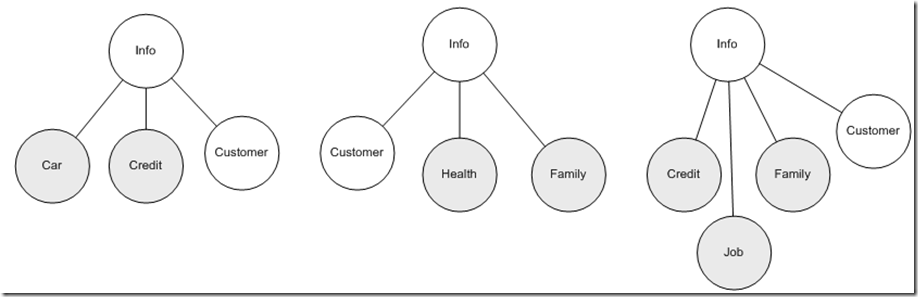
這樣應用面對的就是一個統一的<info>實體,相應的采用專用的XML技術可以保證應用框架不變的情況下,新的業務可以動態響應變化的數據實體。
應對數據和內容的集成
上面提的數據實體更多是在一個已經集中後的語境下討論的,但除了概念上的設計外,使用中還有一個具體的問題就是如何如何把他們“聚集”到一起,這個一般通過數據集成實現。
(不過就像“架構”一詞被過度濫用一樣,“數據集成”同樣被各個廠家根據自己的產品特征被定義成不同概念的組合,比如BI廠商力圖把它描繪成ETL的代名詞、提供數據交換平台的廠商描述為實現BizTalk Framework的產品、對於SOA產品公司而言,數據集成則更多在於如何保證在有效治理的前提下提供數據服務,另外對於一些廠商而已,數據集成還包括業務語義組合等。)
但作為用戶,數據集成我們要著重關心什麼問題呢?
l 數據實體的映射關系;
l 數據源的在各種交換協議、行業數據標准、安全控制約束下的互聯;
l 數據交換過程的編排;
l 數據實體的驗證和重構;
l 數據介質、數據載體的轉換;
雖然理論上這些工作用編碼完成不成問題,但隨著企業集成邏輯越來越復雜且變化越來越快,修改代碼即便可以應付一下1:N的集成,但如果經常是M:N的情況,那麼就顯得力不從心了。是否可以有更簡化的辦法呢?僅從“映射”的邏輯層次說:
l 面向對象思想告訴我們依賴倒置,要盡量依賴於抽象而不是具體,比如依賴於接口而非實體類型;
l 設計模式告訴我們,不兼容接口間適配器(Adapter)是個不錯的途徑;
那麼數據領域是否也有類似的技術呢?XML Schema + XSLT也許就是個選擇。
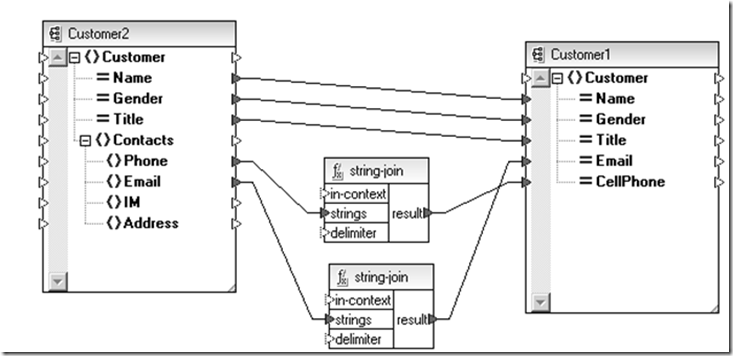
上面是為了兼容新、老用戶實體做的轉換,同樣的如果需要進行上部分針對不同主體的數據實體聚合操作也完全可以借助在抽象數據定義(Schema)層次通過XSLT(Schema間的適配關系)完成。
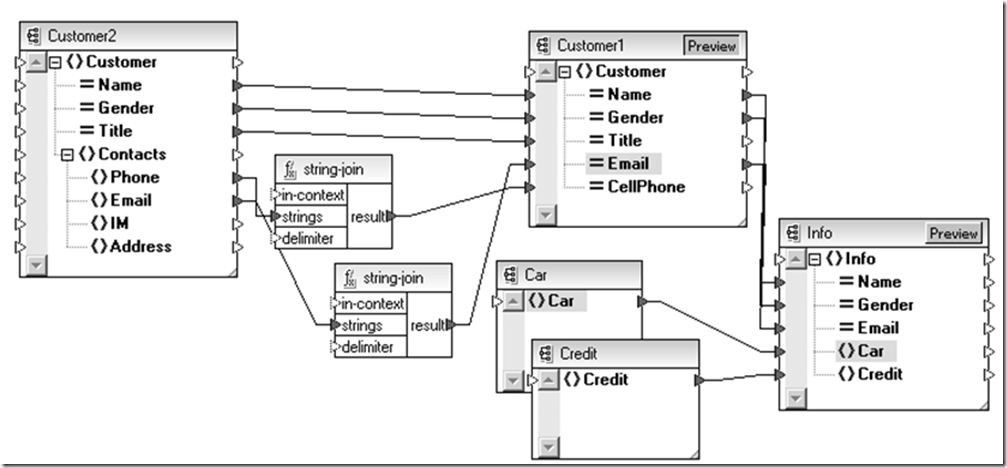
這樣,我們可以在數據實體層次看到數據是如何聚合在一起的,但之前還需要解決一個問題:車輛信息、信用信息還有遺留系統的客戶信息都是分別保存在關系數據庫和合作方的Web Service中,如何連接起這個數據渠道呢?從現在看XML還是不錯的選擇。
不同數據介質上的數據可以以他們本源的形式提取,比如平文本、關系數據庫、EDI報文或者是SOAP消息,通過不同的信息渠道傳遞到數據集成的匯聚點,然後根據目的數據源的需要,通過一個適配器轉換異構的數據源。
這時候如果為每兩種類型都設計一個點對點的適配器,整體規模將沿著N^2級的趨勢發展,為此不妨先把他們統一為兼容這些信息的XML,然後用上面介紹的XSLT技術進行數據實體間的映射後,接著把XML再轉換成目標數據源所需的形式,這樣整個適配體系復雜度降為N級。
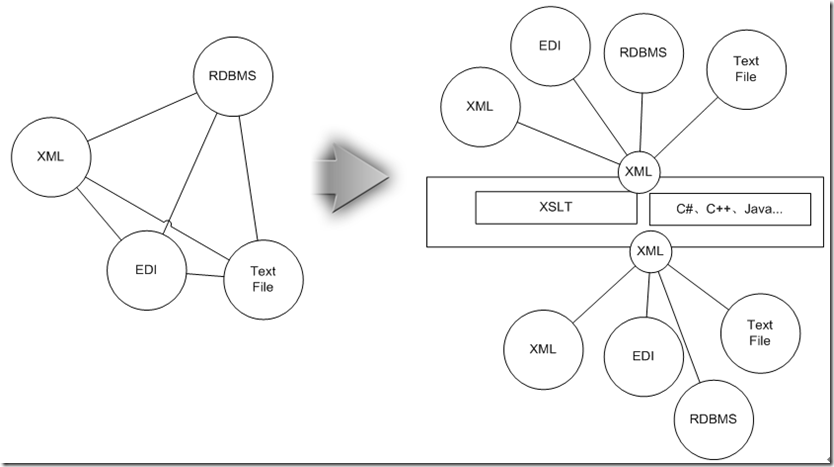
接著,我們看看XML技術如何滿足只前提的那些數據集成要求:
l 數據實體的映射、數據介質、數據載體的轉換、數據實體的驗證和重構:
如上,先把數據統一轉換為XML,然後通過XML層次型優勢,結合XML專用技術進行處理。
l 數據源的在各種交換協議、行業數據標准、安全控制約束下的互聯;
XML數據不僅可以跨越網絡、防火牆,而且可以很容易的用於互聯網環境(,不過您依然可以用消息隊列方式把他們定義為報文),數據本身不會因為特殊的二進制操作需要受到交換協議的限制。當前,各個行業標准基本上都在使用XML描述自己的行業DM(Data Modal),即便您企業內部的系統本身數據實體由於數據庫設計、歷史遺留等問題,本身不是符合這些DM的數據,但各種XML數據統一治理的協議和標准可以比較方便的實現轉換。對於安全性,似乎還有沒比基於WS-*相關協議更適合於互聯網環境下的安全標准家族,其中所有的標准無一例外都可以用XML實體定義數據和額外安全機制間的組合關系。
l 數據交換過程的編排;
對於同構系統環境,或者是僅僅基於兼容中間件系統的平台,可以采用遺留的工作流機制實現數據交換過程的編排,但為了適應服務化的時代,可以采用更通用的BPEL標准,此時XML不僅僅是數據,同時他也作為執行指令的形態出現,相比較一直標榜跨平台的Java技術而言,采用XML定義的交換過程更是跨語言的。
似乎集成已經解決了很大的問題,但一個顯而易見的問題是所有的工作我們可能都要自己做一些實現,一步步告訴應用怎麼做,那麼當我們不再把Web僅僅當成“新鮮事物”,而把它考慮成一個服務於我們信息內容,並且可以交互的系統時,如何把這些散落的服務能力呈遞給我們自己呢?這時候也許XML開放的元數據定義的優勢才真正體現出來。
應對語義網絡的復雜性
除去各種語義算法以外,如何讓分散的各種繁多的服務聚合在一起為我們提供服務,其中XML一個非常關鍵的因素就是找到數據線索的主干,而且明確這條主干上實體間的關聯關系及其逐步分解細化的過程。這個層次的數據不僅是被動由應用調用的對象,他們本身為應用共了進一步推斷的支持。例如:
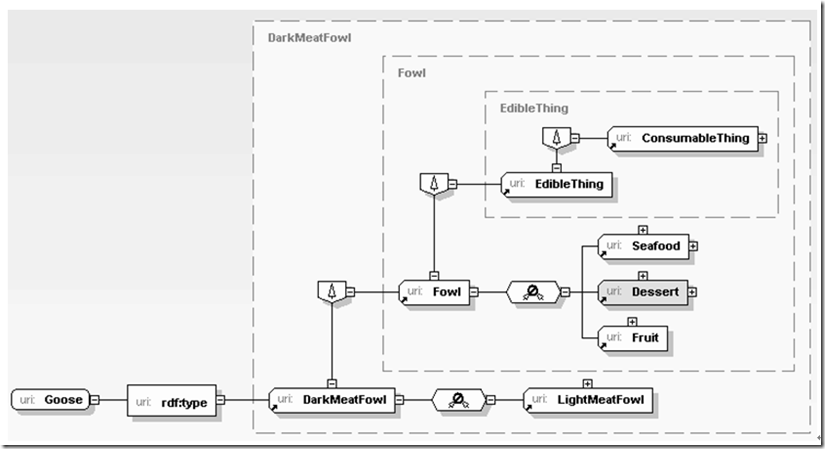
這裡首先應用了解到當前處理的這個對象是鵝肉,由於鵝肉是一種黑肉,而黑肉是某種禽肉(fowl),禽肉可以食用,因此應用可以逐步推斷鵝肉可以食用。上面的推斷過程並不復雜,但如果用關系數據庫實現卻相對比較復雜,用平文本書寫那就更難於實現了,試想一下如果同時把禽肉與蔬菜、甜點、海產品間的關系全部用關系數據庫或文本書寫,那實在太“難為”應用了。而XML不同,它可以很自然的貼近我們思維的習慣,以一種開放但又交織的辦法描述我們熟悉的語義,無論是企業ERP環境的生產材料准備過程,還是為了一次生日Party准備自己下廚的采購計劃,亦然。
小結
也許受限於二維格子的約束太久,我們對於應用的設計和想法越來越桎梏於計算機的處理本身,但隨著業務環境的變化,從業務需求發生到應用實現並上線的間隔越發短促,我們要更多把自己的思維重新從計算機中抽回來,這時候采用一種更開放並貼近我們發散型思維的數據技術似乎更可取。對於數據落地後的組織,我們可以繼續采用各種成熟的技術完成,但在更貼近業務的層面、貼近這種更易變的環境下,似乎XML柔性和力道都不錯。