Google 的 Sitemap 服務最近在 XML 社區引起了一些波瀾,它要求發布的所有站點地圖必須采用 Unicode 的 UTF-8 編碼。Google 甚至不允許其他 Unicode 編碼(如 UTF-16),更不用說 ISO-8859-1 這樣的非 Unicode 編碼了。從技術上說,這意味著 Google 使用的是非標准 XML 解析器,因為 XML Recommendation 特別要求“所有 XML 處理程序必須接受 Unicode 3.1 的 UTF-8 和 UTF-16 編碼”,但這確實是一個大問題嗎?
每個人都能使用 UTF-8
普遍性是選擇 UTF-8 的第一個也是最有說服力的理由。它可以處理目前世界上使用的每一種文字。雖然還有少數空白,但是越來越不明顯,被逐漸填平了。沒有納入的文字通常也沒有其他任何字符集實現過,即使有也不能在 XML 中使用。最好的情況下,這些文字通過字體借用轉嫁到 Latin-1 這樣的單字節字符集。對這類稀有文字的真正支持可能最先來自 Unicode,而且可能只有 Unicode 支持它們。
但這僅僅是使用 Unicode 的一個理由。為什麼選擇 UTF-8 而不是 UTF-16 或者其他 Unicode 編碼呢?最直接的原因之一是廣泛的工具支持。基本上所有可能用於 XML 的主要編輯器都能處理 UTF-8,包括 JEdit、BBEdit、Eclipse、eMacs 甚至 Notepad。在 XML 和非 XML 工具中,沒有其他 Unicode 編碼擁有這樣廣泛的工具支持。
對於其中一些編輯器,如 BBEdit 和 Eclipse,UTF-8 並不是默認的字符集。現在有必要改變默認設置了,所有工具出廠的時候都應該選擇 UTF-8 作為默認編碼。除非這樣,否則當文件跨越國界、平台和語言傳遞的時候,我們就會陷入不能互操作的泥潭。不過在所有程序都把 UTF-8 作為默認編碼之前,自己修改默認設置也很容易。比如在 Eclipse 中,圖 1 所示的“General/Editors”首選項面板允許指定所有文件都使用 UTF-8。您可能注意到 Eclipse 希望默認值為 MacRoman,但是如果這樣,當把文件傳遞給使用 Microsoft® Windows® 的程序員或者美國和西歐之外的計算機時將無法編譯。
圖 1. 改變 Eclipse 的默認字符集
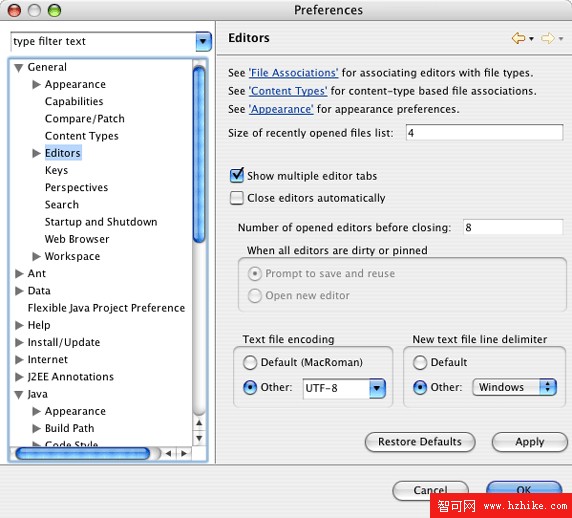
當然,要讓 UTF-8 其作用,開發人員交換的文件也都必須使用 UTF-8,但這不成問題。與 MacRoman 不同,UTF-8 不局限於少數文字或者個別平台。任何人都能用 UTF-8。而 MacRoman、Latin-1、SJIS 和其他各種遺留的國家字符集都不能做到。
UTF-8 在不支持多字節數據的工具中也能正常工作。其他 Unicode 格式如 UTF-16 往往包含很多零字節。很多工具將這些字節解釋為文件尾或者其他某種特殊的分界符,造成不希望的、未曾預料到的、常常是不愉快的結果。比方說,如果 UTF-16 數據原樣加載到 C 字符串中,字符串可能從第一個 ASCII 字符的第二個字節截斷。UTF-8 文件僅在確實表示 null 的地方包含 null。當然,不應該選擇這麼天真的工具來處理 XML 文檔。但是,遺留系統中文檔常常在奇怪的地方結束,沒有人真正認識到或者理解那些字符序列僅僅是舊瓶裝新酒。與 UTF-16 或其他 Unicode 編碼相比,對於不支持 Unicode 和 XML 的系統,UTF-8 更不容易造成問題。
專家們的說法
XML 是第一個全面支持 UTF-8 的重要標准,但這僅僅是開始。各標准組織都在逐漸推薦 UTF-8。比如,包含非 ASCII 字符的 URL 是長期困擾 Web 的一個問題。在 PC 機上工作的包含非 ASCII 字符的 URL 不能用於 Mac,反之亦然。萬維網聯盟(W3C)和 Internet 工程任務組(IETF)最近同意所有 URL 都必須采用 UTF-8 編碼而不能是其他編碼,從而解決了這一問題。
W3C 和 IETF 對最先、最後還是偶爾使用 UTF-8 變得越來越強硬。The W3C Character Model for the World Wide Web 1.0: Fundamentals 指出,“如果必須選擇一種字符編碼,則必須是 UTF-8、UTF-16 或 UTF-32。US-ASCII 對 UTF-8 向上兼容(US-ASCII 字符串也是 UTF-8 字符串,參見 [RFC 3629]),因此如果需要與 US-ASCII 保持兼容,UTF-8 非常合適。”事實上,與 US-ASCII 兼容如此重要,幾乎是必需的。W3C 明智地解釋說,“其他情況下,如對於 API,UTF-16 或 UTF-32 可能更合適。選擇一種編碼的原因可能包括內部處理的效率以及與其他進程的互操作性。”
我同意內部處理的效率這條理由。比如,Java™ 語言中字符串的內部表示采用 UTF-16,因此對字符串的索引更快。不過,Java 代碼永遠不會把這種內部表示向與它交換數據的程序公開。相反,對於外部數據交換,要使用 Java.io.Writer,明確地指定字符集。選擇的時候,強烈推薦 UTF-8。
IETF 甚至更加明確。The IETF Charset Policy [RFC 2277] 指出,在沒有不確定性的語言中:
協議必須能夠使用 UTF-8 字符集,它由 ISO 10646 編碼集和 UTF-8 字符編碼方法組成,全文參見 [10646] Annex R(修正版 2 中發布)。
此外,協議可以規定如何使用其他 ISO 10646 字符集和字符編碼方案,如 UTF-16,但是不能使用 UTF-8 是對本策略的違反,這種違反在進入或者提升到標准跟蹤過程時,需要經過變更程序([BCP9] 第 9 節),並在協議規范文檔中提出明確、可靠的理由。
現有的協議或者從已有數據存儲轉移數據的協議,可能需要支持其他數據集,甚至使用 UTF-8 之外的默認編碼。這是允許的,但是必須能夠支持 UTF-8。
要點:今後一段時間,對遺留協議和文件的支持可能要求接受 UTF-8 之外的字符集和編碼,但是如果必須如此我會非常小心。每種新的協議、應用程序和文檔都應該使用 UTF-8。
中文、日文和韓文
一種常見的誤解是認為 UTF-8 是一種壓縮格式。其實並非如此。與其他 Unicode 編碼特別是 UTF-16 相比,在 UTF-8 中 ASCII 字符占用的空間只有一半。不過一些字符的 UTF-8 編碼占用的空間要多出 50%,特別是中文、日文和韓文(CJK)這樣的象形文字。
但即使用 UTF-8 編碼 CJK XML,實際的大小可能也比 UTF-16 小。比如,中文的 XML 文檔包含大量 ASCII 字符,如 <、>、&、=、"、' 和空格。這些字符的 UTF-8 編碼要比 UTF-16 小。具體的壓縮/膨脹因素因文檔而異,但不論哪種情況,差別都不可能很明顯。
最後,值得一提的是中文和日文這類象形文字,與 Latin、Cyrillic 這類字母文字相比,用字往往更少。由於字符的絕對量很大,要求每個字符使用三個或更多字節才能完全地表達這些文字,就是說,與英文或俄文相比,同樣的詞語或句子,這些語言可以用更少的字表達。比如,“tree”在日文中用“木”表示(非常像一棵樹)。 用 UTF-8 表示需要三個字節,而英文單詞“tree”包含四個字母,需要四個字節。日文中的“grove(小樹林)”是“林”(兩棵樹靠在一起)。用 UTF-8 編碼需要三個字節,而英文單詞“grove”有五個字母,需要五個字節。日文中的“森”(三棵樹)仍然需要三個字節。而對應的英文字“forest”需要六個字節。
如果確實需要壓縮,則使用 zip 或 gzip。壓縮後,UTF-8 和 UTF-16 的大小差不多,不論原始大小相差多少。無論哪種編碼,原始大小越大,壓縮算法去掉的冗余就更多。
健壯性
真正的優勢在於設計,與以前和以後設計的其他任何文本編碼相比,UTF-8 是一種更健壯、更容易解釋的格式。首先,與 UTF-16 相比,UTF-8 沒有 endianness 問題。UTF-8 用 Big-endian 和 little-endian 來表示都是一樣的,因為 UTF-8 是按 8 位字節而不是 16 位字定義的。UTF-8 沒有字節序的不確定性問題,後者必須通過字節序標志或其他試探手段來解決。
UTF-8 更重要的一個特征是無狀態性。UTF-8 流或序列中的每個字節都是明確的。在 UTF-8 中總是可以知道所處的位置,就是說給定一個字節,馬上就能確定它是一個單字節字符、雙字節字符的第一個字節、雙字節字符的第二個字節,或者三字節/四字節字符的第二個、第三個或第四個字節(當然還有其他可能性,但明白這個意思就行)。在 UTF-16 中,就不能確定字節“0x41”是不是字母“A”。有時候是,有時候不是。必須記錄足夠的狀態才能確定在流中的位置。如果損失了一個字節,此後的數據就全部無法用了。在 UTF-8 中,丟失或者破壞的字節很容易確定,也不會影響其他數據。
UTF-8 並非是萬能的。需要隨機訪問文檔特定位置的應用程序使用 UCS2 或 UTF-32 這類固定寬度的編碼可能操作起來更快。(如果考慮到替換對,UTF-16 是一種變長字符編碼。)但是,XML 處理不屬於這類應用程序。XML 規范特別要求解析器從 XML 文檔的第一個字節開始解析直到最後一個字節,所有現有的解析器都是這樣操作的。更快的隨機訪問對 XML 處理沒有什麼幫助,雖然對於數據庫或其他系統使用不同的編碼這可能是一個很好的理由,但不適用於 XML。
結束語
在越來越國際化的世界中,語言和政治邊界日漸模糊,依賴於地域的字符集不再適用了。Unicode 是惟一能夠跨越很多地域互操作的字符集。UTF-8 是最好的 Unicode 編碼:
廣泛的工具支持,包括與遺留 ASCII 系統最佳的兼容性。
處理起來簡單而高效。
抗訛誤。
平台獨立。
該停止關於字符集和編碼的爭論了,選擇 UTF-8,結束紛爭。