簡介
據 Morgan Stanley 於 2008 年 3 月的一份報告《互聯網趨勢》(Internet Trends)中指出,從 2007 年 1 月至 2008 年 1 月期間,互聯網應用明顯從企業應用( Business )轉向個人應用( Consumer ),在 2008 年個人應用的訪問量已經趕上企業應用,而且預計到 2011 年個人應用的訪問量將可能達到企業應用的 2 倍左右。這其中增長最快速的是社會關系網(Social Networks),其增長速度接近 60%。人們花在社會關系網的時間約占 16%,而這一領域在 3 年前是不存在的。報告還引用了 Alex 流量排名,2007 年名不見經傳的 facebook 網站(http://www.facebook.com)在 2008 年一躍挺進到第六名。Facebook 的用戶數目比上年增長率達到了 305%。
社會關系網絡是一種新興的網絡應用,其中典型的有上文提到的 facebook 網站以及國內的“海內”網(www.hainei.com),它為我們提供了一個和知己保持聯系及密切溝通的平台,我們可以和所有的朋友、同事、同學共享生活的點滴,也可以結識新朋友,或許還可以找到多年未謀面的老朋友。像 facebook 這樣的大型社會關系網站,通常提供一些應用程序,如查找朋友功能以及共享相冊、視頻、事件簿等。本文中僅專注於解決人與人之間的關系,即如何組織和管理社會關系網絡的數據,開發相關的應用程序。
由於社會關系網絡的復雜性,其數據建模方式如果采用關系模型則相當復雜,而 XML 是以層次化的樹狀結構、通過元素(element)與屬性(attribute)來存儲數據,這就使得 XML 模型比關系型模型更加便捷,而且更易於擴展。同時,DB2 V9.5 的 pureXML 為以 XML 模型支撐的應用系統提供了強大的支持。
建模
這裡,先設定一些社會關系中的常見問題,並在下文中一一解決。
在這個圈子裡,誰最受歡迎?
如何找到我的同學?
如何找到我的同事?
誰和我有共同的興趣愛好?
誰是我們共同的朋友?
總體上來看,社會關系主要需要考慮兩個要素,一個是人,另一個是人與人之間的關系。
如果采用傳統的關系型建模方式,對於人這個實體就需要有若干表來描述,例如人員基本信息,人員住址,人員愛好等等。而隨著不同類型的人參與進來,例如已經參加工作的人,那麼將要增加一張數據表來描述從業情況以及以往工作經歷。人與人之間的關系也需要多張數據表來描述,一張數據表描述誰和誰之間有關系,另一張數據表描述這兩個人之間有哪些關系。如果在初期沒有仔細考慮的話,那麼在後期應對變化時則相當被動。
而采用 DB2 pureXML 則可以從更宏觀的角度來確立數據模型。
人是一個對象,那麼創建一張包含 XML 字段 PERSON 表,建表命令如清單 1 所示。
清單 1. PERSON 表結構
create table person (person_info XML);
人員關系是一個對象,創建一張包含 XML 字段的 FRIENDSHIP 表,建表命令如清單 2 所示。
清單 2. FRIENDSHIP 表結構
create table friendship (frIEndship_info XML);
至於每個人的特性如何多樣,人與人之間的關系多麼復雜,則由 XML 字段來描述,從而達到快速完成總體建模的目的。
完成了總體的建模,現在來看看 person 內部結構應該是怎樣的。
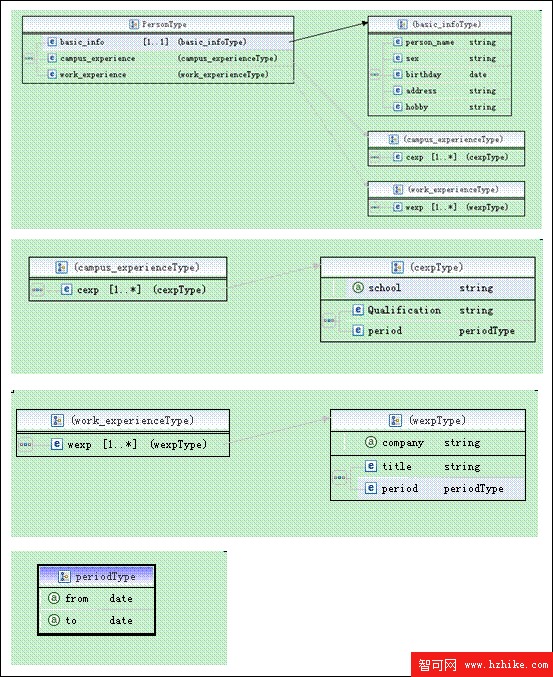
首先,每個人應該有一個唯一標識。由於唯一標識不可能重復出現在一個 XML 文檔中,因此可以放在 XML 文檔的屬性上。
其次,每個人的信息可以用多個段落標識,比如基本信息 (basic_info),學習經歷 (campus_experience),工作經歷 (work_experIEnce) 等。
人員的基本信息中可以存放人員姓名、性別、是否已婚、生日、聯系地址、電話等,可以有多份學習經歷和工作經歷的信息,如圖 1 的 schema 所示。完整的 schema 文件請參考附件內容。
當然,隨著系統的日漸完善,可以陸續加入一些新的信息或模塊,例如對學習經歷,可以把課程都加進去,某課程由某位教師授課等等;增加參加某俱樂部的信息等等。不管如何變動,都不會對外層的模型產生較大影響。這裡僅為說明,不做深入討論。
清單 3 給出了一個人員信息的示例 XML 文檔。
圖 1. 人員信息的 Schema 描述
清單 3. 人員信息的示例 XML 文檔
<?XML version="1.0" encoding="UTF-8"?>
<person pid=””>
<!-- 基本信息 -->
<basic_info>
<person_name>…</person_name>
<sex>…</sex>
<birthday>…</ birthday>
<address>…</address>
<hobby>…</hobby>
</basic_info>
<!-- 教育背景 -->
<campus_experIEnce>
<cexp school=””>
<qualification>…</qualification>
<period from=”…” to=”…”/>
</cexp>
</ campus_experIEnce>
<!--工作經歷 -->
<work_experIEnce>
<wexp company=””>
<title>…</title>
<period from=”…” to=”…”/>
</wexp>
</work_experIEnce>
<!--工作經歷 -->
…
</person>
在真實的場景,一些輔助表也是必不可少的,例如人與人之間關系類型(是朋友,同學還是同事等)、工作單位、學校,本文僅添加關系類型輔助表如清單 4,而對工作單位信息和學校信息直接以名稱表示。感興趣的讀者可以自行創建這些表,並在人員的 XML 信息中以 id 替換名稱作為關聯。
清單 4. FRIENDTYPE 表結構
create table frIEndType (type_id int NOT NULL,type_name varchar(255));
數據庫表和演示數據
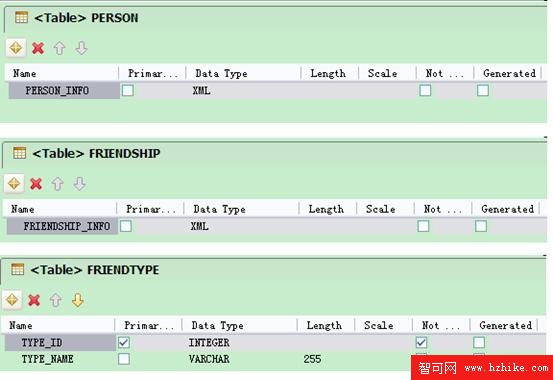
綜合以上建模過程,我們得到了以下數據表:PERSON 表、FRIENDSHIP 表和 FRIENDTYPE 表,如圖 2 所示。
圖 2. 表結構概覽
為了演示如何解決本文開頭提出的問題,我們構造如下數據:
6 個人員 p1、p2、p3、p4、p5 和 p6,其中各個人員差異性較大,有些人員有 work_experienc 元素 , 且可能包含多個子節點。而有些有包含多個子元素 campus_experIEnce 元素,另一些則可能僅有 basic_info 元素。在表 1 中,每個元素列下面的數字表示是否有該元素,0 表示沒有,1 和 2 分別表示有 1 個和 2 個該元素。
表 1. 人員數據
Person ID basic_info campus_experIEnce work_experIEnce p1 1 1 2 p2 1 1 1 p3 1 0 1 p4 1 2 0 p5 1 0 1 p6 1 0 0同時,還為這 6 個人設置了互相之間的關系,如表 2 所示(用√表示兩個人之間有關系)。以人員 p1 為例,他與 p2、p3 和 p4 有關系,用 XML 描述如清單 5 所示。
表 2. 人員相互關系設定
P1 P2 P3 P4 P5 P6 P1 √ √ √ P2 √ √ P3 √ √ P4 √ √ √ √ P5 √ √ P6 √ √清單 5. 用 XML 描述 p1 和其他人的關系
<?XML version="1.0" encoding="UTF-8"?>
<frIEndship my_id="p1">
<friend id="p2" frIEndtype="1"/>
<friend id="p3" frIEndtype="2"/>
<friend id="p4" frIEndtype="3"/>
</frIEndship>
其中 friendtype 屬性標識關系的類別,具體的定義在 frIEndtype 表中描述,如普通朋友,同事,同學等。完整的數據請參考附件。
解決問題
現在回到文章前面提到的若干問題,並討論如何解決。
1. 在這個圈子裡,誰最受歡迎?
這個問題在技術上等同於:“誰的朋友最多?”,也就是要查找 frIEndship 表,並將朋友個數以逆序排序,並打印出來其名稱。
將該問題分解為 2 個步驟: 1) 對朋友個數進行排序 2)找出來對應的人的名稱。
在 XPath 規范中有 fn:count() 函數可以完成個數統計工作,對應的 XPath 表達式為 /friendship/fn:count(frIEnd),由於 xmlquery() 選擇出來的是一個 XML 片段,因此需要使用 XMLcast() 做一個轉換,使之能夠被 SQL 語句的 order by 使用,如清單 6 所示。
清單 6. 排序代碼片段
ORDER BY XMLCAST(XMLQUERY('$d/friendship/fn:count(frIEnd)'
PASSING T.FRIENDSHIP_INFO AS "d"
) AS INT
)
DESC
第二個步驟,在查找的時候,則需要和 person 表做關聯,如清單 7 所示。
清單 7. 過濾代碼片段
WHERE XMLEXISTS('$p/person[fn:data(@pid)=$t/frIEndship/fn:data(@my_id)]'
PASSING P.PERSON_INFO AS "p",
T.FRIENDSHIP_INFO AS "t")
綜合起來查詢語句如清單 8 所示。
清單 8. 問題 1 的完整查詢代碼
SELECT
XMLQUERY('$d/person/basic_info/person_name/text()'
PASSING P.PERSON_INFO AS "d") AS NAME,
XMLCAST(XMLQUERY('$d/friendship/fn:count(frIEnd)'
PASSING T.FRIENDSHIP_INFO AS "d") AS INT
) FRIENDCOUNT
FROM PERSON P, FRIENDSHIP T
WHERE XMLEXISTS('$p/person[fn:data(@pid)=$t/frIEndship/fn:data(@my_id)]'
PASSING P.PERSON_INFO AS "p",
T.FRIENDSHIP_INFO AS "t")
ORDER BY XMLCAST(XMLQUERY('$d/friendship/fn:count(frIEnd)'
PASSING T.FRIENDSHIP_INFO AS "d"
) AS INT
)
DESC
執行後的結果清單 9 所示,可以看出王五的朋友最多,即王五在這個圈子裡最受歡迎。
清單 9. 問題 1 的查詢輸出結果
NAME FRIENDCOUNT
-------- -----------
王五 4
黃耀華 3
張三 3
李四 2
馬六 2
5 條記錄已選擇。
2.如何找到我的同學?
現在要為 p2( 張三 ) 找到他的同學,邏輯上應該針對他的每一個教育經歷找出來同一個學校且入學時間相同的人(此處不考慮專業,讀者可以自行添加此條件)。
將問題分解為三部分:
1) 根據指定的 id (“p2”) 取得該人員的 XML 數據,並取出其教育經歷;
2) 從人員表中查詢,找出和該人員的學校以及入學時間相同的人員;
3) 返回這些人員列表。
清單 10. 問題 2 的 XQuery 查詢語句
xquery
let $p :=db2-fn:XMLcolumn("PERSON.PERSON_INFO")/person[data(@pid)="p2"]
for $ep in $p/campus_experIEnce/cexp
for $f in db2-fn:XMLcolumn("PERSON.PERSON_INFO")/person
where $f/campus_experIEnce/cexp[data(@school)=$ep/data(@school)
and ./period/data(@from)=$ep/period/data(@from)]
and $f/data(@pid)!="p2"
return $f
從而可以取得 p2 的同學列表如清單 11 所示。
清單 11. 問題 2 的查詢輸出結果
<person pid="p4">
<basic_info>
<person_name>王五</person_name>
<address>北京市海澱區上地東路一號</address>
<hobby>游泳</hobby>
</basic_info>
<campus_experIEnce>
<cexp school="THU">
<period from="2000-09-01" to="2004-07-31" />
</cexp>
<cexp school="CAS">
<period from="2004-09-01" to="2007-07-31" />
</cexp>
</campus_experIEnce>
</person>
3. 如何找到我的同事?
這個場景和找同學是類似的,我們在這裡采用了不同於問題 2 中的 XQuery 的實現方式,用如清單 12 所示的 SQL/XML 語句。具體語法不在此贅述,請參考相關教程或信息中心。
清單 12. 問題 3 的 SQL/XML 語句
SELECT
XMLQUERY('$d/person/data(@pid)' PASSING P.PERSON_INFO AS "d") PID,
XMLQUERY('$d/person/basic_info/person_name/text()'
PASSING P.PERSON_INFO AS "d") NAME
FROM PERSON P
WHERE
XMLEXISTS(
'for $wexp in $p/person/work_experIEnce/wexp
for $myjob in
db2-fn:XMLcolumn("PERSON.PERSON_INFO")
/person[data(@pid)=$myid]
/work_experIEnce/wexp
where $wexp/data(@company)=$myjob/data(@company)
return $wexp/data(@company)'
PASSING P.PERSON_INFO AS "p", 'p2' AS "myid")
結果如清單 13 所示。
清單 13. 問題 3 的查詢輸出結果
PID NAME
--------------------------------------------------------
p1 黃耀華
p2 張三
2 條記錄已選擇。
4.誰和我有共同的興趣愛好?
這個問題和以上問題的解決是類似的,留給讀者自己作為練習。
5.誰是我們共同的朋友?
找出來共同的朋友是比較有意思的一件事。在 pureXML 中查找 p1 和 p2 的共同朋友,只需要針對 p1 的每一個朋友,和 p2 的每一個朋友逐一進行比較,如果其 id 相同,則返回。查詢語句如清單 14 所示。
清單 14. 問題 5 的 XQuery 查詢
xquery
for $i in db2-fn:XMLcolumn("FRIENDSHIP.FRIENDSHIP_INFO")
/friendship[data(@my_id)="p1"]/frIEnd
for $j in db2-fn:XMLcolumn("FRIENDSHIP.FRIENDSHIP_INFO")
/friendship[data(@my_id)="p2"]/frIEnd
where $i/data(@id)=$j/data(@id)
return $i;
輸出結果清單 15 所示,p4 是 p1 和 p2 的共同朋友。
清單 15. 問題 5 的查詢輸出結果
<friend id="p4" frIEndtype="3"/>
1 條記錄已選擇。
至此,我們已經完成了建模、建數據表以及設計演示數據,並解決了文章開始時所提出來的所有問題。在實際的社會關系網絡應用程序開發過程中,我們將會面對更加復雜的數據和更多的問題,但是我們基本上都可以上述的方法進行處理。
總結
作為新興的互聯網應用,社會關系網絡具有廣闊的發展空間,也正在吸引著各方面的注意力,而 IBM 的 DB2 pureXML 技術在解決這種社會關系網絡的應用問題中,有著獨到的價值。希望讀者能夠從本文中獲得一些啟發。
- 上一頁:通過 Data Web Services 使用面向 pureXML 的 Universal Services
- 下一頁:DB2 與 Ruby on Rails,第 2 部分: DB2 的 pureXML 特性與 Ruby on Rails