教學是一種令人難以置信的學習體驗。我在公司的培訓課程和有關會議上為開發人員講授 XML 和 XSLT,經常發現為了向學員澄清一個復雜的問題所作的努力使我自己加深了對問題的理解。我不僅僅是在教我的學員,也是在教我自己。
另外,學員也會帶來自己獨到的觀點,常常迫使我重新思考問題的某些方面並得出新的結論。本文就源於這樣的一次經歷。我認識到接觸過 JSP、PHP、ASP 或 ColdFusion 的學員經常對 XSLT 抱有不正確的設想,這種設想會造成錯誤的編碼。在尋求如何澄清這一問題時,我開始思考 XSLT 處理程序(如 Xalan、Saxon 或 MSXML)到底是如何工作的。這種新的看問題的角度給了我幫助,相信對您也會有所助益。
相似性與區別
初看起來,各種 Web 開發語言之間有很多相似之處,如 JSP 或 PHP 以及 XSLT。最明顯的,它們都允許開發人員在 Html 標簽中混合編碼:JSP 使用 Java 編寫代碼,PHP 使用特別的腳本語言,而對於 XSLT 代碼則是 XSLT 名稱空間的 XML 標簽。
這種相似性隱藏了本質的區別。對於 JSP(以及 PHP、ASP 和 ColdFusion),HTML 標簽被作為文本處理。事實上,當 JASP 頁面在 servlet 中編譯時,所有的 Html 標簽都被轉移到寫語句中。基本上,標簽與代碼的混合僅僅是為了方便編寫代碼——這意味著您不需要編寫大量的寫語句。
而 XSLT 卻不是這樣。XSLT 處理程序把標簽看成是上等公民。XSLT 中的“T”代表轉換(Transformation)。轉換什麼呢?把 XML 文檔轉換成另一個 XML 文檔(Html 被認為是 XML 的一種變體),或者更准確地說,把樹轉換成其他的樹。什麼是 樹呢?想一想 W3C DOM(在 Java 技術中是 org.w3c.dom 包)。盡管出於性能的原因,現代 XSLT 處理程序內部並不使用 DOM(一個優化庫會更有效),但這樣有助於把 XSLT 看作是從一棵 DOM 樹轉換成另一棵 DOM 樹的語言。
和 JSP 或 PHP 不同,XSLT 處理程序並不是把標簽盲目地寫入輸出。相反,XSLT 處理程序的工作如下:
作為 DOM 樹(在內部,處理程序優化了 DOM,但這不影響我們的討論)加載輸入文檔。
對輸入樹進行深度優先的遍歷,這和您在編程 101 中所學的深度優先算法沒有什麼不同。
遍歷文檔的過程中,為當前節點在樣式表中選擇一個模板。
應用該模板,模板描述了如何在輸出樹中創建 0 個、1 個或多個節點。
遍歷完成時,按照輸入樹和模板中的規則生成一棵新樹(輸出樹)。
根據 Html 或者 XML 語法寫入輸出樹。
注意,也可以選擇深度優先遍歷之外的其他算法。但這裡我要強調的是 XSLT 處理程序把輸入和輸出都看作是樹。這種處理方式帶來了三種結果:
處理程序可以改變語法。根據 xsl:output 語句的值,處理程序可以按照 XML 或者 HTML 語法寫入結果。Web 開發語言不能這樣做,因為它們把 Html 標簽看作是文本,盲目地復制到輸出中。
雖然偶爾可能出錯,但處理程序盡量保證輸出是結構良好的 XML 文檔。
開發人員必須按照樹操作表達自己的問題。
下一節中我將說明這句話的含義。
深度優先的遍歷
這一節將比較兩個樣式表。第一個是典型的 XSLT 樣式表,第二個對第一個進行了改寫,以便公開所采用的深度優先遍歷算法。雖然您不會采用這種編碼風格,但它有助於解釋處理程序是如何工作的。
常規樣式表
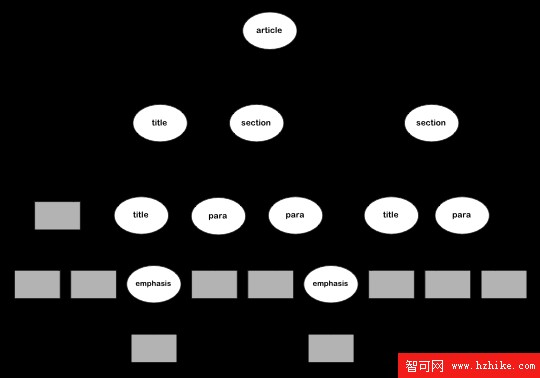
清單 1 是一個示例 XML 文檔, 圖 1是相應的 DOM 樹。 清單 2是一個簡單的樣式表,它把清單 1 轉換成 Html。
清單 1. XML 文檔
<?XML version="1.0"?>
<db:article XMLns:db="http://ananas.org/2002/docbook/subset">
<db:title>XSLT, JSP and PHP</db:title>
<db:section>
<db:title>Is there a difference?</db:title>
<db:para>Yes there is! XSLT is a pure XML technology that
traces its roots to <db:emphasis>tree manipulation
algorithms</db:emphasis>. JSP and PHP offer an ingenious
solution to combine scripting languages with Html/XML
tagging.</db:para>
<db:para>The difference may not be obvious when you're first
learning XSLT (after all, it offers tags and instructions),
but understanding the difference will make you a
<db:emphasis role="bold">stronger and better</db:emphasis>
developer.</db:para>
</db:section>
<db:section>
<db:title>How do I learn the difference?</db:title>
<db:para>Interestingly enough, you can code the XSLT algorithm
in XSLT... one cool way to experiment with the
difference.</db:para>
</db:section>
</db:article>
清單 2. 轉換成 Html 的簡單樣式表
<?XML version="1.0"?>
<xsl:stylesheet version="1.0"
XMLns:xsl="http://www.w3.org/1999/XSL/Transform"
XMLns:db="http://ananas.org/2002/docbook/subset">
<xsl:output method="Html"/>
<xsl:template match="db:article">
<Html>
<head><title>
<xsl:value-of select="db:articleinfo/db:title"/>
</title></head>
<body>
<xsl:apply-templates/>
</body>
</Html>
</xsl:template>
<xsl:template match="db:para">
<p><xsl:apply-templates/></p>
</xsl:template>
<xsl:template match="db:ulink">
<a href="{@url}"><xsl:apply-templates/></a>
</xsl:template>
<xsl:template match="db:article/db:title">
<h1><xsl:apply-templates/></h1>
</xsl:template>
<xsl:template match="db:title">
<h2><xsl:apply-templates/></h2>
</xsl:template>
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
</xsl:stylesheet>
圖 1. 處理程序所看到的 XML 文檔
遍歷算法
這一節的目標是改寫 清單 2,更加清楚地顯示深度優先遍歷算法。為此您需要一個命名模板。如果不熟悉命名模板,它們就相當於 XSLT 中的方法調用:命名模板是帶有 name 屬性的模板。它通過 xsl:param 指令接受參數,像下面這樣:
<xsl:template name="print">
<xsl:param name="message"/>
<!-- template content goes here -->
</xsl:template>
xsl:call-template 指令用於調用命名模板(而不是 xsl:apply-templates ),比如:
<xsl:call-template name="print">
<xsl:with-param name="message"
select="'See if it prints this message.'"/>
</xsl:call-template>
清單 3是對 清單 2 的改寫,它使得樹的遍歷算法更明顯。為了避免依靠處理程序操作樹,這個樣式表有一個命名模板 main 實現了樹的遍歷。 main 是一個遞歸函數,它用 current 參數接受一個節點集並遍歷該節點集。模板的主要部分是一條 choose 指令,為給定的節點尋找最適當的規則。在處理一個節點時,該模板遞歸地調用自身,以便處理該節點的孩子。
清單 3. 公開遍歷算法的樣式表
<?XML version="1.0"?>
<xsl:stylesheet version="1.0"
XMLns:xsl="http://www.w3.org/1999/XSL/Transform"
XMLns:db="http://ananas.org/2002/docbook/subset">
<xsl:output method="Html"/>
<xsl:template match="/">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="."/>
</xsl:call-template>
</xsl:template>
<xsl:template name="main">
<xsl:param name="nodes"/>
<xsl:for-each select="$nodes">
<xsl:choose>
<xsl:when test="self::db:article">
<Html>
<head><title>
<xsl:value-of select="db:title"/>
</title></head>
<body>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</body>
</Html>
</xsl:when>
<xsl:when test="self::db:para">
<p>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</p>
</xsl:when>
<xsl:when test="self::db:ulink">
<a href="{@url}">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</a>
</xsl:when>
<xsl:when test="self::db:title[parent::db:article]">
<h1>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h1>
</xsl:when>
<xsl:when test="self::db:title">
<h2>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h2>
</xsl:when>
<xsl:when test="self::db:emphasis[@role='bold']">
<b>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</b>
</xsl:when>
<xsl:when test="self::db:emphasis">
<i>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</i>
</xsl:when>
<xsl:when test="self::text()">
<xsl:value-of select="."/>
</xsl:when>
<xsl:otherwise>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
如果比較清單 2 和清單 3,就會發現它們在結構上是一致的。在 清單 2 中,巨大的 choose 指令是通過模板在幕後實現的。不需要顯式地寫上 choose 指令,但這確實是處理程序工作的方式。比較清單 2 中的模板和 清單 3中的測試條件,就會發現存在一一對應的關系。
即使清單 3 中的最後兩個測試,也通過默認模板與清單 2 對應。雖然得益於默認模板,清單 2 中不需要明確地寫出這兩個模板,處理程序確實有兩個模板,一個用於文本內容和另一個“catch-all”模板。
清單 2 中, xsl:apply-templates 指令代替了遞歸調用。在很多方面,可以認為 xsl:apply-templates 是對樣式表自身的遞歸調用!它告訴處理程序移到當前節點的孩子,並嘗試尋找另一個適用的模板。清單 3 中的循環和測試非常明顯,而在清單 2 中是由處理程序隱含完成的。在清單 3 中, 模板使用了一個額外的參數表示當前節點,而在清單 2 中,該參數是隱式的。 xsl:apply-templates 自動改變當前節點。
最後但同樣重要的一點是模板參數。在 清單 3,模板使用參數表示要處理的節點。在 清單 2,模板不需要參數,因為處理程序負責管理當前節點。當前節點總是指向模板所應用的節點。當前節點就像是一個隱式參數。
結束語
事實上,沒有人會編寫 清單 3這樣的樣式表。這個例子僅用於教學,但確實可以說明處理程序在幕後是如何工作的。通過比較清單 2 和清單 3,可以看出處理程序處理了很多基本代碼(比如循環和傳遞參數),以便實現深度優先的搜索。編寫下一個樣式表時要把這些記在腦子裡,也許您會發現它改變了您編碼的方式。
比如,不再像 XSLT 新手常做的那樣編寫這種代碼:
<xsl:template match="db:emphasis">
<xsl:choose>
<xsl:when test="@role='bold'">
<b><xsl:apply-templates/></b>
</xsl:when>
<xsl:otherwise><i><xsl:apply-templates/></i></xsl:otherwise>
</xsl:choose>
</xsl:template>
您可以改寫成下面這樣,如果考慮到處理程序的工作原理,它們是完全等價的:
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
我希望已經說明了 XSLT 處理程序的內部工作原理。很好地理解這一點對於改進您的樣式表編碼非常重要。