【編者按】本文是FREES互聯網團隊成員覃超與徐萬鴻進行的一場 Ask Me Anything。徐是前 Facebook 新聞流排序組的資深工程師,在今年9月回國出任神州專車 CTO。本文中他們聊的是關於 Facebook 的 Growth Hacking 策略、反垃圾信息系統、信息流排序,以及為什麼選擇回國參與創業。

所謂新聞流排序(news feed ranking),指的是 Facebook 的一項看家本領:用戶每天會收到兩三千條新鮮事,卻只會閱讀前 50 至 100 條。利用機器學習將用戶最想看的內容排到最前面,從而提高粘性和日活。
這固然是一篇著重技術的文章,所在公司 Facebook 更是世界上最大的互聯網公司之一。但這並不妨礙創業者從中得到經驗。利用 A/B 測試作為迭代方法,借助 Growth Hacking 的核心——數據來驅動開發,新員工的入職宣講……這些做法都體現了這位社交之王不同維度的文化所在:精神層面注重實現夢想,統一目標;而這一目標下放到微觀層面,就是對於數據的尊重。
Facebook利用Sigma 系統做了什麼?
我第一次去Facebook工作的時候,當時專注於用戶增長的 VP 負責宣講。他說將來全球所有人都會使用 Facebook,這家公司將來會成為萬億美元的公司,這讓我印象很深刻。公司的所有人都很興奮,對設定的目標有非常大的信心。他們的工作使命感非常強,非常專注。
這是Facebook給我印象深刻的一件事。
在 Facebook 的 site-integrity (站點完整性) 組工作了兩年。當時 Facebook 有很多的垃圾私信、垃圾信息,就像人人、微博上有各種廣告、垃圾鏈接。有些用戶的賬號被盜用了,會使用個人頁面發送垃圾短信、廣告、病毒,還有一些不受歡迎的朋友請求。我會處理所有類似這些涉及到影響用戶體驗的東西。
Facebook 使用了一個叫做 sigma 的系統來抵制這些垃圾信息。這個系統安裝在 2000 多台機器上面,Facebook 用戶做的任何事情,都會經過 sigma 系統分析處理,比如評論、鏈接、朋友請求,都會被這個系統進行判斷,是正常行為、濫用行為還是有問題的行為。
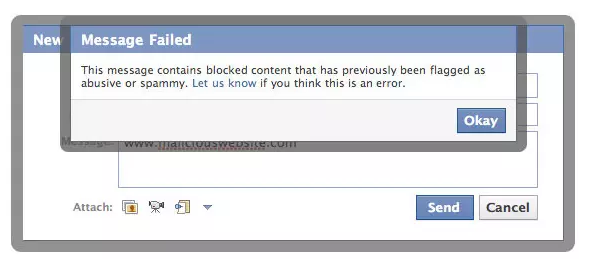
利用 Sigma 系統,Facebook 會對垃圾信息進行過濾和清理。
舉個例子說,比如發送朋友請求,Facebook 的系統會自動判斷一下:如果這個人的朋友請求都被別人拒絕了,他再發送朋友請求是不會被批准的。如果一個人發送的朋友請求十個有九個都被拒絕了,那麼他下一次的朋友請求就會被系統拒絕。
當然這個系統還有其他的判斷信號。
它是一個機器學習系統,通過你之前發的朋友請求拒絕概率高低來判斷你被拒絕的概率有多高。
如果這個比率很高,Facebook 會讓你進行手機短信或其他方式認證,來驗證是軟件還是真人發送的,以此判斷你是不是真的要發送朋友請求,比如你發出的朋友請求對象與你沒有任何共同好友,那就可能是一個不合理的請求。
基本上,你在 Facebook 上做的任何事情,都會經過這個系統來分析、預測、決定是否允許你發出信息,借此希望會減少生態圈中的騷擾行為。當時 Facebook 每天有上百億次的信息發生要通過這個系統進行判斷。
機器學習是Sigma 系統的核心
Sigma 系統中有些是人為規則也有機器算法,請求通過和拒絕就是一個迅捷數據組(Scrum)。任務通過,則說明這個任務是一個對機器學習來說的正樣本,被拒絕則是一個負樣本,很像 0 和 1。
比如發送朋友請求如果被接受,y 值是 1,如果被拒絕就是 0。如果是評論和點贊,系統就能尋找 y 值,用戶發送的不當信息就會被刪除。
而機器學習是整個 Sigma 系統的核心。
另外一個方法是通過一些異常行為的分析、數據挖掘的方法來分析用戶的異常行為。
比如一個人發的同樣類型評論非常多,所有評論裡都有一個相似鏈接,這就非常有問題。正常操作不會在不同人的主頁上留同樣的評論,這顯然屬於異常行為,我們不會允許。
新聞流是Facebook最重要的產品
我工作兩年之後選擇去了這個組。
“排序” 指的是信息流的順序。它決定了打開你的 Facebook 朋友圈,你的信息流是個什麼樣子,信息的位置。每個人產生的內容、新聞會有兩三千個,用戶只能看到 50-100 個。你需要把兩三千個最好地展示出來。有些我們不給用戶顯示,比如你喜歡游戲,你的朋友不喜歡。
我 2012 年剛去的時候,新聞流排序組只有五六個人,盡管這可能是公司最大的機器學習系統,最核心的產品。每天有十億多人上線,每個用戶花 40 分鐘在 Facebook 上,其中一半時間都花在新聞流上。Facebook 大部分收入來自新聞流廣告。比如說,移動廣告收入占所有廣告的 70%,而其中所有的移動的廣告都來自新聞流。不管是從用戶的停留時間,還是收入來說,新聞流都是最重要的產品。
- 上一頁:SEO專員,如何評估一個外鏈的價值?
- 下一頁:網站域名解析出錯了怎麼辦?