昨天在查詢網站收錄數據,看到最近一周收錄的文章有三次重復。同個網站內兩篇文章重復收錄無論是對於讀者還是對於搜索引擎都是不好的,一篇同樣文章被收錄三次,另外兩篇就成了"垃圾"了嘛,據說大量重復收錄會被搜索引擎懲罰(沒驗證過)。

點擊進入鏈接,除了原網頁,分別出現
http://www.stcash.com/5273/comment-page-1
http://www.stcash.com/5273?replytocom=1989
前面一篇文章居然出現一個三級目錄,後面一篇文章又類似於動態網頁網址。我文章中是沒有這兩個鏈接地址的,查看網頁源碼,看出了一點端倪。
我發現了這兩個?replytocom=1989網址的來源:文章評論鏈接
四個評論剛好對應四個replytocom,百度蜘蛛可能有一定的智能,四個replytocom網址中只收錄了一個,但是又不夠智能,沒有區分出來評論鏈接和原文鏈接對應的文章內容是相同的。
comment-page-1網址同樣是來源於評論鏈接,comment-page-1代表著評論頁面的第一頁。如果我的評論比較多,比如說有1000條評論,那麼一頁肯定是顯示不下去的,就會出現comment-page-2,comment-page-3......這就是評論分頁功能,這個功能本質上是防止評論過多時,網頁會被拉的很長,導致網頁加載速度慢和用戶體驗差。但是不巧的是,百度蜘蛛依然不能識別出來這和原文
解決方案
1,對於comment-page-1重復收錄,有兩種方式解決
1),在wordpress後台關閉評論分頁
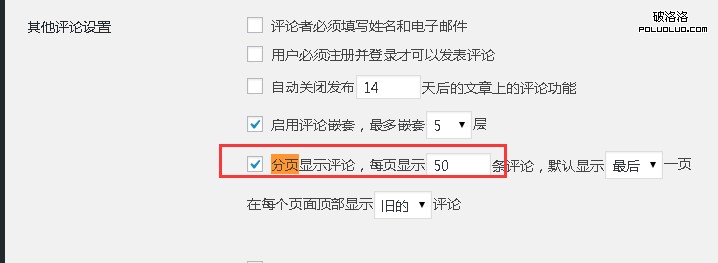
2),修改robots.txt,加上一句項目的代碼
Disallow: /comment-page-
robots.txt在網站根目錄,使用 網址/robots.tx就可以看到設置的結果了。如果根目錄下沒有這個文件
wp-includes/funtion中有這麼一段代碼:
- $output = "User-agent: *\n";
- $public = get_option( 'blog_public' );
- if ( '0' == $public ) {
- $output .= "Disallow: /\n";
- } else {
- $site_url = parse_url( site_url() );
- 上一頁:百度流量與關鍵詞工具分析
- 下一頁:京東首席搜索專家內部分享