
導讀:首先我們要了解什麼是robots文件,比如,在安徽人才庫的首頁網址後面加入“/robots.txt”,即可打開該網站的robots文件,如圖所示,文件裡顯示的內容是要告訴搜索引擎哪些網頁希望被抓取,哪些不希望被抓取。因為網站中有一些無關緊要的網頁,如“給我留言”或“聯系方式”等網頁,他們並不參與SEO排名,只是為了給用戶看,此時可以利用robots文件把他們屏蔽,即告訴搜索引擎不要抓取該頁面。
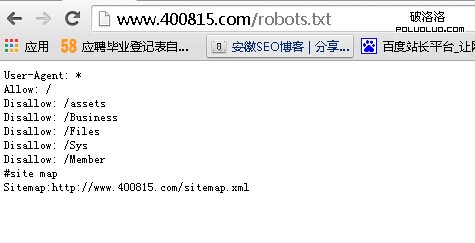
蜘蛛抓取網頁的精力是有限的,即它每次來抓取網站,不會把網站所有文章、所有頁面一次性全部抓取,尤其是當網站的內容越來越多時,它每次只能抓取一部分。那麼怎樣讓他在有限的時間和精力下每次抓取更多希望被抓去的內容,從而提高效率呢?
這個時候我們就應該利用robots文件。小型網站沒有該文件無所謂,但對於中大型網站來說,robots文件尤為重要,因為這些網站數據庫非常龐大,蜘蛛來時,要像對待好朋友一樣給它看最重要的東西,因為這個朋友精力有限,每次來都不能把所有的東西看一遍,所以就需要robots文件屏蔽一些無關緊要的東西。由於種種原因,某些文件不想被搜索引擎抓取,如處於隱私保護的內容,也可以用robots文件把搜索引擎屏蔽。
當然,有些人會問,如果robots文件沒用好或出錯了,會影響整個網站的收錄,那為什麼還有這個文件呢?這句話中的“出錯了”是指將不該屏蔽的網址屏蔽了,導致蜘蛛不能抓取這些頁面,這樣搜索引擎就不會收錄他們,那何談排名呢?所以robots問價的格式一定要正確。下面我們一起來了解robots文件的用法:
1.“user-agent:*disallow:/”表示“禁止所有搜索引擎訪問網站的任何部分”,這相當於該網站在搜索引擎裡沒有記錄,也就談不上排名。
2.“user-agent:*disallow:”表示“允許所有的robots訪問”,即允許蜘蛛任意抓取並收錄該網站。這裡需要注意,前兩條語法之間只相差一個“/”。
3.“user-agent:badbot disallow:/”表示“禁止某個搜索引擎的訪問”。
4.“user-agent:baiduspider disallow:user-agent:*disallow:/”表示“允許某個搜索引擎的訪問”。這裡面的“baiduspider”是百度蜘蛛的名稱,這條語法即是允許百度抓取該網站,而不允許其他搜索引擎抓取。
說了這麼多,我們來舉個例子,某個網站以前是做人才招聘的,現在要做汽車行業的,所以網站的內容要全部更換。刪除有關職場資訊的文章,這樣就會出現大量404頁面、很多死鏈接,而這些鏈接以前已經被百度收錄,但網站更換後蜘蛛再過來發現這些頁面都不存在了,這就會留下很不好的印象。此時可以利用robots文件把死鏈接全部屏蔽,不讓百度訪問這些已不存在的頁面即可。
最後我們來看看使用robots文件應該注意什麼?首先,在不確定文件格式怎麼寫之前,可以先新建一個文本文檔,注意robots文件名必須是robots.txt,其後綴是txt並且是小寫的,不可以隨便更改,否則搜索引擎識別不了。然後打開該文件,可以直接復制粘貼別人的格式,
Robots文件格式是一條命令一行,下一條命令必須換行。還有,“disallow: ”後面必須有一個空格,這是規范寫法。
文章有萬馬奔騰原創http://www.400815.com,轉載請注明。