在這個“內容為王”的時代,濟南東尚信息感觸最深的就是原創文章對一個網站的重要性。假如一個網站在某一段時間,如果網頁內容質量不過關,那麼直接結果就是網站被降權,網站流量下降。
雖然知道原創文章的重要性,但是大家也都知道,一篇兩篇原創文章沒有什麼大問題,如果長久的保持網站文章的原創那是一件非常艱難的事情,除非那些大型網站站長的手下有一批專職的寫手或者編輯。那麼沒有這種優渥條件的站長們怎麼辦呢?只能是偽原創與抄襲。但是偽原創與抄襲來的方法真的有用嗎?今天濟南東尚信息就來和大家分享一下搜索引擎對於重復內容判定方面的知識:
問題一:搜索引擎如何判斷重復內容?
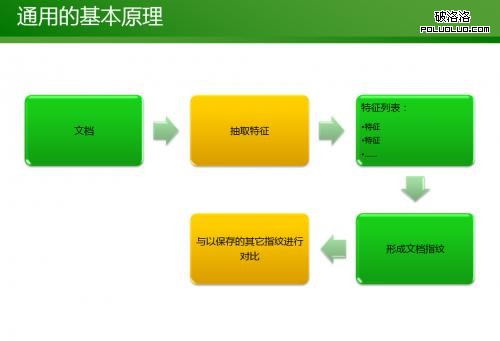
1、通用的基本判斷原理就是逐個對比每個頁面的數字指紋。這種方法雖然能夠找出部分重復內容,但缺點在於需要消耗大量的資源,操作速度慢、效率低。
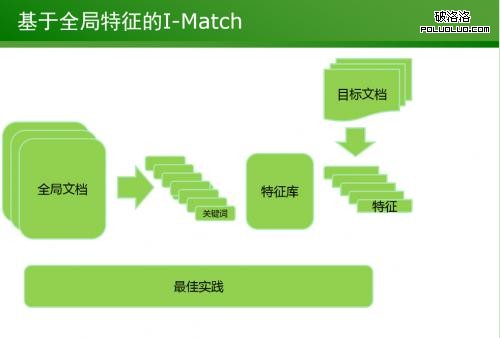
2、基於全局特征的I-Match
這種算法的原理是,將文本中出現的所有詞先排序再打分,目的在於刪除文本中無關的關鍵詞,保留重要關鍵詞。這樣的方式去重效果高、效果明顯。比如我們在偽原創時可能會把文章詞語、段落互換,這種方式根本欺騙不了I-Match算法,它依然會判定重復。
3、基於停用詞的Spotsig
文檔中如過使用大量停用詞,如語氣助詞、副詞、介詞、連詞,這些對有效信息會造成干擾效果,搜索引擎在去重處理時都會對這些停用詞進行刪除,然後再進行文檔匹配。因此,我們在做優化時不妨減少停用詞的使用頻率,增加頁面關鍵詞密度,更有利於搜索引擎抓取。

4、基於多重Hash的Simhash
這種算法涉及到幾何原理,講解起來比較費勁,簡單說來就是,相似的文本具有相似的hash值,如果兩個文本的simhash越接近,也就是漢明距離越小,文本就越相似。因此海量文本中查重的任務轉換為如何在海量simhash中快速確定是否存在漢明距離小的指紋。我們只需要知道通過這種算法,搜索引擎能夠在極短的時間內對大規模的網頁進行近似查重。目前來看,這種算法在識別效果和查重效率上相得益彰。
問題二、搜索引擎眼中重復內容都有哪些表現形式?
1、格式和內容都相似。這種情況在電商網站上比較常見,盜圖現象比比皆是。
2、僅格式相似。
3、僅內容相似。
4、格式與內容各有部分相似。這種情況通常比較常見,尤其是企業類型網站。
問題三、搜索引擎為何要積極處理重復內容?
1、節省爬取、索引、分析內容的空間和時間
用一句簡單的話來講就是,搜索引擎的資源是有限的,而用戶的需求卻是無限的。大量重復內容消耗著搜索引擎的寶貴資源,因此從成本的角度考慮必須對重復內容進行處理。
2、有助於避免重復內容的反復收集
從已經識別和收集到的內容中匯總出最符合用戶查詢意圖的信息,這既能提高效率,也能避免重復內容的反復收集。
3、重復的頻率可以作為優秀內容的評判標准
既然搜索引擎能夠識別重復內容當然也就可以更有效的識別哪些內容是原創的、優質的,重復的頻率越低,文章內容的原創優質度就越高。
4、改善用戶體驗
其實這也是搜索引擎最為看重的一點,只有處理好重復內容,把更多有用的信息呈遞到用戶面前,用戶才能買賬。
文章由濟南東尚信息(www.dongshangxinxi.com)投遞,轉載請注明出處
注:相關網站建設技巧閱讀請移步到建站教程頻道。
收藏本文