了解啟發式搜索領域及其在人工智能上的應用。本文作者展示了他們如何成功用 Java 實現了最廣為使用的啟發式搜索算法。他們的解決方案利用一個替代的 Java 集合框架,並使用最佳實踐來避免過多的垃圾收集。
通過搜尋可行解決方案空間來解決問題是人工智能中一項名為狀態空間搜索 的基本技術。 啟發式搜索 是狀態空間搜索的一種形式,利用有關一個問題的知識來更高效地查找解決方案。啟發式搜索在各個領域榮獲眾多殊榮。在本文中,我們將向您介紹啟發式搜索領域,並展示如何利用 Java 編程語言實現 A*,即最廣為使用的啟發式搜索算法。啟發式搜索算法對計算資源和內存提出了較高的要求。我們還將展示如何避免昂貴的垃圾收集,以及如何利用一個替代的高性能 Java 集合框架 (JCF),通過這些改進 Java 實現。本文的所有代碼都可以從 下載 部分獲得。
啟發式搜索
計算機科學中的許多問題可用一個圖形數據結構表示,其中圖形中的路徑表示潛在的解決方案。查找最優解決方案需要找到一個最短路徑。例如,以自主視頻游戲角色為例。角色做出的每個動作都與圖形中的一個邊緣相對應,而且角色的目標是找到最短路徑,與對手角色交手。
深度優先 搜索和廣度優先 搜索等算法是流行的圖形遍歷算法。但它們被視為非啟發式 算法,而且常常受到它們可以解決的問題規模的嚴格限制。此外,不能保證深度優先搜索能找到最優解決方案(或某些情況下的任何解決方案),可以保證廣度優先搜索僅能在特殊情況下找到最優解決方案。相比之下,啟發式搜索是一種提示性 搜索,利用有關一個問題的知識,以啟發式方式進行編碼,從而更高效地解決問題。啟發式搜索可以解決非啟發式算法無法解決的很多難題。
視頻游戲尋路是啟發式搜索的一個受歡迎的領域,它還可以解決更復雜的問題。2007 年舉行的無人駕駛汽車比賽 “DARPA 城市挑戰賽” 的優勝者就利用了啟發式搜索來規劃平坦的、直接的可行使路線。啟發式搜索在自然語言處理中也有成功應用,它被用於語音識別中的文本和堆棧解碼句法解析。它在機器人學和生物信息學領域也有應用。與傳統的動態編程方法相比較,使用啟發式搜索可以使用更少的內存更快地解決多序列比對 (Multiple Sequence Alignment, MSA),這是一個經過深入研究的信息學問題。
通過 Java 實現啟發式搜索
Java 編程語言不是實現啟發式搜索的一種受歡迎的選擇,因為它對內存和計算資源的要求很高。出於性能原因,C/C++ 通常是首選語言。我們將證明 Java 是實現啟發式搜索的一種合適的編程語言。我們首先表明,在解決受歡迎的基准問題集時,A* 的 textbook 實現確實很緩慢,並且會耗盡可用內存。我們通過重訪一些關鍵實現細節和利用替代的 JCF 來解決這些性能問題。
很多這方面的工作都是本文作者合著的一篇學術論文中發表的作品的一個擴展。盡管原作專注於 C/C++ 編程,但在這裡,我們展示了適用於 Java 的許多同樣的概念。
廣度優先搜索
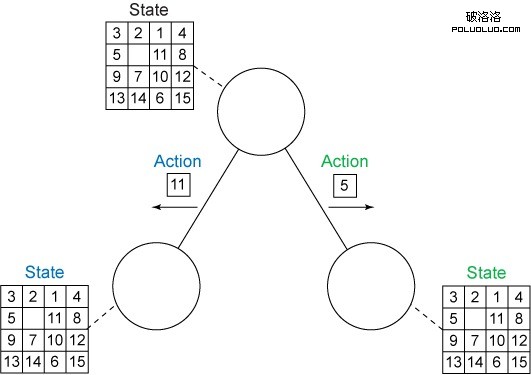
熟悉廣度優先搜索(一個共享許多相同概念和術語的更簡單的算法)的實現,將幫助您理解實現啟發式搜索的細節。我們將使用廣度優先搜索的一個以代理為中心 的視圖。在一個以代理為中心的視圖中,代理據說處於某種狀態,並且可從該狀態獲取一組適用的操作。應用操作可將代理從其當前狀態轉換到一個新的後繼 狀態。該視圖適用於多種類型的問題。
廣度優先搜索的目標是設計一系列操作,將代理從其初始狀態引導至一個目標狀態。從初始狀態開始,廣度優先搜索首先訪問最近生成的狀態。所有適用的操作在每個訪問狀態都可以得到應用,生成新的狀態,然後該狀態被添加到未訪問狀態列表(也稱為搜索的前沿)。訪問狀態並生成所有後繼狀態的過程被稱為擴展 該狀態。
您可以將該搜索過程看作是生成了一個樹:樹的根節點表示初始狀態,子節點由邊緣連接,該邊緣表示用於生成它們的操作。圖 1 顯示該搜索樹的一個圖解。白圈表示搜索前沿的節點。灰圈表示已展開的節點。
圖 1. 二叉樹上的廣度優先搜索順序
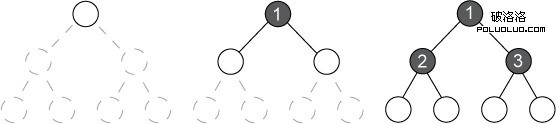
搜索樹中的每一個節點表示某種狀態,但兩個獨特的節點可表示同一狀態。例如,搜索樹中處於不同深度的一個節點可以與樹中較高層的另一個節點具有同樣的狀態。這些重復 節點表示在搜索問題中達到同一狀態的兩種不同方式。重復節點可能存在問題,因此必須記住所有受訪節點。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
1 2 3 4 5 6 7 下一頁 收藏本文
清單 1 顯示廣度優先搜索的偽代碼:
清單 1. 廣度優先搜索的偽代碼
1 2 3 4 5 6 7 8 9 10 11 12function: BREADTH-FIRST-SEARCH(initial)
open ← {initial}
closed ← 0
loop do:
if EMPTY(open) then return failure
node ← SHALLOWEST(open)
closed ← ADD(closed, node)
for each action in ACTIONS(node)
successor ← APPLY(action, node)
if successor in closed then continue
if GOAL(successor) then return SOLUTION(node)
open ← INSERT(open, successor)
在 清單 1 中,我們將搜索前沿保留在一個 open 列表(第 2 行)中。將訪問過的節點保留在 closed 列表(第 3 行)中。closed 列表有助於確保我們不會多次重訪任何節點,從而不會重復搜索工作。僅當一個節點不在 closed 列表中時才能將其添加到前沿。搜索循環持續至 open 列表為空或找到目標為止。
在 圖 1 中,您可能已經注意到,在移至下一層之前,廣度優先搜索會訪問搜索樹的每個深度層的所有節點。在所有操作具有相同成本的問題中,搜素樹中的所有邊緣具有相同的權重,這樣可保證廣度優先搜索能找到最優解決方案。也就是說,生成的第一個目標在從初始狀態開始的最短路徑上。
在某些域中,每個操作有不同的成本。對於這些域,搜索樹中的邊緣具有不統一的權重。在這種情況下,一個解決方案的成本是從根到目標的路徑上所有邊緣權重的總和。對於這些域,無法保證廣度優先搜索能找到最優解決方案。此外,廣度優先搜索必須展開樹的每個深度層的所有節點,直至生成目標。存儲這些深度層所需的內存可能會快速超過最現代的計算機上的可用內存。這將廣度優先搜索限制於很窄的幾個小問題。
Dijkstra 的算法是廣度優先搜索的一個擴展,它根據從初始狀態到達節點的成本對搜索前沿上的節點進行排序(排列 open 列表)。不管操作成本是否統一(假設成本是非負值),它都確保可以找到最優解決方案。然而,它必須訪問成本少於最優解決方案的所有節點,因此它被限制於解決較少的問題。下一節將描述一個能解決大量問題的算法,該算法能大幅減少查找最優解決方案所需訪問的節點數量。
A* 搜索算法
A* 算法或其變體是最廣為使用的啟發式搜索算法之一。可以將 A* 看作是 Dijkstra 的算法的一個擴展,它利用與一個問題有關的知識來減少查找一個解決方案所需的計算數量,同時仍然保證最優的解決方案。A* 和 Dijkstra 的算法是最佳優先 圖形遍歷算法的典型示例。它們是最佳優先算法,是因為他們首先訪問最佳的節點,即出現在通往目標的最短路徑上的那些節點,直至找到一個解決方案。對於許多問題,找到最佳解決方案至關重要,這是讓 A* 這樣的算法如此重要的原因。
A* 與其他圖形遍歷算法的不同之處在於使用了啟發式估值。啟發式估值是有關一個問題的一些知識( 經驗法則),該知識能讓您做出更好的決策。在搜索算法的上下文中,啟發式估值 有具體的含義:估算從特定節點到一個目標的成本的一個函數。A* 可以利用啟發式估值來決定哪些節點是最應該訪問的,從而避免不必要的計算。A* 嘗試避免訪問圖形中幾乎不通向最優解決方案的節點,通常可用比非啟發式算法更少的內存快速找到解決方案。
A* 確定最應該訪問哪些節點的方式是為每個節點計算一個值(我們將其稱為 f 值),並根據該值對 open 列表進行排序。f 值是使用另外兩個值計算出來的,即節點的 g 值 和 h 值。一個節點的 g 值是從初始狀態到達一個節點所需的所有操作的總成本。從節點到目標的估算成本是其 h 值。這一估算值是啟發式搜索中的啟發式估值。f 值最小的節點是最應該訪問的節點。
圖 2 展示該搜索過程:
圖 2. 基於 f 值的 A* 搜索順序
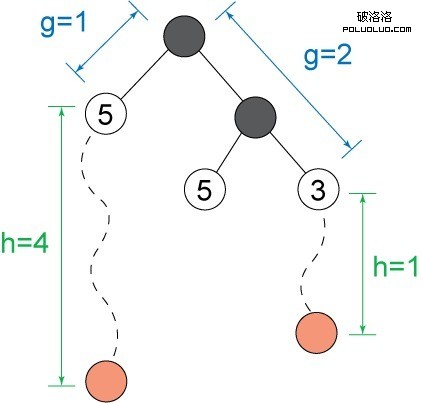
在 圖 2 的示例中,前沿有三個節點。有兩個節點的 f 值是 5,一個節點的 f 值是 3。接下來展開 f 值最小的節點,該節點直接通往一個目標。這樣一來 A* 就無需訪問其他兩個節點下的任何子樹,如圖 3 所示。這使得 A* 比廣度優先搜索等算法要高效得多。
圖 3. A* 不必訪問 f 值較高的節點下的子樹
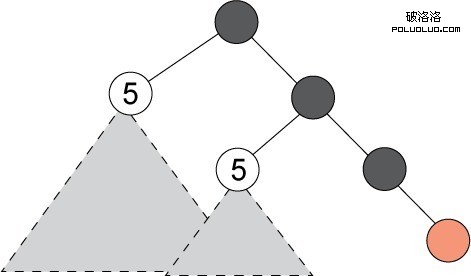
如果 A* 使用的啟發式估值是可接受的,那麼 A* 僅訪問找到最優解決方案所需的節點。為此 A* 很受歡迎。沒有其他算法能用可接受的啟發式估值,通過訪問比 A* 更少的節點保證找到一個最優解決方案。要讓啟發式估算成為可接受的,它必須是一個下限值:一個小於或等於到達目標的成本的值。如果啟發滿足另一個屬性,即一致性,那麼將首次通過最優路徑生成每個狀態,而且該算法可以更高效地處理重復節點。
與上一節的廣度優先搜索一樣,A* 維護兩個數據結構。已生成但尚未訪問的節點存儲在一個 open 列表 中,而且訪問的所有標准節點都存儲在一個 closed 列表 中。這些數據結構的實現以及使用它們的方式對性能有很大的影響。我們將在後面的一節中對此進行詳細探討。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 下一頁 收藏本文
清單 2 顯示 textbook A* 搜索的完整偽代碼。
清單 2. A* 搜索的偽代碼
1 2 3 4 5 6 7 8 9 10 11 12 13 14function: A*-SEARCH(initial)
open ← {initial}
closed ← 0
loop do:
if EMPTY(open) then return failure
node ← BEST(open)
if GOAL(node) then return SOLUTION(node)
closed ← ADD(closed, node)
for each action in ACTIONS(node)
successor ← APPLY(action, node)
if successor in open or successor in closed
IMPROVE(successor)
else
open ← INSERT(open, successor)
在 清單 2 中,A* 從 open 列表中的初始節點入手。在每次循環迭代中,open 列表上的最佳節點被刪除。接下來,open 上最佳節點的所有適用操作被應用,生成所有可能的後繼節點。對於每個後繼節點,我們將通過檢查確認它表示的狀態是否已被訪問。如果沒有,則將其添加到 open 列表。如果它已經被訪問,則需要通過一個更好的路徑確定我們是否達到了這一狀態。如果是,則需要將該節點放在 open 列表上,並刪除次優的節點。
我們可以使用有關要解決的問題的兩個假設簡化這一段偽代碼:我們假設所有操作有相同的成本,而且我們有可接受的、一致的啟發式估值。因為啟發式估值是一致的,且域中的所有操作具有相同的成本,那麼我們永遠無法通過一個更好的路徑重訪一個狀態。結果還表明,對於一些域,在 open 列表中放置重復節點比每次生成新節點時檢查是否有重復節點更高效。因此,我們可以通過將所有新後繼節點附加到 open 列表來簡化實現,不管它們是否已經被訪問。我們通過將 清單 2 中的最後四行組合為一行來簡化偽代碼。我們仍然需要避免循環,因此在展開一個節點之前,必須檢查是否有重復節點。我們可以省略掉 IMPROVE 函數的細節,因為在簡化版本中不再需要它。
清單 3 顯示簡化的偽代碼:
清單 3. A* 搜索的簡化偽代碼
1 2 3 4 5 6 7 8 9 10 11 12function: A*-SEARCH(initial)
open ← {initial}
closed ← 0
loop do:
if EMPTY(open) then return failure
node ← BEST(open)
if node in closed continue
if GOAL(node) then return SOLUTION(node)
closed ← ADD(closed, node)
for each action in ACTIONS(node)
successor ← APPLY(action, node)
open ← INSERT(open, successor)
A* 的 Java textbook 實現
本節我們將介紹如何基於 清單 3 中簡化的偽代碼完成 A* 的 Java textbook 實現。您會看到,這一實現無法解決 30GB 內存限制下的一個標准啟發式搜索基准。
我們希望我們的實現盡量大眾化,因此我們首先定義了一些接口來提取 A* 要解決的問題。我們想通過 A* 解決的任何問題都必須實現 Domain接口。Domain 接口提供具有以下用途的方法:
- 查詢初始狀態
- 查詢一個狀態的適用操作
- 計算一個狀態的啟發式估值
- 生成後繼狀態
清單 4 顯示了 Domain 接口的完整代碼:
清單 4. Domain 接口的 Java 源代碼
1
2
3
4
5
6
7
8
9
public interface Domain {
public T initial();
public int h(T state);
public boolean isGoal(T state);
public int numActions(T state);
public int nthAction(T state, int nth);
public Edge apply (T state, int op);
public T copy(T state);
}
A* 搜索為搜索樹生成邊緣和節點對象,因此我們需要 Edge 和 Node 類。每個節點包含 4 個字段:節點表示的狀態、對父節點的引用,以及節點的 g 和 h 值。清單 5 顯示 Node 類的完整代碼:
清單 5. Node 類的 Java 源代碼
1
2
3
4
5
6
7
8
9
10
11
12
class Node {
final int f, g, pop;
final Node parent;
final T state;
private Node (T state, Node parent, int cost, int pop) {
this.g = (parent != null) ? parent.g+cost : cost;
this.f = g + domain.h(state);
this.pop = pop;
this.parent = parent;
this.state = state;
}
}
每個邊緣有三個字段:邊緣的成本或權重、用於為邊緣生成後繼節點的操作,以及用於為邊緣生成父節點的操作。清單 6 顯示了 Edge 類的完整代碼:
清單 6. Edge 類的 Java 源代碼
1
2
3
4
5
6
7
8
9
10
public class Edge {
public int cost;
public int action;
public int parentAction;
public Edge(int cost, int action, int parentAction) {
this.cost = cost;
this.action = action;
this.parentAction = parentAction;
}
}
A* 算法本身會實現 SearchAlgorithm 接口,而且僅需要 Domain 和 Edge 接口。SearchAlgorithm 接口僅提供一個方法來執行具有指定初始狀態的搜索。search() 方法返回 SearchResult 的一個實例。SearchResult 類提供搜索統計。SearchAlgorithm 接口的定義如清單 7 所示:
清單 7. SearchAlgorithm 接口的 Java 源代碼
1
2
3
public interface SearchAlgorithm {
public SearchResult search(T state);
}
用於 open 和 closed 列表的數據結構的選擇是一個重要的實現細節。我們將使用 Java 的 PriorityQueue 實現 open 列表。PriorityQueue 是一個平衡的二進制堆的實現,包含用於元素入列和出列的 O(log n) 時間、用於測試一個元素是否在隊列中的線性時間,以及用於訪問隊列頭的約束時間。二進制堆是實現 open 列表的一個流行數據結構。稍後您會看到,對於一些域,可以使用一個名為桶優先級隊列 的更高效的數據結構來實現 open 列表。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 下一頁 收藏本文
我們必須實現 Comparator 接口讓 PriorityQueue 合理地對節點進行排序。對於 A* 算法,我們需要根據 f 值對每個節點排序。在許多節點的 f 值相同的域中,一個簡單的優化是通過選擇 g 值較高的節點來打破平局。試著花點時間說服自己為何以這種方式打破平局能提高 A* 的性能(提示:h 是一個估算值;而 g 不是)。清單 8 包含完整的 Comparator 實現代碼:
清單 8. NodeComparator 類的 Java 源代碼
1
2
3
4
5
6
7
8
9
10
class NodeComparator implements Comparator {
public int compare(Node a, Node b) {
if (a.f == b.f) {
return b.g - a.g;
}
else {
return a.f - b.f;
}
}
}
我們需要實現的其他數據結構是 closed 列表。對此的一個明顯的選擇是 Java 的 HashMap 類。HashMap 類是散列表的一個實現,只要我們提供一個好的散列函數,預期會有用於檢索和添加元素的恆定時間。我們必須重寫負責實現域狀態的類的 hashcode() 和 equals() 方法。我們將在下一節中探討該實現。
最後我們需要實現 SearchAlgorithm 接口。為此,我們使用 清單 3 中的偽代碼實現 search() 方法。清單 9 顯示了 A* search() 方法的完整代碼:
清單 9. A* search() 方法的 Java 源代碼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public SearchResult search(T init) {
Node initNode = new Node(init, null, 0, 0 -1);
open.add(initNode);
while (!open.isEmpty() && path.isEmpty()) {
Node n = open.poll();
if (closed.containsKey(n.state)) continue;
if (domain.isGoal(n.state)) {
for (Node p = n; p != null; p = p.parent)
path.add(p.state);
break;
}
closed.put(n.state, n);
for (int i = 0; i < domain.numActions(n.state); i++) {
int op = domain.nthAction(n.state, i);
if (op == n.pop) continue;
T successor = domain.copy(n.state);
Edge edge = domain.apply(successor, op);
Node node = new Node(successor, n, edge.cost, edge.pop);
open.add(node);
}
}
return new SearchResult(path, expanded, generated);
}
要評估我們的 A* 實現,需要對一個問題運行該實現。在下一節中,我們將描述一個用於評估啟發式搜索算法的流行域。該域中的所有操作都具有相同的成本,而且我們使用的啟發式估值是可接受的,因此我們的簡化實現是足夠的。
15 puzzle 基准
本文中,我們側重於一個名為 15 puzzle 的 toy 域。這個簡單的域有易於理解的屬性,是評估啟發式搜索算法的一個標准基准。(有人將這些拼圖稱為 AI 研究的 “果蠅”。)15 puzzle 是一種滑塊拼圖,在 4×4 網格上排列 15 個滑塊。一個滑塊有 16 個位置可供選擇,總有一個位置是空的。與空白位置相鄰的滑塊可從一個位置滑動 到另一個位置。其目的是滑動滑塊,直至達到拼圖的目標布局。圖 4 顯示了隨機布局下的滑塊拼圖:
圖 4. 15 puzzle 的隨機布局
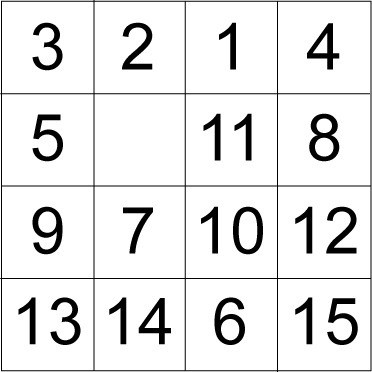
圖 5 顯示了目標布局下的滑塊:
圖 5. 15 puzzle 的目標布局
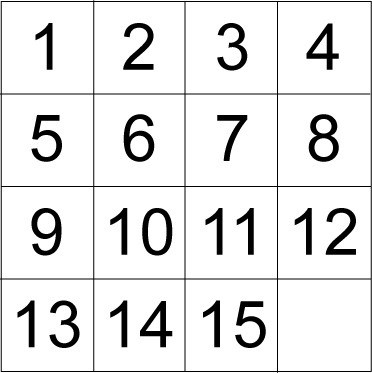
作為一個啟發式搜索基准,我們希望通過盡量少的移動從某個初始布局開始找到該拼圖的目標布局。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 下一頁 收藏本文
我們將為該域使用的啟發式算法叫作曼哈坦距離 算法。一個滑塊的曼哈坦距離是滑塊到達目標位置所需做出的垂直和水平移動數量。要計算一個狀態的啟發式估值,我們需要算出拼圖中所有滑塊的曼哈坦距離的總和,忽略空白位置。對於任何狀態,所有這些距離之和必須是達到拼圖目標狀態所需成本的下限值,因為您永遠無法通過減少移動量將滑塊移動到每個目標布局。
一開始似乎不太直觀,但我們可以用圖形建模 15 puzzle,將滑塊的每個可能布局表示為節點。如果有一個操作將一個布局轉化為另一個布局,一個邊緣連接兩個節點。在該域中,一個操作將滑塊滑到空白區域。圖 4 展示了這一搜索圖:
圖 6. 15 puzzle 的狀態空間搜索圖
有 16! 種在網格上排列 15 個滑塊的可能方式,不過實際上 “只有” 16!/2 = 10,461,394,944,000 種 15 puzzle 的可達布局或狀態。這是因為拼圖的物理約束讓我們剛好達到所有可能布局的一半。為了了解該狀態空間的大小,假設我們可以用一個字節表示一種狀態(這是不可能的)。為了存儲整個狀態空間,我們需要超過 10TB 的內存。這將遠遠超過最現代的計算機的內存限制。我們將展示啟發式搜索如何在僅訪問一小部分狀態空間的同時以最佳方式解決這個難題。
運行實驗
我們的實驗使用 15 puzzle 的一組著名起始布局,叫 Korf 100 集合。這一集合得名於 Richard E. Korf,他發布了首批結果,表明可以使用 A* 的一個迭代加深 變體,即 IDA*,解決隨機的 15 puzzle 布局。由於這些結果被發布,Korf 在其實驗中使用的 100 個隨機實例在無數隨後的啟發式搜索實驗中得到重用。我們還優化了我們的實現,因而無需再使用迭代加深技術。
我們一次解決一個起始布局。每個起始布局都存儲在一個獨立的普通文本文件中。文件的位置在啟動實驗的命令行參數中指定。我們需要一個 Java 程序入口點來處理命令行參數,生成問題實例,並運行 A* 搜索。我們將這個入口點稱為 TileSolver 類。
在每次運行結束時會將有關搜索性能的統計數據打印為標准輸出。我們最感興趣的統計數據是掛鐘時間(wall clock time)。我們將所有運行的掛鐘時間加起來,得出該基准測試的總運行時間。
本文 源代碼 包含自動完成實驗的 Ant 任務。您可以使用以下代碼運行整個實驗:
1ant TileSolver.korf100 -Dalgorithm="efficient"
可以為 algorithm 指定 efficient 或 textbook。
我們還提供一個 Ant 目標來運行單一實例。例如:
1ant TileSolver -Dinstance="12" -Dalgorithm="textbook"
而且我們提供一個 Ant 目標來運行基准測試子集,其中不包括三個最難的實例:
1ant TileSolver.korf97 -Dalgorithm="textbook"
很可能您的計算機沒有足夠的內存來使用 textbook 實現完成整個實驗。為了避免存儲交換,您應當謹慎地限制 Java 進程可用的內存量。如果您要在 Linux 上運行該實驗,可以使用像 ulimit 這樣的 shell 命令來設置活動 shell 的內存限制。
一開始沒有成功
表 1 顯示我們使用的所有技術的結果。Textbook A* 實現的結果在第一行。(在後面的章節中我們描述了 Packed states 和 HPPC 及其相關結果。)
表 1. 解決 97 個 Korf 100 15 puzzle 基准測試實例的三個 A* 變體的結果
textbook 實現無法解決所有測試實例。我們未能解決三個最難的實例,而且對於我們可以解決的實例,我們花了超過 1,800 秒的時間。這些結果不算很好,因為 C/C++ 中最好的實現可在不到 600 秒的時間內解決 100 個實例。
由於內存約束我們未能解決最難的那三個實例。在每一次搜索迭代中,從 open 列表中刪除一個節點並展開它通常會導致生成更多的節點。隨著所生成節點數量的增加,在 open 列表中存儲它們所需的內存量也在增加。但是,這一內存需求不是 Java 實現所特有的;同等的 C/C++ 實現也會失敗。
Burns 等人在其論文中表明,A* 搜索的一個高效 C/C++ 實現可以用不到 30GB 的內存解決該基准測試,因此我們還沒打算放棄 Java A* 實現。我們還可以應用後續章節中討論的其他技術,更高效地使用內存。最終得出一個能夠快速解決整個基准測試的高效的 A* Java 實現。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 下一頁 收藏本文
包裝狀態
在使用像 VisualVM 這樣的探查器檢查 A* 搜索的內存使用情況時,我們看到所有內存都被 Node 類占用,更直接地說由 TileState 類占用。為了降低內存使用量,我們需要重訪這些類的實現。
每個滑塊狀態必須存儲所有 15 個滑塊的位置。為此我們將每個滑塊的位置存儲在一個包含 15 個整數的數組中。我們可以更簡明地表示這些位置,將它們包裝成一個 64 位的整數(在 Java 中是 long)。當我們需要在 open 列表中存儲一個節點時,可以僅存儲狀態的包裝表示。這麼做會為每個節點節省 52 個字節。要解決基准測試中最難的實例,需要存儲大約 5.33 億個節點。通過包裝狀態表示,我們可以節省 25GB 的內存!
為了維護我們的實現的一般性,我們需要擴展 SearchDomain 接口,使用包裝和拆裝狀態的方法。在 open 列表上存儲一個節點之前,我們將生成狀態的一個包裝表示,並將該包裝表示存儲在 Node 類(而非狀態指針)中。當我們需要生成一個節點的後續節點時,只需拆裝狀態。清單 10 顯示了 pack() 方法的實現:
清單 10. pack() 方法的 Java 源代碼
1
2
3
4
5
6
7
public long pack(TileState s) {
long word = 0;
s.tiles[s.blank] = 0;
for (int i = 0; i < Ntiles; i++)
word = (word << 4) | s.tiles[i];
return word;
}
清單 11 顯示了 unpack() 方法的實現:
清單 11. unpack() 方法的 Java 源代碼
1
2
3
4
5
6
7
8
9
10
11
12
13
public void unpack(long packed, TileState state) {
state.h = 0;
state.blank = -1;
for (int i = numTiles - 1; i >= 0; i--) {
int t = (int) packed & 0xF;
packed >>= 4;
state.tiles[i] = t;
if (t == 0)
state.blank = i;
else
state.h += md[t][i];
}
}
由於包裝表示是狀態的一種規范形式,我們可以將包裝表示存儲在 closed 列表中。我們無法將基元存儲在 HashMap 類中。需要將它們包裝在Long 類的一個實例中。
表 1 中的第二行顯示使用包裝狀態表示運行實驗的結果。通過使用包裝狀態表示,我們將內存使用量減少了 55%,並縮短了運行時間,但我們仍然無法解決整個基准測試。
Java 集合框架的問題
如果您認為將每個包裝狀態表示包裝在一個 Long 實例中似乎需要很大開銷,那麼您說得沒錯。它浪費內存,而且可能導致過度的垃圾收集。JDK 1.5 增加了對 autoboxing 的支持,autoboxing 會自動轉換其對象表示的基元值(long 到 Long),反之亦然。對於大型集合,這些轉換可能會降低內存和 CPU 性能。
JDK 1.5 還引入了 Java 泛型:一個通常相對於 C++ 模板的特性。Burns 等人表明,C++ 模板在實施啟發式搜索時提供了巨大的性能優勢。泛型不提供這種優勢。泛型是使用 type-erasure 實現的,這會在編譯時刪除(消除)所有類型信息。因此,必須在運行時檢查類型信息,對於大型集合來說這會導致性能問題。
HashMap 類的實現揭露出一些其他內存開銷。HashMap 存儲包含內部 HashMap$Entry 類實例的一個數組。每當我們將一個元素添加到 HashMap 時,都會有一個新條目被創建並添加到數組。該條目類的實現通常包含三個對象引用和一個 32 位整數的引用,每個條目總共 32 個字節。由於 closed 列表中有 5.33 億個節點,我們將有超過 15GB 的內存開銷。
接下來,我們將介紹 HashMap 類的一個替代方法,該方法支持我們通過直接存儲基元進一步減少內存使用。
高性能的原生集合
由於我們現在僅在 closed 列表中存儲基元,我們可以利用高性能的原生集合(High Performance Primitive Collections,HPPC)。HPPC 是一個替代的集合框架,支持您直接存儲基元值,而沒有 JCF 帶來的所有那些開銷。與 Java 泛型相比,HPPC 使用了一種類似 C++ 模板的技術,在編譯時生成每個集合類和 Java 基元類型的獨立實現。這樣一來,在將基元值存儲到一個集合中時就無需使用 Long 和Integer 這樣的類包裝基元值。其另外一個作用是可以避免對於 JCF 來說必需的大量強制轉換。
另外還有用於存儲基元值的其他 JCF 替代方法。Apache Commons Primitive Collections 和 fastutils 就是兩個不錯的示例。不過,我們認為 HPPC 的設計在實現高性能算法時有一個顯著的優勢:它為每個集合類公開內部數據存儲。直接訪問這一存儲可以實現許多優化。例如,如果我們想將 open 或 closed 列表存儲在磁盤上,直接訪問底層數據數組比通過一個迭代器間接訪問數據更有效。
我們可以修改 A* 實現,對 closed 列表使用 LongOpenHashSet 類的一個實例。我們需要做的更改相當簡單。我們不再需要重寫 state class 的hashcode 和 equals 方法,因為我們僅需存儲基元值。closed 列表是一個集合(它不包含重復元素),因此我們僅需要存儲值,而無需存儲鍵/值對。
表 1 中的第三行顯示了用 HPPC 取代 JCF 後運行實驗的結果。憑借 HPPC,我們將內存使用量減少了 27%,將運行時間減少了 33%。
既然內存總共減少了 82%,我們就可以在內存約束內解決整個基准測試了。結果顯示於表 2 中的第一行:
表 2. 解決全部 100 個 Korf 100 基准測試實例的三個 A* 變體的結果
通過 HPPC,我們可以用 30GB 內存解決全部 100 個實例,但所用時間超過 1,800 秒。表 2 中的其他結果反映了我們通過改進其他重要數據結構加速實現的方式:open 列表。
PriorityQueue 的問題
每次我們將一個元素添加到 open 列表時,都需要再次排隊。PriorityQueue 有 O(log(n)) 入列和出列操作時間。涉及到排序時,PriorityQueue 是高效的,但顯然是不自由的,特別在 n 值較大時。記得對於最難的問題實例,我們添加了超過 5 億個節點到 open 列表。此外,由於我們的基准測試問題中的所有操作都具有相同的成本,可能的 f 值的范圍較小。因此使用 PriorityQueue 的優勢與開銷相比可能得不償失。
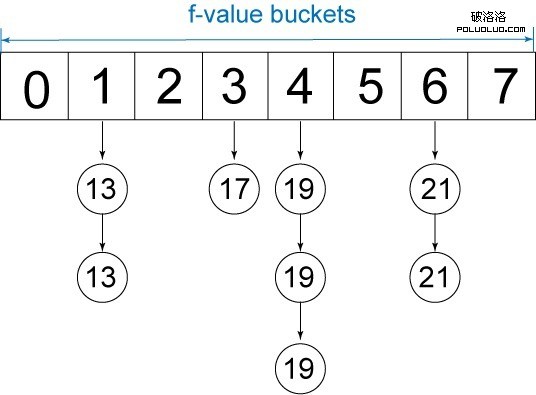
另一個替代方法是使用基於桶的優先級隊列。假設我們域中的操作成本在一個狹窄的值域內,我們可以定義一個固定的存儲桶范圍:每個 f 值一個存儲桶。當我們生成一個節點時,只需將它放在與 f 值對應的存儲桶中。當我們需要訪問隊列頭時,可以首先從 f 值最小的存儲桶看起,直至我們找到一個節點。這種數據結構叫作 1 級桶優先級隊列,它支持恆定入列和出列操作。
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 下一頁 收藏本文
圖 7 展示了這一數據結構:
圖 7. 1 級桶優先級隊列
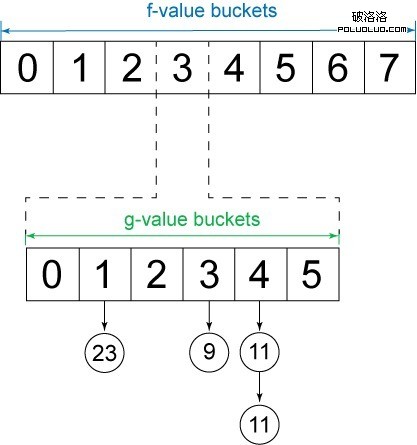
精明的讀者會注意到,如果我們實現這裡描述的 1 級桶優先級隊列,就失去了使用 g 值打破節點間關系的能力。您之前應當已經意識到,以這種方式打破關系是一種值得的優化。為了維持這一優化,我們可以實現一個嵌套 桶優先級隊列。1 級存儲桶用於表示 f 值的范圍,嵌套級別用於表示 g 值的范圍。圖 8 展示了這一數據結構:
圖 8. 嵌套桶優先級隊列
現在我們可以更新我們的 A* 實現,為 open 列表使用一個嵌套桶優先級隊列。嵌套桶優先級隊列的完整實現可在本文源代碼中包含的 BucketHeap.java 文件中找到(參見 下載 部分)。
表 2 的第二行顯示使用嵌套桶優先級隊列運行實驗的結果。通過使用一個嵌套桶優先級隊列,而非 PriorityQueue,我們將運行時間縮短了將近 58%,所用時間是 1,000 多秒。我們可以再做一件事來縮短運行時間。
避免垃圾收集
垃圾收集常被視為 Java 中的一個瓶頸。有許多關於 JVM 中垃圾收集調優的優秀文章可應用於這裡,因此我們不會詳細討論該主題。
A* 通常生成許多短暫的狀態和邊緣對象並招致大量昂貴的垃圾收集。通過重用對象,我們可以減少所需的垃圾收集量。為此我們可以做一些簡單的更改。在 A* 搜索循環的每一次迭代中,我們分配一個新邊緣和一個新狀態(對於最難的問題是 5.33 億個節點)。與其每次分配新對象,我們可以在所有循環迭代中重用相同的狀態和邊緣對象。
為了擁有可重用的邊緣和狀態對象,我們需要修改 Domain 接口。 與其讓 apply() 方法返回 Edge 的一個實例,我們需要提供自己的實例,該實例通過調用 apply() 加以修改。對 edge 的更改不是遞增的,因此在將其傳遞給 apply() 之前,我們無需擔心哪些值存儲在 edge 中。不過,apply() 對 state 對象所做的更改是 遞增的。為了合理生成所有可能的後繼狀態,而無需復制狀態,我們需要一種撤銷所做更改的方式。為此,我們必須擴展 Domain 接口,得到一個 undo() 方法。清單 12 顯示 Domain 接口更改:
清單 12. 更新的 Domain 接口
1
2
3
4
5
6
public interface Domain {
...
public void apply(T state, Edge edge, int op);
public void undo(T state, Edge edge);
...
}
表 2 中的第三行顯示最終實驗的結果。通過循環利用我們的狀態和邊緣對象,我們可以避免昂貴的垃圾收集,並將運行時間縮短超過 15%。利用我們高效的 A* Java 實現,我們現在可以僅用 30GB 的內存在 925 秒內解決整個基准測試。鑒於最好的 C/C++ 實現需要 27GB 內存且花費 540 秒,這個結果已經很好了。我們的 Java 實現僅比 C/C++ 實現慢 1.7 倍,且需要大約同樣的內存量。
結束語
在本文中,我們向您介紹了啟發式搜索。我們提出了 A* 算法,並闡述了 Java textbook 實現。我們指出該實現存在性能問題,無法在合理的時間或內存約束內解決一個標准的基准測試問題。我們利用 HPPC 和一些可降低內存使用和避免昂貴的垃圾收集的技術解決了這些問題。我們改進的實現能夠在適當的時間和內存約束內解決基准測試,這證明了 Java 是實現啟發式搜索算法的一個不錯選擇。此外,我們在本文提供的技術也可應用於許多實際 Java 應用程序。例如,在某些情況下,使用 HPPC 可以立即提高存儲大量基元值的任何 Java 應用程序的性能。
下載
注:相關網站建設技巧閱讀請移步到建站教程頻道。
上一頁 1 2 3 4 5 6 7 收藏本文