作為SEOer,我們使用的各種各樣的工具,以收集各式各樣的技術問題,網站分析,抓取診斷,百度站長工具等。所有這些工具是有用的,但都無法比擬在網站日志數據分析搜索引擎蜘蛛抓取,就像Googlebot到爬取您的網站並您的網站上留下了一個真實的記錄。這是網絡服務器日志。日志是一個強大的源數據經常沒有得到充分利用,但有助於保持您的網站的搜索引擎抓取檢查的完整性。
服務器日志是由一個特定的服務器進行詳細記錄了每一個動作。在一個Web服務器的情況下,你可以得到很多有用的信息。如何檢索和分析日志文件,並根據您的服務器的響應代碼(404,302,500等)的識別問題。我將它分解成2個部分,每個部分突出不同的問題,可以發現在您的Web服務器日志
一、獲取日志文件
搜索引擎抓取網站信息必會在服務器上留下信息,這個信息就在網站日志文件裡。我們通過日志可以了解搜索引擎的訪問情況,一般通過主機服務商開通日志功能,再通過FTP訪問網站的根目錄,在根目錄下可以看到一個log或者weblog文件夾,這裡面就是日志文件,我們把這個日志文件下載下來,用記事本(或浏覽器)打開就可以看到網站日志的內容。那麼到底這個日志裡面隱藏了什麼玄機呢?其實日志文件就像飛機上的黑匣子。我們可以通過這個日志了解很多信息,那麼到底這個日志給我們傳遞了什麼內容呢?下面先做一個簡單的說明。
日期:這將讓你一天搜索引擎抓取速度的發展趨勢進行分析。
被爬取文件:這將告訴你哪些被抓取的目錄和文件,並在某些路段或類型的內容可以幫助查明問題。
狀態碼:(只列出常見到並能直接反正網站問題的狀態碼)
200狀態碼:請求已成功,請求所希望的響應頭或數據體將隨此響應返回。
302狀態碼:請求的資源現在臨時從不同的URI響應請求。
404狀態碼:請求失敗,請求所希望得到的資源未被在服務器上發現。
500狀態碼:服務器遇到了一個未曾預料的狀況,導致了它無法完成對請求的處理。
- - 提供了哪些網頁被爬蟲運行到並反應出什麼樣的問題。
從哪裡來:雖然這不一定是有用的分析搜索機器人,它是非常有價值的,其他的流量分析。
哪種爬蟲:這個會告訴你哪個搜索引擎爬蟲在你的網頁上運行的。
二、解析網站日志文件
現在你需要一個日志分析工具,因為如果你的網站有幾M或幾十M甚至百M以上的日志數據時,你不可能一條條去看。再說,就算日志數據不多,一條條看也是不科學的。這裡用光年seo日志分析工具為大家做個例子。
1.導入文件到您解析軟件。
2.分析網站日志及時發現出現的問題
搜索引擎抓取您的網站有最快的方式是看在正在服務的服務器響應代碼。404(找不到頁面)可能意味著抓取那珍貴的資源被浪費了;302重定向請求的資源現在臨時從不同的URI響應請求;500是服務器遇到了一個未曾預料的狀況,導致了它無法完成對請求的處理,可以分析出服務器出現的問題。雖然網站管理工具提供了一些信息,這樣的錯誤,會給你的網站造成一個非常大的影響。
分析的第一步是從您的日志數據,通過光年seo日志分析工具以產生一個數據表。在最基本的層面上,讓我們看看哪些搜索引擎的爬蟲在爬行這個網站:
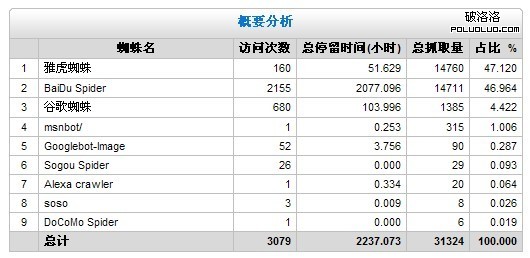
通過報表我們想幾個問題:
a.雅虎蜘蛛總抓取量占了全部的47.12%;那麼我從流量統計器看到。沒有一個流量是從雅虎搜索引擎過來的。那麼這個蜘蛛可不可以禁止他再來訪問呢?
b.百度蜘蛛(BaiDu Spider )的訪問次數、停留的時間、總抓取量反應了什麼呢?
c.其它搜索引擎的蜘蛛的訪問次數、停留的時間、總抓取量那麼少的原因是什麼呢?有沒有改善的方法呢?
接下來,讓我們來看看在蜘蛛狀態碼分析,我們最關心的問題。
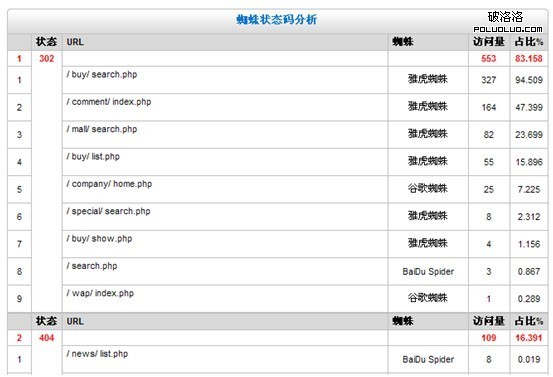
這是只顯示這個日志有問題的蜘蛛狀態碼,而已正常200將不被分析。我們將要細看這個表格。總體而言,好到壞的比例看起來很健康,但有一些個別的問題讓我們嘗試弄清楚這是怎麼回事。
302出現的問題數量是可以接受的,但是不代表可以放著不去處理,我們應該有更好的方法來處理這些問題,也許用一個robots.txt指令應排除這些頁面被抓取。
404的出現達到109個。在幾萬的抓取量來說。網站的這個數據也算是可以的。但是也需要解決,找出潛在的問題是隔離404目錄或者使用rel =”nofollow”注釋這些404鏈接。當然404的頁面也必須要有。
結語
百度網站管理為您提供抓取錯誤的信息,但在許多情況下,它們限制了數據。作為SEO的,我們應該利用一切可用的數據,畢竟只有一個數據源,你可以真正依靠自己的源。日志不撒謊!