搜索引擎是指根據一定的策略、運用特定的計算機程序從互聯網上搜集信息,在對信息進行組織和處理後,為用戶提供檢索服務,將用戶檢索相關的信息展示給用戶的系統。當用戶在搜索框輸入一個關鍵字後,我們應該給用戶返回什麼內容呢?
一、搜索引擎原理和用戶使用習慣
1.1 搜索引擎是一個可供所有人檢索的數據庫
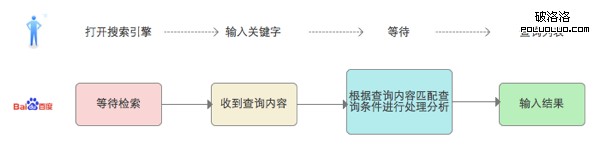
圖1:搜索引擎簡單的人機交互過程
其中:
1)被檢索的數據庫即搜索引擎所抓取的網頁數據。
通過蜘蛛爬取到原始數據後,搜索引擎會對其進行處理後才入庫。即搜索引擎的搜索算法,比如大家熟知名字( 當然是名字啦,內容原理是最高機密) 的Google的PageRank。
2)搜索引擎是高度簡化後的產品。
用戶需要做的即是輸入想要檢索的關鍵詞,確定,查看結果。這裡有個需要說明的是,用戶連搜索條件都不需要輸入。而對搜索引擎來講,不僅要在海量數據中快速找到相關結果,還要揣測用戶的期望並提取正確的內容給用戶,內部的機制已經不能用繁瑣來形容了。
這個難度就好比在大量圖書中快速准確找出某一個未知問題的答案一樣。

圖2:剛拍攝的國家圖書館,使用了濾鏡。
1.2 搜索引擎數據處理過程
搜索引擎是一個超級復雜的系統,內部具體的處理規則和技術原理不可能是簡單的闡述清楚。我們通過產品的思維來理解一下這個過程即可。拿寫論文的例子分析即可,論文在成文之前材料的整理過程大致如下:
1)從網絡、圖書館、書籍雜志、講座等等收集大量原始資料
2)排除相關重復內容
3)排除跟主題關聯性不大的內容
4)根據主題、邏輯順序、優先級等進行人為的計算、分析、排版、處理等。這個過程是最為繁瑣和耗時的,使用的武器便是史上最牛逼的工具:人腦!!!
5)成文輸入結果
忍不住再重申一下:所有的產品其實都是在模仿人類的實際社會活動。。。明白這個對於產品經理很重要哦。
搜索引擎數據處理流程基本類似(想要了解的可以自行搜索相關資料),唯一的也是搜索引擎想消除的區別 :
一個是有感情有邏輯的人腦在分析,一個是機器按照一定規則來分析。
所以,想要搜索結果更精准,那就讓它像人腦一樣分析輸入數據並輸入結果。
恩,我也覺得不怎麼現實,但是可以想辦法讓他比較精准。
二、獲取信息的方式
我們還是先從日常行為的來入手然後再推導產品的操作方式。
2.1 通常,我們從周圍環境如下獲取信息:
1、 已知獲取途徑和方法
如想獲知今天美元對人民幣的匯率抑或北京飛青島的機票價格和時刻表,因為途徑已知,此類信息只要按圖索骥即可。差別在於不同途徑的成本。匯率可通過網絡查詢、電話咨詢、銀行網點詢問等,顯然第一種方法更便捷。(的確是廢話)。
這些信息都是規則化,概念明確的。
2、了解核心關鍵需要整理的
如剛才提到的論文寫作,假設題目為弱關系社區設計,我們就需要去詢問什麼弱關系,和強關系有什麼區別,已有的設計案例是什麼。
這些信息的獲取建立在人為分析的前提下。
2.2 提問方式
還是舉兩個例子。
1、 在形成完整的序言邏輯前,小孩子提問的方式是最簡單的關鍵詞,大人們要做的便是通過他的咿呀來理解孩子的需求。一般大人都能准確預測,原因在於其非常了解孩子的習慣、行為、方式、特征 等。
2、有了完整的語言邏輯後,我們一般選擇直接提問:今天的匯率是什麼?北京飛青島的票價多少,都是幾點的?人腦也完全可以處理這些問題。當然,人是復雜的感情動物,好多東西還不能完全通過字面意思去理解。說一個不是很恰當的例子:約會中,女孩提問你覺得現在的房價如何。字面意思是房價,潛在意思是你的購房能力如何。
2.3 搜索引擎該這麼處理
假設搜索引擎具有跟我們一樣的大腦的話,那他處理問題的方式應該是這樣的:
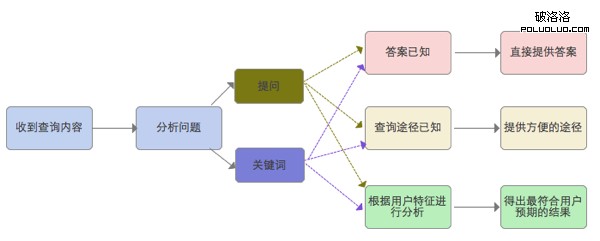
1、分析所查詢的問題是檢索關鍵詞還是提問
2、結果分為三種,
答案已知直接輸出