搜索引擎看似簡單的抓取-入庫-查詢工作,但其中各個環節暗含的算法卻十分復雜。
搜索引擎抓取頁面工作靠蜘蛛(Spider)來完成,抓取動作很容易實現,但是抓取哪些頁面,優先抓取哪些頁面卻需要算法來決定,下面介紹幾個抓取算法:
1、寬度優先抓取策略:
我們都知道,大部分網站都是按照樹狀圖來完成頁面分布的,那麼在一個樹狀圖的鏈接結構中,哪些頁面會被優先抓取呢?為什麼要優先抓取這些頁面呢?寬度優先抓取策略就是按照樹狀圖結構,優先抓取同級鏈接,待同級鏈接抓取完成後,再抓取下一級鏈接。如下圖:
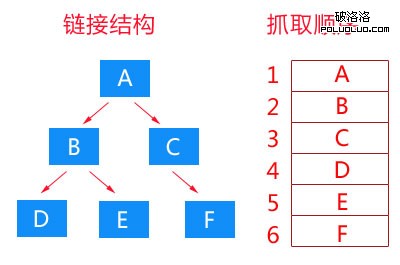
大家可以發現,我在表述的時候,使用的是鏈接結構而不是網站結構。這裡的鏈接結構可以由任何頁面的鏈接構成,並不一定是網站內部鏈接。這是一種理想化的寬度優先抓取策略,在實際的抓取過程中,不可能想這樣完全寬度優先,而是有限寬度優先,如下圖:
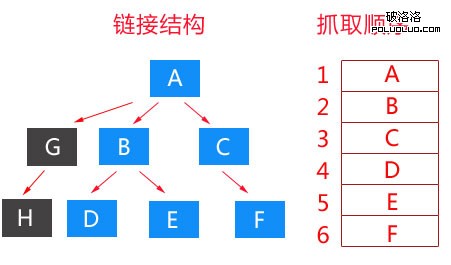
上圖中,我們的Spider在取回G鏈接時,通過算法發現,G頁面沒有任何價值,所以悲劇的G鏈接以及下級H鏈接被Spider給和諧了。至於G鏈接為什麼會被和諧掉?好吧,我們來分析一下。
2、非完全遍歷鏈接權重計算:
每個搜索引擎都有一套pagerank(指頁面權重,非google PR)計算方法,並且經常會更新。互聯網近乎無窮大,每天都會產生海量的新鏈接。搜索引擎對於鏈接權重的計算只能是非完全遍歷。為什麼Google PR要三個月左右才更新一次?為什麼百度大更新一個月1-2兩次?這就是因為搜索引擎采用了非完全遍歷鏈接權重算法來計算鏈接權重。其實按照目前的技術,實現更快頻率的權重更新並不難,計算速度以及存儲速度完全跟得上,但為什麼不去做?因為沒那麼必要,或者已經實現了,但不想公布出來。那,什麼是非完全遍歷鏈接權重計算?
我們將K數量的鏈接形成一個集合,R代表鏈接所獲得的pagerank,S代表鏈接所包含的鏈接數量,Q代表是否參與傳遞,β代表阻尼因數,那麼鏈接所獲得的權重計算公式為:
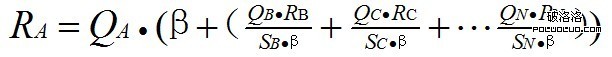
從公式 裡可以發現,決定鏈接權重的是Q,如果鏈接被發現作弊,或者搜索引擎人工清除,或者其他原因,Q被設為0,那麼再多的外鏈都沒用。β是阻尼因數,主要作用是防止權重0的出現,導致鏈接無法參與權重傳遞,以及防止作弊的出現。阻尼因數β一般為0.85。為什麼會在網站數量上乘以阻尼因數?因為一個頁面內並非所有的頁面都參與權重傳遞,搜索引擎會將已經過濾過的鏈接再度剔除15%。
但這種非完全遍歷權重計算需要積累到一定數量的鏈接後才能再次開始計算,所以一般更新周期比較慢,無法滿足用戶對即時信息的需求。所以在此基礎上,出現了實時權重分配抓取策略。即當蜘蛛完成抓取頁面並入口後,馬上進行權重分配,將權重重新分配待抓取鏈接庫,然後蜘蛛根據權重高低來進行抓取。
3、社會工程學抓取策略
社會工程學策略,就是在蜘蛛抓取的過程中,加入人工智能,或者通過人工智能培訓出來的機器智能,來確定抓取的優先度。目前我已知的抓取策略有:
a、熱點優先策略:對於爆發式的熱點關鍵詞進行優先抓取,而且不需要經過嚴格的去重和過濾,因為會有新的鏈接來覆蓋以及用戶的主動選擇。
b、權威優先策略:搜索引擎會給每個網站分配一個權威度,通過網站歷史、網站更新等來確定網站的權威度,優先抓取權威度高的網站鏈接。
c、用戶點擊策略:當大部分搜索一個行業詞庫內的關鍵詞時,頻繁的點擊同一個網站的搜索結果,那麼搜索引擎會更頻繁的抓取這個網站。
d、歷史參考策略:對於保持頻繁更新的網站,搜索引擎會對網站建立更新歷史,根據更新歷史來預估未來的更新量以及確定抓取頻率。
對SEO工作的指導:
搜索引擎的抓取原理已經深入的講解了,那麼現在要淺出這些原理對SEO工作的指導作用:
A、定時、定量的更新會讓蜘蛛准時爬行抓取網站頁面;
B、公司運作網站比個人網站的權威度更高;
C、建站時間長的網站更容易被抓取;
D、頁面內應適當的分布鏈接,太多、太少都不好;
E、受用戶歡迎的網站同樣受搜索引擎歡迎;
F、重要頁面應該放置在更淺的網站結構中;
G、網站內的行業權威信息會提高網站的權威度。
這次教程就到這裡了,下次教程的主題是:頁面價值以及網站權重的計算。