最近分析網站日志,發現一個奇怪的現象,百度蜘蛛開始爬行網站裡的js文件了,而且幾乎每天都來爬行,這個現象也得到很多站長朋友的證實。就百度蜘蛛爬行js文件到底能不能完全識別js代碼裡的鏈接以及文字特作了以下分析:
1、大批量利用js作弊的網站被降權甚至被k
大家都知道,百度對淘寶的東西是相當敏感的,因此淘寶客的網站是一類利用js隱瞞蜘蛛爬行的典型網站,然而自從百度6-28(6月28日大批量網站被k)事件開始,淘寶客類型的網站當然是受到了重創,不少以返利為盈利的淘寶客站長收入一度下降,就這一類型的網站底是不是因為百度技術升級而識別了js裡面的淘寶鏈接呢?
2、新站設計js作弊的網站一律不收錄
本人新做一個淘寶客的網站還是繼承以前的模式,淘寶鏈接用js代碼隱藏起來,但是過了十天、半個月,到現在已經一個月過去了百度就是不收錄,蜘蛛天天都會來爬,就是不給收錄,而且還會爬行js。當然這也正常,但是當了解到很多想再以這種模式爬起來的淘寶客站長也是跟這種情況,不得不讓人開始懷疑百度蜘蛛已經開始讀懂js代碼了。


3、利用百度統計分析網站時可以分析出js代碼裡的鏈接
相信很多站長如果網站收錄不正常或者是長時間沒有被百度收錄的話都用試用各種工具去分析網站,本人新站不收錄,便利用站長統計工具分析網站的seo情況,不分析不知道,一分析嚇一跳,百度站長統計裡面的網站診斷既然能分析出js裡面的鏈接,既然這裡能識別出js代碼裡面的鏈接,相信蜘蛛也能識別js代碼的鏈接。
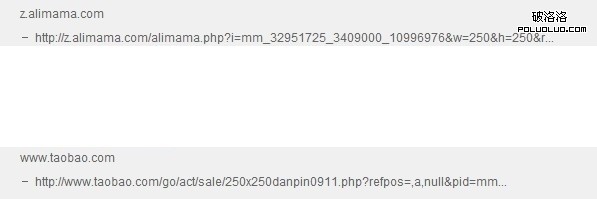
(這些鏈接都是用調用js代碼的在百度統計裡面完全能分析出來)
綜上所述,即便是知名國外GOOGLE也未能完全識別JS代碼,但是相關的例子以及事實證明百度對JS至少有了初步的識別功能,至於能識別到什麼程度,希望閱讀本文的志同道合人士進一步詳細分析給出更有說服力的例子。