這篇文章主要講解搜索引擎的蜘蛛爬蟲的工作原理,包括它的四種抓取策略。
首先呢,搜索引擎的蜘蛛抓取網頁是有著一定的規律,不會去隨便抓取網頁,並且呢,蜘蛛是通過超連接來抓取網頁的,我們剛剛說了,搜索引擎有四種抓取網頁的策略,下邊我們一一講解。
深度優先
所謂深度優先,就是蜘蛛在一個頁面中發現第一個超鏈接,然後爬取這個頁面,當爬到第二個頁面後,在第二個頁面發現的第一個超鏈接,然後再順著往下爬,如下圖:
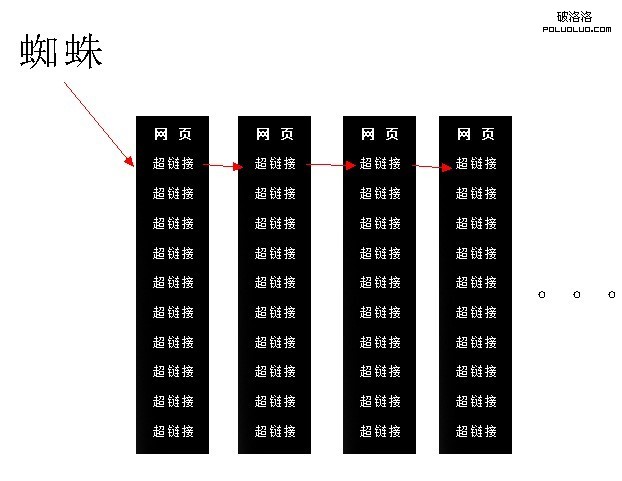
深度優先,導致蜘蛛抓取的網頁的質量,越來越低,並且在傳遞網站權重上,也有著根本的問題。
寬度優先
在深度優先上,搜索引擎有著根本的問題,那麼在之後,搜索引擎又推出了蜘蛛抓取的第二個策略,也就是寬度優先,寬度優先指的是,蜘蛛會先把這個頁面所有的鏈接都爬一次,然後在順著這些鏈接往下爬,如下圖:
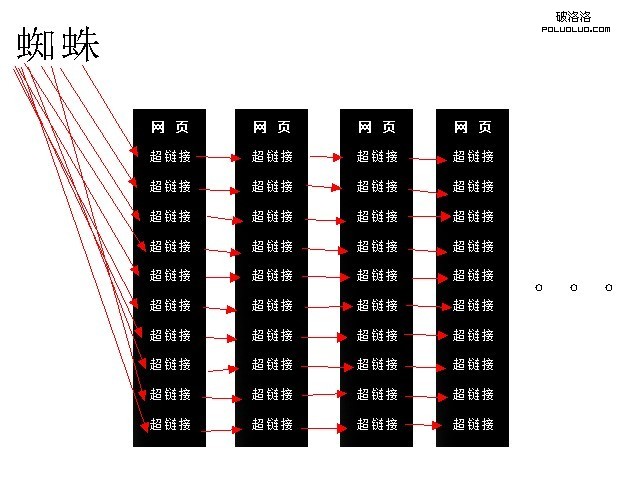
但是寬度優先也存在著問題,那就是蜘蛛抓取的效率和質量問題。
先寬後深 – 權重優先
現在搜索引擎是寬度和深度優先的結合,蜘蛛在抓取一個網頁的時候,會先把這個頁面所有的鏈接都抓取一次,然後再根據這些ULR的權重來判定,那個URL的權重高,那麼就采用深度優先,那個URL權重低,就采用寬度優先或者不抓取。
重訪抓取策略
重訪抓取策略,是最後的一個,搜索引擎蜘蛛在抓取完這個網頁之後,然後根據這個頁面的權重、包括它的更新頻率、更新質量、外鏈的數量等等來判定,那麼對於權重高的頁面,蜘蛛會在相隔較短的時間段在回來重新抓取,比如新浪網,權重很高,搜索引擎蜘蛛都是按照秒來重新抓取的。而對於一些權重較低的頁面,比如長期不更新的頁面,那麼蜘蛛會隔好長時間在來抓取一次,比如我們常常搜索的百度大更新,蜘蛛就是對於一些網頁權重較低的頁面進行一次全部的抓取,一般情況,百度大更新,一個月一次。
本文來源 http://www.shizhanqiang.com/ 轉載留下版權
感謝 史占強 的投稿
- 上一頁:2012年6月百度更新了什麼?
- 下一頁:分享導致百度收錄不穩定的5個因素