今天我和大家講講有關於百度相關關鍵字的個人猜想,也許大家從網上的百度宣傳廣告與競爭視頻上都可以看出,百度對自己的漢字理解能力非常自負,在同樣的條件下,百度的漢字理解能力比某國外搜索引擎要好,那麼這是不是真的呢?我認為對漢語的認識方面,百度對谷歌高一點,但不是很顯明的優勢,而在對網站變化的反應速度上,谷歌遠比百度要牛的多,這一點,相信不光是站長,其它的網民也都有感覺。
為什麼要了解百度相關關鍵字匹配知識
作為一個SEO,要了解對自己工作有作用的知識,本文中我會講到百度相關關鍵字匹配知識,學習這一知識點的話,你就可以在以後的選詞,分詞,頁面關鍵詞密度及優化長尾關鍵詞這些方面有更好的更多的選擇了。這就是學習本文知識點的直接作用。下面開始講正文了。
百度相關關鍵字匹配能力的體現
上面我說到對漢語的認識方面,百度對谷歌高一點,那麼百度相關關鍵字匹配能力是怎樣看出來的呢,或者說,它在我們日常使用百度時會以哪些方式展現出來呢?我列出幾種大家可以看看。
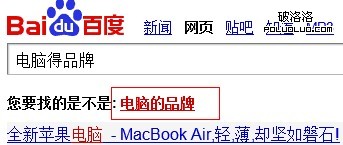
1、錯別字更正:比如搜索“電腦得品牌”時,百度會識別當時的錯別字,進而在第一條時就會提示你:
2、漢語拼音理解能力:當你輸入拼音時,百度會自動理解成與當前拼音最接近的漢字,比如搜索“shanghaidieyou”,會出現:

3、近義(字)詞匹配:當你輸入一個詞進行搜索,但你所搜索的詞結果太少,這時百度就會匹配它認為意思相近,但搜索結果很多的關鍵詞,比如搜索“蝶友財務服務咋樣”,百度會將“咋樣”自動匹配為“怎麼樣”。

4、更正詞序:有時我們搜索關鍵詞時,不一定按公允的語言進行搜索,當關鍵詞當中的小詞組順序混亂時,百度會自動更正詞序,從而列出更好更准確的搜索結果,比如搜索“會計服務 上海”這個詞時,百度會自動更正為“上海會計服務”。

5、敏感詞規避:有時詞是不適合公開或不適合完全公開搜索結果的,這時,百度會將這些詞的搜索結果進行規避,比如說搜索“三唑侖”(也就是安眠藥)時,會提示

以上五條是我總結了百度相關關鍵字匹配能力的體現方式,了解了這些後,下面我來講講我對百度漢字認知能力的猜想。
百度漢字智能識別能力大猜想
百度有這樣的智能,自然是因為它們強大後台程序在起作用,根據上面說到的五點體現方式,我猜想百度後台至少有四個功能性模塊在起作用,它們各有各的功能,從而使百度的使用者有了很好的用戶體驗。下面一一來談談我的猜想。
一 近義(同義)詞庫:必須要有一個獨立的近義(同義)詞庫才能實現近義(字)詞匹配和錯別字更正這兩個功能,道理很好理解,而對於這一模塊的內部結構,我的猜想是這樣的:就像我們擺放廚房用品一樣,盤子是盤子,碗是碗,無論大碗小碗,青花碗,流金碗,而對於某些有三重近義關系的詞,可將其另放一處,就像某個大湯碗一樣,你即可以當碗用,也可以當湯盤來用,這種用品可以另放一處,當盤子在使用時處於缺省時,就拿這個大湯碗來匹配(這個比喻還可以吧)。
二 熱點詞庫:我們知道,互聯網有二個特點:1更新快,2數據海量。這個世界每天都有熱點事件,比如近期出現的“抗強拆被攔腰砸死”事件,而過段時間後,這個詞的熱度就會被新的熱點事件關鍵詞所取代,所以百度要迎合關注熱點事件的龐大網民群體,它就必須要有一個獨立的熱點詞庫,它可以通過監控每天百度關鍵詞搜索量和關鍵詞媒體關注度來添加新的熱點事件關鍵詞,形象點來說就像是我們去理發店,你無須親自體驗每一家理發服務技術,只要在某個時段裡監控這些理發店的來往人群,就可以知道“哪家店是本區域最熱門的理發店”,得到數據後,就把它收錄在你的生活日記備忘錄中。以上就是百度熱點詞庫增加內容的方式,至於刪除關鍵詞是這樣的:一段時間後,再次監控這個詞的搜索量,同比上期大幅度下降後,則自動刪除這個熱點關鍵詞。
三 穩定詞詞庫:有時關鍵詞一年到頭的搜索量與搜索方式都很穩定,我猜想百度會為它們單獨設立一個模塊,比如電腦品牌、上海財務公司、上海人才招聘等等,這樣做的好處在於:當小部分網民搜索這類詞時出現錯誤,比如把詞的順序搞顛倒了(人才招聘上海),百度就可以通過穩定詞的詞庫自動的把這一錯誤更正過來。
四 敏感詞詞庫:敏感詞詞庫數量不如以上三個詞庫,但它對於一個搜索引擎的社會責任度、用戶體驗度、使用安全性、公正性