對於robots.txt文件對於網站的作用大家都知道,但是通過觀察發現,有些朋友對於robots.txt文件的規則還是有一定的誤區。
比如有很多人這樣寫:
User-agent: *
Allow: /
Disallow: /mulu/
不知道大家有沒有看出來,這個規則其實是不起作用的,第一句Allow: / 指的是允許蜘蛛爬行所有內容,第二句Disallow: /mulu/指的是禁止/mulu/下面的所有內容。
表面上看這個規則想達到的目的是:允許蜘蛛爬行除了/mulu/之外的網站所有頁面。
但是搜索引擎蜘蛛執行的規則是從上到下,這樣會造成第二句命令失效。
正確的規則應該是:
User-agent: *
Disallow: /mulu/
Allow: /
也就是先執行禁止命令,再執行允許命令,這樣就不會失效了。
另外對於百度蜘蛛來說,還有一個容易犯的錯誤,那就是Disallow命令和Allow命令之後要以斜槓/開頭,所以有些人這樣寫:Disallow: *.html 這樣對百度蜘蛛來說是錯誤的,應該寫成:Disallow: /*.html 。
有時候我們寫這些規則可能會有一些沒有注意到的問題,現在可以通過百度站長工具(zhanzhang.baidu.com)和Google站長工具來測試。
相對來說百度站長工具robots工具相對簡陋一些:
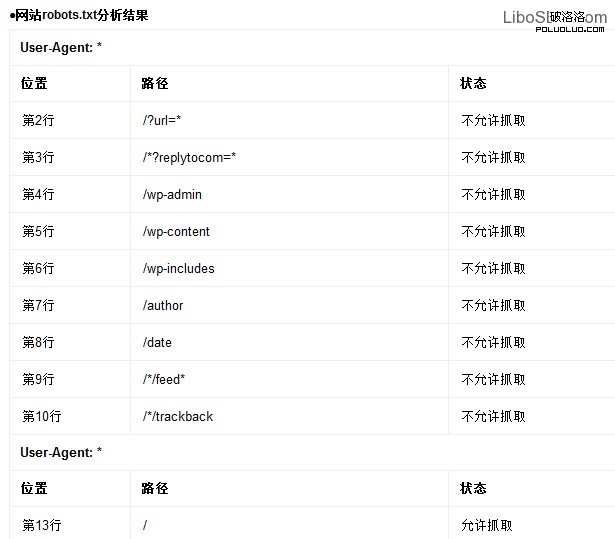
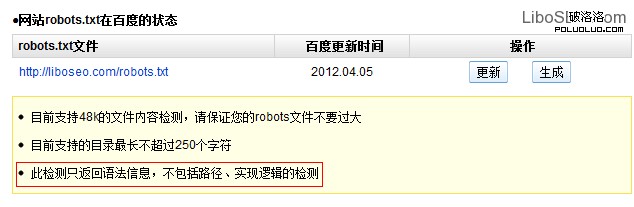
百度Robots工具只能檢測每一行命令是否符合語法規則,但是不檢測實際效果和抓取邏輯規則。
相對來說Google的Robots工具好用很多,如圖:
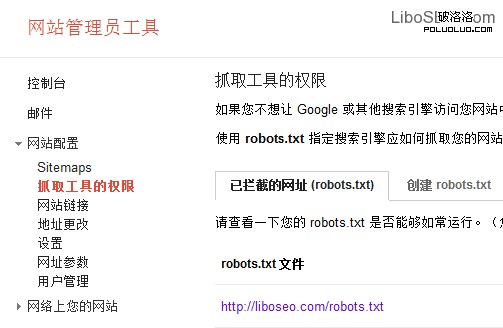
在谷歌站長工具裡的名稱是抓取工具的權限,並報告Google抓取網站頁面的時候被攔截了多少個網址。

還可以在線測試Robots修改後的效果,當然這裡的修改只是測試用,如果沒有問題了,可以生成robots.txt文件,或者把命令代碼復制到robots.txt文本文檔中,上傳到網站根目錄。
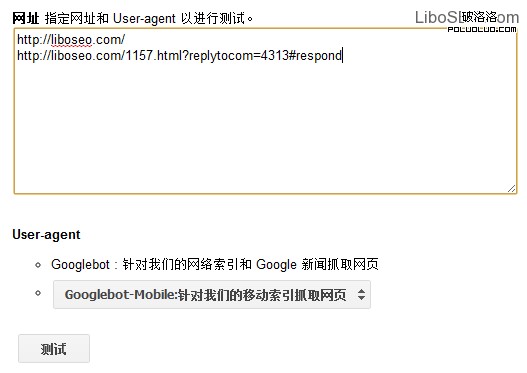
Google的測試跟百度有很大的區別,它可以讓你輸入某一個或者某些網址,測試Google蜘蛛是否抓取這些網址。
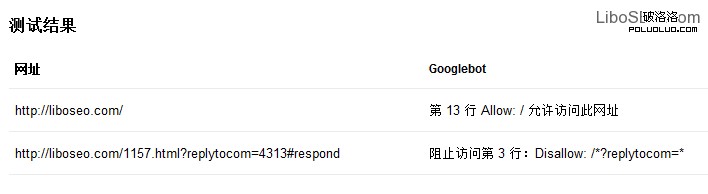
測試結果是這些網址被Google蜘蛛抓取的情況,這個測試對於Robots文件對某些特定url的規則是否有效。
而兩個工具結合起來當然更好了,這下應該徹底明白robots應該怎麼寫了吧。
轉載請注明來自逍遙博客,本文地址:http://liboseo.com/1170.html,轉載請注明出處和鏈接!
(責任編輯:sunsun)
相關文章列表:
- 百度站長平台旗下站點抓取異常工具全新上線
- 重要seo細節之robots.txt那點事
- 優化robots.txt文件:提高AdSense廣告相關匹配度
- 谷歌:網站站長工具引入“網站健康”理念
- 上一頁:淺談站長軟文思路來源(連載二)
- 下一頁:SEO 學會如何在彎道超車