在該系列文章的第一篇中,提到SEO應該是以數據為基礎的,並略為展開寫了一些數據方面的准備工作。數據雖然是非常重要的,但它扮演的角色只能是輔助:發現問題、總結改進、作為決策的參考因素等,但都無法脫離既有的SEO方法而獨立存在。
而SEO的方法,應該分為兩種或四種:使網站對搜索引擎友好、使網站對搜索引擎的用戶友好。如果再考慮黑帽SEO手段的話,可以額外加上兩項:使搜索引擎誤以為網站對搜索引擎友好、使搜索引擎誤以為網站對搜索引擎的用戶友好。稍有經驗的SEO,都可以總結下,看是否有任何SEO方法可以脫離這四點的范疇之外。至少我從沒看到。
當然黑帽不在這系列文章的討論范疇之內,所以就以兩篇文章來分別簡述如何對搜索引擎及其用戶友好。
本文的主題是如何讓網站對搜索引擎友好,這是一個非常大的話題,文章經過幾次刪改,最終還是決定只舉一例。畢竟搜索引擎的技術涉及面實在太廣,相應需要的網站技術也很多,一篇文章無論如何也最多提及冰山一角,那不如只找個比較有代表性的例子,剩下的大家自行擴展。
如何使搜索引擎能夠更准確的理解網頁?
搜索引擎無論如何只是程序,不可能非常完美判斷互聯網上那麼多不同網頁的不同情況。
搜索引擎對網頁分析中的主要過程之一,是將網頁分成一個個明確的功能區塊。如正文區塊、相關鏈接區塊、聯系電話區塊、無關廣告區塊等等。而它判斷的方式諸如:看字數多少、看HTML代碼的形式、將文字內容以自然語言處理來理解等等。
分塊化
一般在HTML代碼裡,最好以<div>標簽來標明網頁上的每一個重要區塊,且每個重要的<div>裡面又有一個<h2>或<h3>標簽明確指明該區塊的主題。這樣的做法可以讓頁面上每一塊內容所表達的更清晰。尤其對於搜索引擎而言,它可以通過這樣的<div>來明確它如何去給網頁分塊,並通過小標題去了解這分塊屬於什麼樣的性質,從而判斷應該如何計算處理。
一個最典型的實例是Amazon的產品信息頁面:
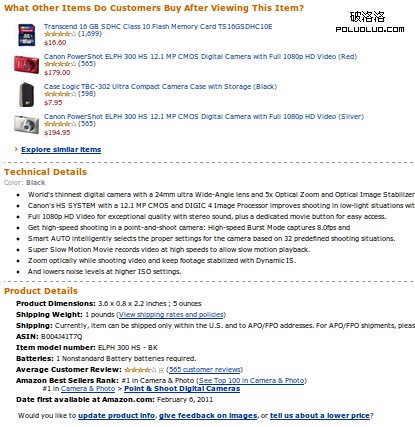
可以看到上圖中被明確歸為了三塊,且清晰指出了它們分別是關聯購買、技術細節與商品細節。相比之下,不少電商網站最上方是產品圖片與價格,然後第二塊區塊開始,就把產品參數、產品描述及大量未必有用的產品圖片依次堆在一起,無疑就差得多了。(上圖中Product Details一塊多數內容都是自動生成,而同時對用戶和SEO有價值的內容,這塊是被多數電商網站所忽略的。)
Amazon產品頁的SEO,在電商領域是最頂尖的,遠遠強出eBay等網站。分塊化便是其中主要原因之一。
語義化
這裡語義化指的是用戶所不可見的HTML代碼也要具有含義,盡管這對於用戶沒有意義,但能讓搜索引擎等程序更容易理解。(當然也方便代碼維護,這是技術層面的事情了)
微數據、微格式等是已經日漸被重視起來的概念,它無疑可以很明確的標識網頁上面元素的含義。這裡不詳細展開,可見:http://support.google.com/webmasters/bin/answer.py?hl=zh-Hans&answer=99170(微數據更重要的意義可能在於提升網頁在SERP裡面的點擊率。對於電商網站,僅以此提升幾倍SEO流量完全不是不可能的)。但微數據等方式總有一定的局限性,例如它不能指定大區塊的含義,比如告訴搜索引擎,網頁上哪裡是頭部、哪裡是底部等。HTML5規范很好的解決了這個問題,它推薦使用的<header><footer>等標簽可以非常好的展示網頁區塊。
不過很多網站目前基於很多原因還不會選用HTML5(但站在SEO的角度,應該盡力去推動下),所以不可以用<header>等標簽,還是需要用<div>。在這樣的情況下,需要注意<div>的ID命名。例如對於搜索引擎而言,<div id="header">要比<div id="toubu">容易理解得多。而且,一般來說可以用ID的地方不應該用CLASS,如不少設計人員喜歡不管三七二十一寫<div class="header">。但W3C規范明確指出過,具有唯一性的元素應該使用ID而非CLASS。對於搜索引擎而言,具有唯一性的元素是可以確定其出現位置的,它就更容易確定那個區塊到底在網頁上起到什麼樣的角色。
舉個實例如,以前公司裡面有一個PPC的著陸頁,明明網頁上出現過相關的關鍵詞,但那些詞的質量分依然極低。分析後發現那些關鍵詞都是被寫在<div class="footer">區塊的,這些文字就因此被當作頁面底部的和主題無關的內容,使得搜索引擎錯誤的分析了網頁,對質量分造成了負面的影響。
通俗化
通俗化在這裡指的是不要在網頁上用一些難以理解的指示性文字,比如在搜索框旁邊使用“找找看”,而非常見的“搜索”。這會給用戶帶去一定程度的困擾,也會給搜索引擎帶去更大的困擾。
搜索引擎會通過自然語言處理等方式來理解這樣的文字。大致的思路如先隨機抽取1000個網頁樣本,先人工找出網頁上面的搜索區塊,再通過機器分析這些區塊一般出現什麼樣的字眼最多。那麼相應的在分析日後其它網頁的時候,出現這樣字眼的區塊也就更可能是搜索區塊。
前面提到<div>命名的時候也差不多,<div id="header"><div id="head">等,因為都是比較常見的,搜索引擎肯定可以因此判斷它為頭部區塊。而<div id="toubu">或更糟糕的(但不罕見的)<div id="h_1">等,搜索引擎就迷茫了。最終可能搜索引擎分析出來的結果不是自己想要的。
最後
前面以輔助搜索引擎理解網頁為例,簡單介紹了讓網站對搜索引擎友好的思路。但搜索引擎不僅只是分析網頁、就以分析網頁而言,也遠遠不止上面這點內容。只能當作是思路的拓展。
如果可以的話,自己從服務器環境架設開始,從配置數據庫、從框架構建程序、書寫前端CSS與JavaScript等代碼、嘗試下Ajax、最好還自己搞定站內搜索,這樣完完整整的做一個網站(在虛擬空間上用W
- 上一頁:王少良:新浪微博SEO
- 下一頁:百度分享很可能是一只披著綿羊皮的大灰狼