當我們開始開展一項SEO工作時,第一件要做的事情是要保證我們做的任何事情都可以有數據的支撐——而不是自己的直覺。SEO的主要數據來源來自兩塊:網站的服務器日志、第三方流量分析工具。
網站服務器日志
Apache,Nginx等常用服務器的內置日志配置格式Combine已經可以滿足大多數SEO分析需求。它看上去類似是這樣的:
111.111.111.111 – - "[20/Feb/2012:18:09:25 +0800]""GET / HTTP/1.1″ 200 3121"http://***.org/" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
必須記錄的信息諸如:訪問來源IP、訪問時間、訪問頁面、HTTP響應狀態碼、訪問來源及客戶端標識等,這些在Combine日志格式裡面都有。
在確保服務器日志可以滿足其他部門的分析需求下,至少要確保上面提到的幾項被記錄在服務器日志裡面。但也不要將任何可以記錄的數據都記錄下來,只選擇實際需要的部分,不然會使得網站日志體積非常大,不利於分析起來的效率。這些內容可能需要和運維進行溝通解決。
然後關於日志的分析,我認為沒太多固定的准備工作可做,因為它的數據來源是原始的(raw似乎聽上去會更有感覺?),所以可選擇的數據維度幾乎是無限的。因此尤其要按實際需求進行相應的處理與分析。
對於一些要求並不是特別高的日志分析需求,可以嘗試使用光年日志分析系統。雖然我個人對所有圖形界面的實用類程序都不帶好感,但它提供了一些很不錯的數據維度的思路。
聽說有一家大型的旅游網站是采用MongoDB結合Map/Reduce進行日志分析的,我個人也用過MongoDB實現過前面提到的光年日志分析的一部分重要功能。所以感覺MongoDB是個可以考慮的選擇。
第三方流量分析工具
Google Analytics的安裝
對於免費流量分析工具,Google Analytics絕對是其中的佼佼者(以下簡稱GA)。不過如果網站的月浏覽量大於500W的話,只有Google Adwords的用戶,才能繼續免費使用GA進行流量的記錄與分析。下面都以它為例。
在GA添加需要追蹤流量的網站以後,它會提示你添加一段JavaScript代碼,到每一個你需要追蹤頁面的</head>標記之前。代碼的添加可能是一件很輕松的工作,但也可能非常麻煩,主要取決於網站的模板層。
先提下常見開源博客程序WordPress的方法,它采用了包含的模板處理方式,比如網站首頁、列表頁、文章頁等自身的模板,都是只有當中一部分的。而包含網頁LOGO等的網頁頭部,都使用WordPress的get_header方法來加載另一個獨立的模板文件(get_header方法本質上是PHP裡面的include函數)。簡言之,只要在header.php那個文件上面添加代碼,包含它的所有網頁都會跟著改,很快就可以把GA代碼添加好。
但情況並不總是理想的,尤其對於使用網站框架自己進行開發的網站,有時並沒有將包含這樣的方式很好的運用。這可能是網站的建設規范不完善的關系,也可能是網站需求導致了確實無法使用和WordPress類似的包含方式。那麼,至少要在每個網頁的頭部,額外包含一小段加載全局JavaScript的區塊,以方便的添加全局性的JavaScript代碼。
雖然未必在添加GA代碼時,對可能糟糕的網站模板結構去進行更改,最多到幾十個不同的模板文件裡面去分別加下代碼就是了(當然也要花些時間去保證沒有漏過哪些頁面)。但一次性搞定一些本質性的問題會帶來很多日後的便利性——比如又要換一套統計代碼。
相對最麻煩的事情或許是如何說服程序員為了一些看似小的需求而修改模板結構,這邊就略過了。
一些基礎的Google Analytics設置
對於SEO而言,一項最基礎的設置,就是要把網站上對SEO有價值的頁面進行歸類。對頁面進行區分,並以此掌握了它們的流量現狀及趨勢以後,才能把握SEO的側重點,及更好的分析網站上每次SEO修改的成效等等。
如最簡單的例子,對於一個網站,如果手頭有1000條外鏈,應該給網站的欄目頁還是產品頁?這主要取決於哪類頁面有更高的轉化率與更大的SEO流量提升空間。
對於每個網站而言,都存在不同的情況。比如一個書籍類的電商網站,它列表頁不會有太多流量,沒多少人搜索什麼“計算機書籍”,但會更多人搜索《喬布什自傳》之類,因為用戶有很明確的需求。而對於一個服飾電商,相應更多人會搜索“襯衫”之類,而非“2012年春季新款白色襯衫”等,因為用戶只是想到網站上挑衣服,他們只有需求的意向,但具體需求是模糊的。
以上兩個是比較典型的例子,但有更多情況我們無法用自己的直覺做出准確的判斷,那就需要用流量數據來收集事實。
盡管博客的流量數據分析起來沒太大價值,出色的文章是博客的一切,但這裡還是以SEMWATCH為例來簡單介紹下方法。假設我們需要把網站的欄目頁和文章頁流量進行區分,它們的URL分別是類似這樣的:/category/seo/,/2012/02/post/
首先要到GA的數據頁面內,找到高級細分一項,點擊右側新自定義細分。然後進行類似下圖的設置:
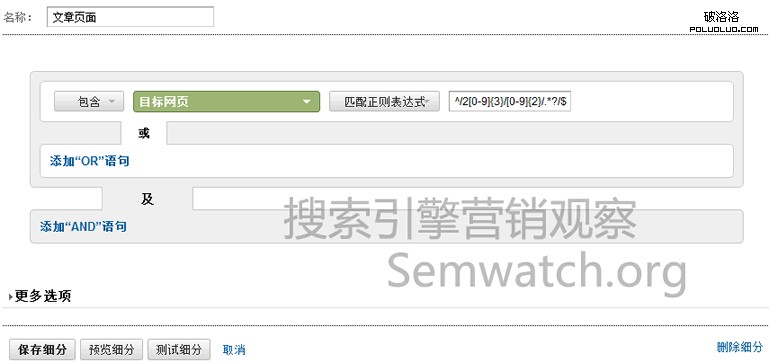
通常情況下,將頁面的URL匹配相應的正則以後,就可以把它們區分開來。注意,如果網站的初期URL規劃不完善,可能會導致無法用URL來區分頁面類型的非常非常糟糕的情況,務必保證每一類頁面擁有其獨立的URL標識。
在該例中,SEMWATCH的欄目頁匹配正則表達式是:^/category/.*?/$,文章頁是:^/2[0-9]{3}/[0-9]{2}/.*?/$
盡量用最嚴格的正則表達式寫法,這樣可能可以在無形中規避很多不必要的錯亂。還需要注意的是,老版本的GA默認情況下篩選器的“包含”即使用正則表達式,新版GA一定要選擇“匹配正則表達式”這項。
關於正