網站建設好了,當然是希望網頁被搜索引擎收錄的越多越好,但有時候我們也會碰到網站不需要被搜索引擎收錄的情況。
比如,你要啟用一個新的域名做鏡像網站,主要用於PPC 的推廣,這個時候就要想辦法屏蔽搜索引擎蜘蛛抓取和索引我們鏡像網站的所有網頁。因為如果鏡像網站也被搜索引擎收錄的話,很有可能會影響官網在搜索引擎的權重,這肯定是我們不想看到的結果。
以下列舉了屏蔽主流搜索引擎爬蟲(蜘蛛)抓取/索引/收錄網頁的幾種思路。注意:是整站屏蔽,而且是盡可能的屏蔽掉所有主流搜索引擎的爬蟲(蜘蛛)。
1、通過 robots.txt 文件屏蔽
可以說 robots.txt 文件是最重要的一種渠道(能和搜索引擎建立直接對話)。我通過分析我自己博客的服務器日志文件,給出以下建議(同時歡迎網友補充):
User-agent: Baiduspider
Disallow: /
User-agent: Googlebot
Disallow: /
User-agent: Googlebot-Mobile
Disallow: /
User-agent: Googlebot-Image
Disallow:/
User-agent: Mediapartners-Google
Disallow: /
User-agent: Adsbot-Google
Disallow: /
User-agent:Feedfetcher-Google
Disallow: /
User-agent: Yahoo! Slurp
Disallow: /
User-agent: Yahoo! Slurp China
Disallow: /
User-agent: Yahoo!-AdCrawler
Disallow: /
User-agent: YoudaoBot
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: Sogou spider
Disallow: /
User-agent: Sogou web spider
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: Tomato Bot
Disallow: /
User-agent: *
Disallow: /
2、通過 meta tag 屏蔽
在所有的網頁頭部文件添加,添加如下語句:
<meta name="robots" content="noindex, nofollow">
3、通過服務器(如:Linux/nginx )配置文件設置
直接過濾 spider/robots 的IP 段。
小注:第1招和第2招只對“君子”有效,防止“小人”要用到第3招(“君子”和“小人”分別泛指指遵守與不遵守 robots.txt 協議的 spider/robots),所以網站上線之後要不斷跟蹤分析日志,篩選出這些 badbot 的ip,然後屏蔽之。
這裡有一個badbot ip 數據庫:http://www.spam-whackers.com/bad.bots.htm
4、通過搜索引擎提供的站長工具,刪除網頁快照
比如,有的時候百度不嚴格遵守 robots.txt 協議,可以通過百度提供的“網頁投訴”入口刪除網頁快照。百度網頁投訴中心:http://tousu.baidu.com/webmaster/add
如下圖是我的一個網頁投訴:
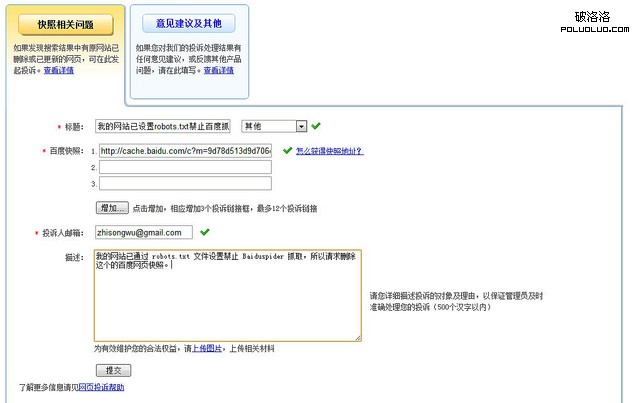
大概3天左右的時間過去,這個網頁的百度快照也被刪除,說明此種方法也能起效,當然這是不得而為之,屬於亡羊補牢。
5、補充更新
可以通過檢測 HTTP_USER_AGENT 是否為爬蟲/蜘蛛訪問,然後直接返回403 狀態碼屏蔽之。比如:由於api 權限與微博信息隱私保護原因,Xweibo 2.0 版本後禁止搜索引擎收錄。

關於如何屏蔽搜索引擎爬蟲(蜘蛛)抓取/索引/收錄網頁,您有其他什麼更好的建議或者方法,也歡迎發表評論!期待與您交流。
本文
原文地址:http://www.wuzhisong.com/blog/67/
版權聲明:歡迎轉載,但必須以超鏈接方式注明本文原始出處!