猜測百度分詞基本步驟
編輯:SEO優化集錦
最近和朋友在討論百度分詞,看了很多網上關於百度分詞的一些實例,我們來對百度的分詞步驟進行一些猜測,我們不可能真正的了解只能說是猜測:
1. 判斷用戶提交字符串,如果為多個字符串,則通過空格,標點符號,等進行切割。
2. 判斷提交字符串中有無字母或者數字,如果有把字母與數字當作獨立整體,並把這個整體當作切割負,進行前後切割。
3. 判斷切割後的詞組有無重復詞,有當作一個計算。
4. 如果提交為一個字符串,判斷字符串字數,大於4並等於4個字的進行切割,如果小於4個字不進行任何處理。
5. 對照特殊詞庫表進行提取,如果字符串中包含特殊詞進行單獨提取。
6. 進行正向分詞處理。
7. 進行反向分詞處理。
8. 正向分詞結果與反向分詞結果進行對比,如果結果一樣,直接輸出。
9. 如果結果不一樣,輸出最短路徑(詞數最少的)進行輸出。
10. 如果長度一樣進行則輸出單子最少的結果。
11. 如果單子最少結果一樣,則輸出正向分詞結果。
針對百度索引提示,糾錯原理。
1.判讀詞組,1個字的詞不進行提示,大於1個字開啟提示功能。
1.進行同音字提示,如果詞數過多,提取用戶搜索最多詞組進行提示。
除以上外,我們還需要注意一點,那就是現在分詞中進行了語意相關結合:
舉個例子我們常常在搜索某些詞的時候會發現有些結果中並不是完全匹配的詞也進行了飄紅。其實這種情況就是語意結合。我們可以理解為百度把相關詞表進行了關聯,或者干脆進行了表結合。造成了這種情況的出現。
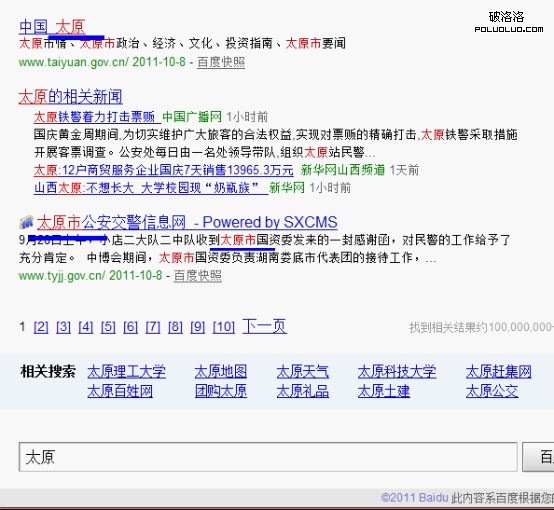
比如我們搜索太原,我們會發現太原與太原市都進行了飄紅。
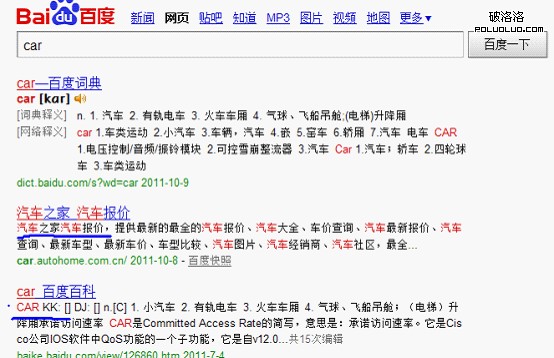
搜索英文car,car與汽車都進行了飄紅。
我的小站www.6cs.net(2011時尚冬裝)歡迎指點。(轉載請保留)
小編推薦
熱門推薦