昨天和主管聊搜索引擎蜘蛛抓取網頁的特點,主管一句話“百度蜘蛛抓取網頁層次淺,如果用robots.txt文件靜止,則導致網站收錄停止”則讓我心裡有個疑問,難道真的是這樣的?我的博客是8.12建立了,建立後寫了幾篇原創文章同時轉載了部分文章,有幾篇文章還在站長之家、站長網等網站投稿了,外部鏈接也做了點,可是百度只收錄首頁,死活不收錄其他頁面,而且首頁快照也不更新。聯系到這句話,因為博客的robots.txt文件屏蔽了css文件(Disallow:/*.css$),所以昨晚決定發篇文章,修改下robot.txt文件,等待百度更新,今天觀察結果。
首先、通過站長工具-seo綜合查詢結果如下圖:
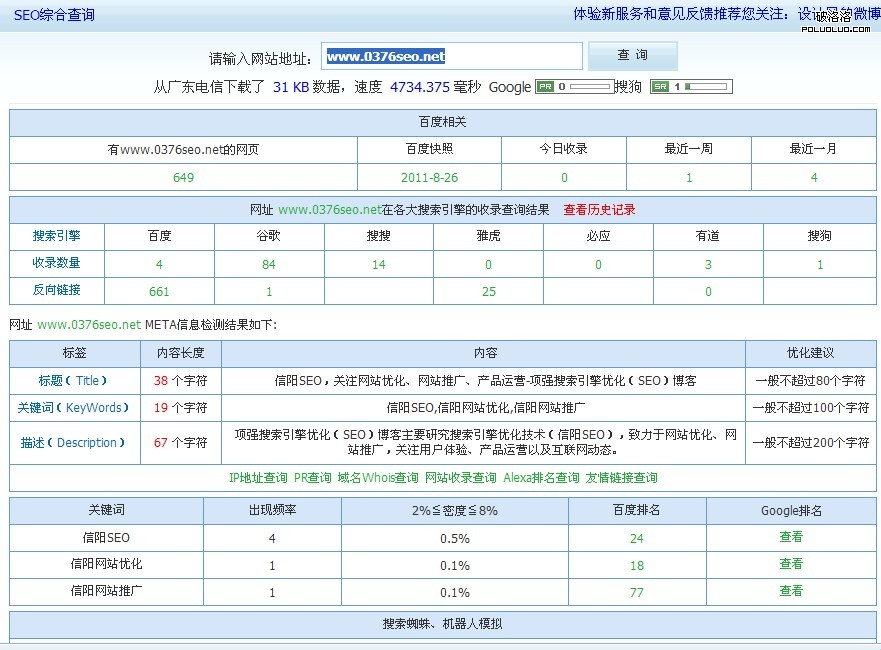
百度收錄量:總收錄量:4;今日收錄:0;最近一周:1;最近一月:4。
百度反向鏈接:661個。
百度排名:信陽seo:24;信陽網站優化:18;信陽網站推廣:77
第二、看搜索引擎收錄歷史數據。
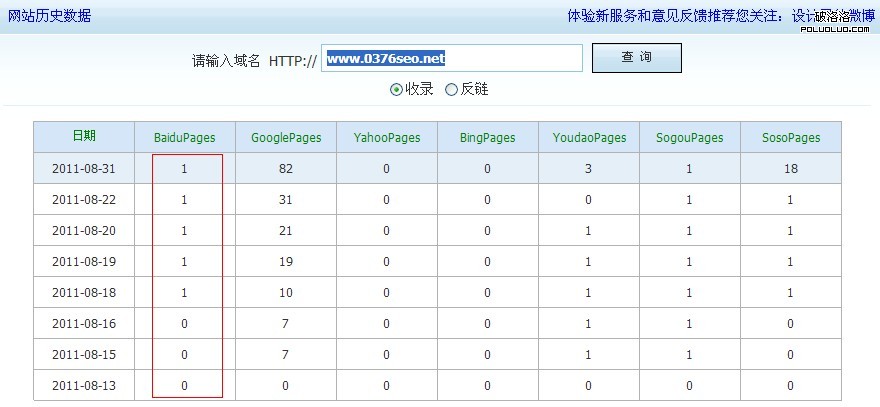
從2011-08-13到2011-08-31百度對博客收錄量從0增加到1後維持不變。相比情況下,google收錄量則從0增加82。其他搜索引擎大都停止收錄。
再看搜索引擎反向鏈接的歷史數據。
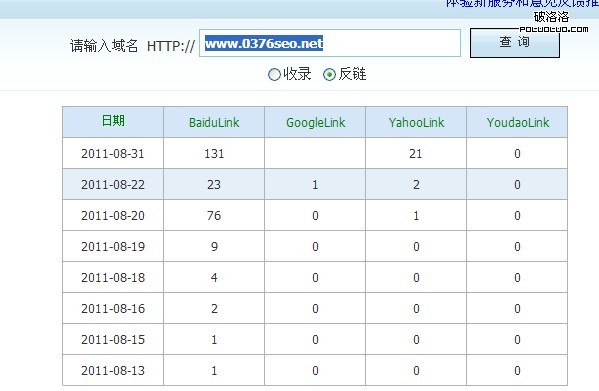
從2011-08-13到2011-08-31百度反向鏈接從1增加到131,google反向鏈接從0增加到1(google反向鏈接增加較慢),雅虎反向鏈接則從0增加到21,有道反向鏈接一直為0。
從百度反應來看,robots.txt文件屏蔽css可能就是導致百度對網站停止收錄的原因了。晚上與朋友聊天,朋友說了個觀點:因為博客的css文件(http://www.0376seo.net/wp-content/themes/prowerV3/prowerV3/style.css)裡有隱藏代碼(“Display:none;”)一旦屏蔽搜索引擎蜘蛛抓取就會被搜索引擎判定為作弊。本來css文件隱藏代碼是出於頁面布局或其他需要而不得以為之的策略,一旦屏蔽蜘蛛抓取,當蜘蛛抓取頁面時,發現隱藏文字,而此時又無法抓取css文件,所以就判定為作弊。
在博客的css文件中有二處隱藏代碼:
#nav li ul,.says{display:none;}
*html#go_top{display:none;}
對照頁面代碼找到具體的xhtml代碼:
<div id="go_top"><em></em><a href="#">返回頂部</a></div>
<span class="says">說道:</span>
最後百度搜索“robotscssseo”找到seowhy的一個帖子“robots.txt屏蔽css文件的疑問……作弊有關”。
今天就這個問題我請教了seo界的一些達人,答案不一。但大多認為這是作弊的打擊對象。
其中有個我個人認為比較合理的答案寫出來供大家參考:
“robots.txt文件能阻止搜索引擎收錄,但依然能讀取,結果還是會被判定為作弊”。
我的博客在建立之初,robots.txt文件是參考搜索引擎上一些博客的寫法,不假思索地照抄進來,導致被百度判定為作弊。
試驗:
2個新站,采用同樣的系統(dedecms),空間相同配置,域名年齡相近,一個設置robots.txt文件禁止抓取css,另一個則不禁止。然後同時提交到百度,持續一段時間觀察百度反應。
信陽seo原創文章,原文地址:http://www.0376seo.net/54.html轉載請注明!
- 上一頁:如何讓網站百度快照天天更新
- 下一頁:避免蜘蛛爬行和索引錯誤的技巧:繞開沖突