前面我們講個搜索引擎如何搜集網頁,今天說下第二個過程網頁預處理,其中中文分詞就顯得尤其重要,下面就詳細講解一下搜索引擎是怎麼進行網頁預處理的:
網頁預處理的第一步就是為原始網頁建立索引,有了索引就可以為搜索引擎提供網頁快照功能;接下來針對索引網頁庫進行網頁切分,將每一篇網頁轉化為一組詞的集合;最後將網頁到索引詞的映射轉化為索引詞到網頁的映射,形成倒排文件(包括倒排表和索引詞表),同時將網頁中包含的不重復的索引詞匯聚成索引詞表。如下圖所示:
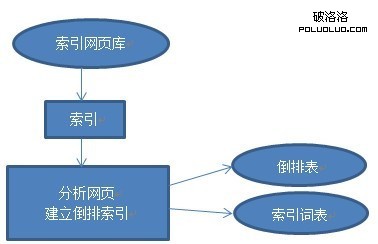
一個原始網頁庫由若干個記錄組成,每個記錄包括記錄頭部信息(HEAD)和數據(DATA),每個數據由網頁頭信息(header),網頁內容信息(content)組成。索引網頁庫的任務就是完成給定一個URL,在原始網頁庫中定位到該URL所指向的記錄。
如下圖所示:

對索引網頁庫信息進行預處理包括網頁分析和建立倒排文件索引兩個部分。中文自動分詞是網頁分析的前提。文檔由被稱作特征項的索引詞(詞或者字)組成,網頁分析是將一個文檔表示為特征項的過程。在對中文文本進行自動分析前,先將整句切割成小的詞匯單元,即中文分詞(或中文切詞)。切詞軟件中使用的基本詞典包括詞條及其對應詞頻。
自動分詞的基本方法有兩種:基於字符串匹配的分詞方法和基於統計的分詞方法。
1) 基於字符串匹配的分詞方法
這種方法又稱為機械分詞方法,它是按照一定的策略將待分析的漢字串與一個充分大的詞典中的詞條進行匹配,若在詞典中找到某個字符串,則匹配成功(識別出一個詞)。
按照掃描方向的不同,串匹配分詞方法可以分為正向匹配和逆向匹配;按照不同長度優先匹配的情況,可以分為最大或最長匹配,和最小或最短匹配;按照是否與詞性標注過程相結合,又可以分為單純分詞方法和分詞與標注相結合的一體化方法。常用的幾種機械分詞方法如下:
1. 正向最大匹配;
2. 逆向最大匹配;
3. 最少切分(使每一句中切出的詞數最小)。
還可以將正向最大匹配方法和逆向最大匹配方法結合起來構成雙向匹配法。由於漢語單字成詞的特點,正向最小匹配和逆向最小匹配一般很少使用。一般說來,逆向匹配的切分精度略高於正向匹配,遇到的歧義現象也較少。
對於機械分詞方法,可模型化表示為ASM(d,a,m),即 Automatic Segmentation Model。其中,
d:匹配方向,+表示正向,-表示逆向;
a:每次匹配失敗後增加或減少字串長度(字符數),+為增字,-為減字;
m:最大或最小匹配標志,+為最大匹配,-為最小匹配。
例如,ASM(+, -, +)就是正向減字最大匹配法(Maximum Match based approach,MM),ASM(-, -, +)就是逆向減字最大匹配法(簡記為RMM方法)。
2)基於統計的分詞方法
從形式上看,詞是穩定的字的組合,因此上下文中,相鄰的字同時出現的次數越多,就越有可能構成一個詞。因此字與字相鄰共現的頻率或概率能夠較好的反映成詞的可信度。
可以對語料中相鄰共現的各個字的組合的頻度進行統計,計算它們的互現信息。
互現信息體現類漢字之間結合關系的緊密程度。當緊密程度高於某一個阈值時,便可認為此字組可能構成了一個詞。這種方法只需對語料中的字組頻度進行統計,不需要切分詞典,因而又叫做無詞典分詞法或統計取詞方法。
實際應用的統計分詞系統都要使用一部基本的分詞詞典(常用詞詞典)進行串匹配分詞,同時使用統計方法識別一些新的詞,即將串頻統計和串匹配結合起來,既發揮匹配分詞切分速度快、效率高的特點,又利用了無詞典分詞結合上下文識別生詞、自動消除歧義的優點。
感謝 落楓seo 的投稿
正向減字最大匹配法
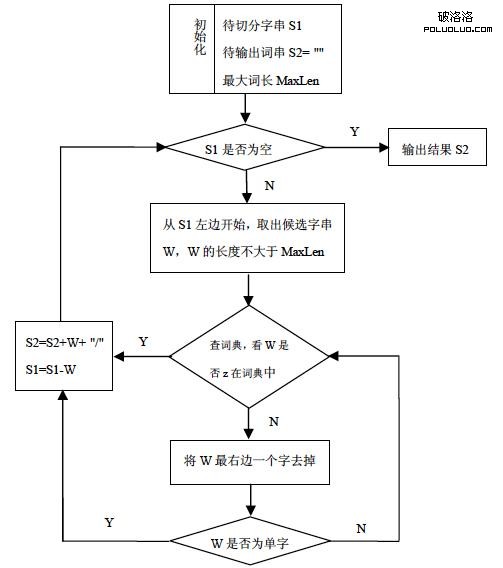
這是主要的中文切詞方法,正向減字最大匹配法切分的過程是從自然語言的中文語句中提取出設定的長度字串,與詞典比較,如果在詞典中,就算一個有意義的詞串,並用分隔符分隔輸出,否則縮短字串,在詞典中重新查找(詞典是預先定義好的)。
算法要求為:
輸入:中文詞典,待切分的文本d,d中有若干被標點符號分割(我們可以利用標點符號協助搜索引擎准確分詞)的句子s1,設定的最大詞長MaxLen。
輸出:每個句子s1被切為若干長度不超過MaxLen的字符串,並用分隔符分開,記為s2,所有s2的連接構成d切分之後的文本。
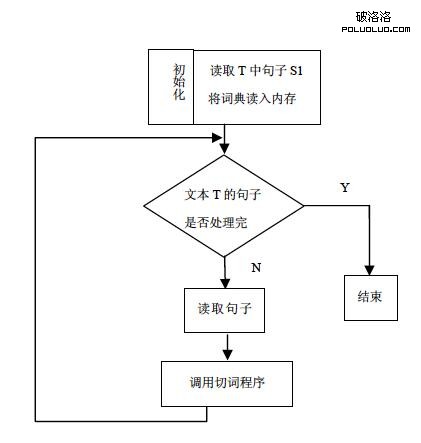
該中文分詞的算法思想是:事先將網頁預處理成每行是一個句子的純文本格式。從d中逐句提取,對於每個句子s1從左向右以MaxLen為界選出候選字串w,如果w在詞典中,處理下一個長為MaxLen的候選字段;否則,將w最右邊一個字去掉,繼續與詞典比較;s1切分完之後,構成詞的字符串或者此時w已經為單字,用分隔符隔開輸出給s2。從s1中減去w,繼續處理後續的字串。s1處理結束,取T中的下一個句子賦給s1,重復前述步驟,直到整篇文本d都切分完畢。其中MaxLen是一個經驗值,通常設為8個字節(即4個漢字),MaxLen過小,長詞會被切斷;過長,又會導致切分效率低。