淺談百度的中文分詞三點原理
編輯:SEO優化集錦
百度中文分詞算法:指搜索引擎為了更好的辨別用戶的需求,並且為了快速提供給用戶需求性信息而使用的算法。
搜索引擎要在單位時間內處理千萬億級的頁面數據量,因此搜索引擎擁有一個中文詞庫。比如百度現在大約有9萬個中文詞,那麼搜索引擎就可以對千億級的頁面進行分析,按照中文詞庫進行了分類。
百度分詞基本有三種分法
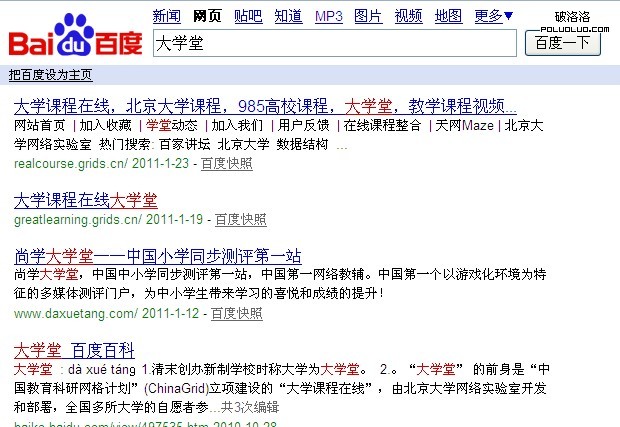
1、基於理解:傻瓜式匹配,小於等於3個中文字符百度是不進行切詞的,比如搜索“大學堂”。
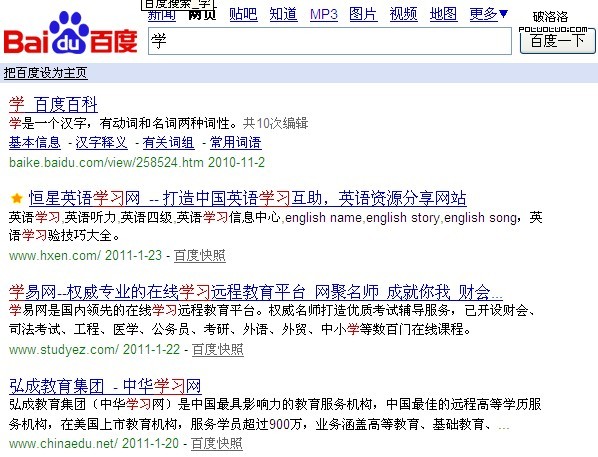
2、基於統計:百度把一個詞標紅的原因:標紅的詞一般是一個關鍵詞,你搜索“學”字的時候,百度它自認的把“學習”也當成了一個關鍵詞,所以出現“學習”這個詞標紅,這就是百度分詞法:基於統計分詞。
3、基於字符串匹配(百度的分詞法:正向最大切詞法)
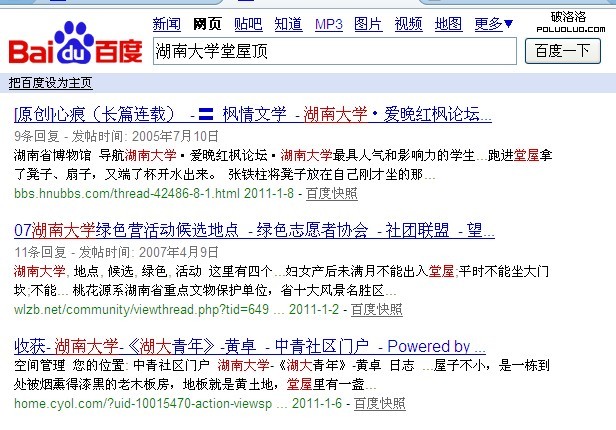
最大與最小(最大匹配:一直匹配到沒詞可配;最小匹配:匹配出詞了就停止匹配,再從另一個詞開始匹配)比如:百度搜索“湖南大學堂屋頂”,百度的一個分詞算法我們把它當成一個黑盒子,我們通過一些輸入關鍵詞,根據百度的輸出結果來判定百度的分詞算法。正向與反向(正向:從前往後配;反向:從後往前配)(湖南大學堂屋頂)正向分法:湖南大學 堂屋 頂 (劉強大地方法)正向分法:劉 強大 地方 法。反向分法:方法 大地 劉 強。而在這個詞語當中“大地”不是一個詞。
另外,切詞原理:百度有專有詞庫(是不可分割的)比如傑出人物(如:毛澤東)明星(如:劉德華)檢索量大的詞(如:買票難) 。
當然這些只是百度中文分詞原理的一部分,也不是全對。因為百度算法是不可能透露出來,商業機秘如果讓你知道,那豈不是有N多的百度了。
感謝 北京SEO 的投稿
小編推薦
熱門推薦