首先提前祝各同仁們happy new year,在即將迎來2011年的最後一天,利用這今年的最後一天,來給大家分享一個話題:關於搜索引擎預處理機制,可能一些seo新手對這個詞有點陌生,沒什麼概念,其實很簡單,就是網站有千千萬,頁面達到億級別的,而搜索引擎卻能通過一個簡短的詞就能把搜索結果快速的傳遞到用戶面前,為什麼這麼快呢?難道真是它的電腦或者服務器很強嗎?其實它是采用了一種很巧妙的辦法,因為它先有預處理機制在裡面,通過預處理之後才能快速的把用戶想要找的內容呈現在他面前,那預處理包括哪些內容呢,我們來簡單的跟大家說下:
一、提取文字
預處理要做的第一件事情就是抓取文字,在提取文字這一部分是非常關鍵的,意思也很簡單,因為文字一般都是有一個相關性的,就是把關鍵文字提取出來,提取的文字內容有文本、meta標簽,這兩個是我們通過表面現象可以看得到的,另外還有關鍵和描述(這兩個需要通過頁面源代碼查看),還有alt屬性(alt屬性原本是看不到的,鼠標移上去會顯示)。還有文本,比如像做過flash站優化的人知道,你可以將它的內容提取出來,作為替代內容,這些都是可以被搜索引擎識別的。
二、中文分詞
抓取好文字之後我們要進行中文分詞,也就是我們經常提到的中文分詞技術,為了方便大家更好的理解,我們舉例來說,大家先打開baidu和goole,然後分別在裡面搜索“誇張大千獎”,我們先看百度頁面的搜索情況:
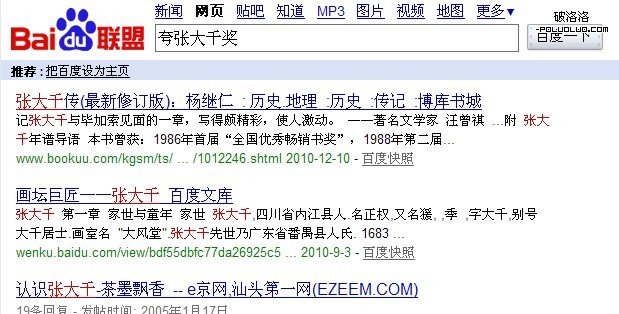
通過上圖我們可以看到整個頁面的標紅的字體,我們可以明顯的看到“張大千”這三個字被擰出來了,總共五個字,因為張大千是個人名,所以它優先被擰了出來,然後這個詞就變成三個詞組,分別是“誇”。“張大千”。“獎”。這是百度的分詞手法,我們再來看谷歌是怎麼分的:

我們看第一條搜索結果,“誇張的圖,大千世界無奇不有啊”,為什麼會這樣呢?其實谷歌和百度相比,它少了一個專有詞典,匹配方式不一樣,不同的搜索引擎,它的分詞規律不一樣,所以說針對不同搜索引擎關鍵詞優化,我們應該要注意關鍵詞應該怎麼寫會比較穩妥。可以根據自身情況,做谷歌要怎麼寫,做百度又要怎麼寫,而且我們要知道,我們如何利用分詞技術來做到不管是關鍵詞還是內容等等都可盡量匹配。如果連內容都匹配不了,那關鍵詞又怎麼能上去呢?
2、匹配方法
關於匹配方法我們簡單概括下:
A.正向匹配:因為我們一般的閱讀方式是從左往右,從左到右叫正向匹配,比如說“中華人民共和國成立於1949年”因為它是一個完整詞,如果是正向匹配,那麼就應該這樣分:“中華”“人民”“共和”等。
B.逆向匹配:顧名思義,就是從後面往前匹配。
c.最大匹配:比如說“中華人民共和國成立於1949年”,如果是最大匹配的話,可以劃分成“中華人民共和國”為一個詞組,這就是最大匹配。
D.最小匹配:它就可是把“中華人民共和國”劃分成“中華”“人民”“”共和”“國”。這樣算起來總共有四種匹配方式:正向匹配、逆向匹配、最大匹配、最小匹配。可以兩兩結合結合成“正向最大匹配”“正向最小匹配”“逆向最大匹配”“逆向最小匹配”,這是百度和谷歌通用的匹配方法。那說到這裡,可能有人會問了:那我怎麼知道它是給我正向匹配還是反向匹配等,其實我想說的是,這個沒有一個定死的規律的,我們只要記住一點:一個好的搜索引擎,在分詞系統關鍵就看兩點:
A:消除歧義能力,也就是說你搜了一個詞,搜索出來的結果更加精准、完整;
B:它是否能識別人名、地名和機構名,也就是一些未登陸的詞,比如比較流行的口頭語,搜索次數多了,它會進行一個統計,統計的結果和用戶想了解的內容匹配度高,具備這兩點,就是好的分詞系統。
搜索引擎的分詞能讓我們的標題以及內容相關性更高,和需要優化的詞匹配度更高,這是分詞它所能承載的作用,不用的搜索引擎的分詞原理不一樣,所以需要我們更加系統的來學習,僅僅靠這篇文章是解釋不完的,關鍵是要有這個思路,結合這個思路去仔細觀察從而得出結論。
通過以上講解,大家是不是對索引引擎機制度和中文分詞是不是有了初步的了解了呢,今天就跟大家說到這裡,再次祝你們新年快樂,想學更過seo知識請到(杭州seo www.gdwzjs.com)
感謝 杭州seo小傑 的投稿
- 上一頁:我的網站有必要做SMO優化嗎?
- 下一頁:站長總結如何做好網站搜索優化工作