在我剛接觸SEO的時候,我曾經有去仔細的觀察過搜索引擎。一方面做SEO的本身就是靠著搜索引擎而活,我們必須得把這位大哥給伺候好了;再一方面是想看看他是如何工作的,他是如何實現幾萬個頁面能在一秒鐘內做到有序排名。在今天其實對於這些問題都已經有了一個比較清晰的概念。
想在某個搜索引擎具有一定的排名,光知道網上的那些SEO基礎那完全不夠。我也有遇到過一些朋友把自己的站排名做上去了,但他不知道是怎麼做上去的。他告訴我的是做做外鏈,更新更新文章就上去了。我們不能排除有這種可能性畢竟關鍵詞的競爭度都是不一樣的。但我遇到過最多的還是做上排名了,但很快又掉下來了,根本不知道如何去保持這個排名。廢話也不多說了,跟著何濤的思路一步一步往下走。
首先我們得提一個SEO的專有名詞“蛛蛛”。這個也是每個搜索引擎用來爬行和訪問頁面的一個程序,也叫機器人。這裡我為蛛蛛這個名詞做一下解釋:在我看來,之所以把他稱為蛛蛛。是因為蛛蛛都是順著網上的鏈接代碼來訪問互聯網上的每個網站,而且每個網站的這些鏈接其實就像一張非常復雜的網,蛛蛛要做的就是在這張網上抓取信息,這個形式非常類似蛛蛛這個動物,所以也就有了一個形像的比喻。
從蛛蛛這個名詞我們是否已經有點感悟了呢?原來搜索引擎的一些必須要更新的數據庫與排名順序都是要靠這麼一個程序來抓取、檢索才會在定期有個更新。那麼也就是說:想讓我們的網站有排名,是不是一定得先讓搜索引擎收錄我們的站,想讓搜索引擎收錄,是不是又先得讓蛛蛛來爬我們的站。其實這裡面就會有一個過程,如何讓蛛蛛爬行我們的網站這裡我也大概的說一下:
一般來說我們把這個方式叫做“鏈接誘餌”。也就是說通過某種手段吸引蛛蛛來爬行我們的網站。常見的比如去把我們剛做好的網站提交給搜索引擎、通過在高權重的網站發布鏈接、通過搜索引擎的種子站來做引導等,這些都是比較好用的辦法。
我們再來看一下蛛蛛他的一些習慣,好讓我們更好的掌握它,從而不斷的給他喂食,培養蛛蛛訪問網站的速度與習慣從而提高網站的權重獲得一定的排名
說到蛛蛛習慣我們不得不得一個概念“深度優先、廣度優先”。前面我們已經有說到蛛蛛最終還是個程序,能牽引他爬行的是網站與網站之間的鏈接。大家有沒有印象在看一些SEO基礎教程的時候,都有說到一個網站的結構一定要樹形,而且目錄級別不要過深。其實這點的說法就來源於深度優先與廣度優先。
深度優先:比如蛛蛛訪問一個網站的鏈接,他就會一直順著這個鏈接一直往下爬,直到前面再也沒有鏈接的時候然後再返回第一個頁面,沿著另外一個鏈接再向前爬。好比蛛蛛訪問我們的網站首頁,從它的一個爬行習慣必定會是從導航裡的一個欄目一直往下爬行,可能爬到我們的最終頁就再次返回。
廣度優先:這個與深度優先有點不一樣,這個方式的表現形式當蛛蛛在一個頁面上發現多個鏈接的時候,他會先把第一層鏈接都爬一遍,然後再沿著第二層頁面上發現的鏈接爬向下一層。下面我給大家看張圖就會明白了
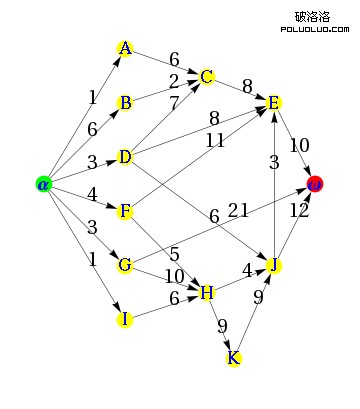
其實在我們現實中,蛛蛛他往往是把廣度優先與深度優先相結合來使用的,這樣就可以盡可能的照顧到多的網站(廣度優先),也能照顧到一一部分網站的內頁(深度優先)
有了這樣的數據抓取原理,搜索引擎必定會把這些通過蛛蛛抓取回來的信息首先做一個初步的整理與存儲,並會對每一個信息給予特定的編號。
上面只是說到搜索引擎的一些基本的抓取情況,對於他的進一步是如何處理請繼續關注從搜索引擎工作原理折射出的SEO知識(中)
文章摘自:寧波何濤SEO博客:http://www.nb-seoer.com/post/153.html
感謝 何濤 的投稿