URL的問題是SEO過程中的一個基本問題,做一個新網站也好,優化現有的網站也好,都繞不開這一點。這兩篇文章就來大體總結一下URL的規劃應該怎麼做。
在開始講這些問題之前,需要先閱讀完以下文檔:
《優化網站的抓取與收錄》 http://www.google.cn/ggblog/googlewebmaster-cn/2009/08/blog-post.html
《谷歌搜索引擎入門指南》第7頁到11頁。 點此下載
《創建方便 Google 處理的網址結構》 http://www.google.com/support/webmasters/bin/answer.py?hl=cn&answer=76329
這些都是google官方的文檔,講述了各種各樣的規則。這些對百度也是同樣適用的,因為它是針對爬蟲的特性提出來的,並不是只有某個搜索引擎才適用。
看完上面的那些這些規則,發現翻來覆去講得都是怎麼讓爬蟲能非常順暢的抓取完整個網站。其實絕大部分網站都存在這樣或那樣的問題的,也包括我這個博客,在抓取方面也存在一些問題。但是看在每篇博文都能被收錄的情況下,也就不去優化了。但是對於很多收錄還成問題的網站(特別是大中型網站)來說,就要好好規劃一下了。大家可以用HTTrack抓取semyj這個博客看看,就能發現為什麼我這麼說了。(誰能一天之內抓取完這個博客的人請告訴我。)
還是先從搜索引擎的處境講起吧。正如Google在文章中寫道的那樣:
網絡世界極其龐大;每時每刻都在產生新的內容。Google 本身的資源是有限的,當面對幾近無窮無盡的網絡內容的時候,Googlebot 只能找到和抓取其中一定比例的內容。然後,在我們已經抓取到的內容中,我們也只能索引其中的一部分。
URLs 就像網站和搜索引擎抓取工具之間的橋梁: 為了能夠抓取到您網站的內容,抓取工具需要能夠找到並跨越這些橋梁(也就是找到並抓取您的URLs)。
這段話很好的總結了搜索引擎所面臨的處境,那麼爬蟲在處理URL的時候會遇到哪些問題呢?
我們先來看重復URL的問題,這裡說的重復URL是指同一個網站內的不同頁面,都存在很多完全相同的URL。如:
http://www.semyj.com/archives/1097 和 http://www.semyj.com/archives/1114 這兩個頁面。
模板部分的URL是一樣的
雖然頁面不同,但是他們公用的部分,URL地址是一樣的。看起來如果不同的爬蟲抓取到這些頁面的時候,會重復抓取,從而浪費很多不必要的時間。 這確實是一個問題,不過這個問題搜索引擎倒是基本解決好了。實際上,爬蟲的抓取模式不是像我們理解的那樣看到一個網頁就開始抓取一個網頁的。
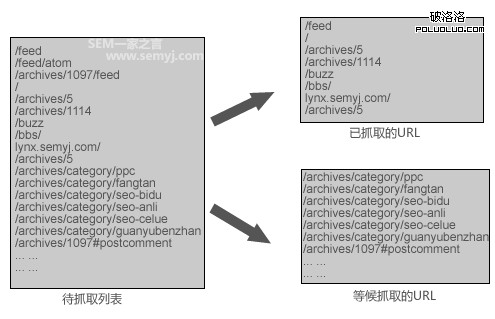
爬蟲順著一個個的URL在互聯網上抓取網頁,它一邊下載這個網頁,一邊在提取這個網頁中的鏈接。假設從搜索引擎某一個節點出來的爬蟲有爬蟲A、爬蟲B、爬蟲C,當它們到達semyj這個網站的時候,每個爬蟲都會抓取到很多URL,然後他們都會把那個頁面上所有的鏈接都放在一個公用的“待抓取列表”裡。(可以用lynx在線版模擬一下爬蟲提取鏈接。)

待抓取列表
這樣一來,在“待抓取列表”裡,那些重復的URL就可以被去重了。這是一個節點在一種理想狀態下的情況,不過實際上因為搜索引擎以後還要更新這個網頁等等一些原因,一個網站每天還是有很多重復抓取。所以在以前的文章中,我告訴大家用一些方法減少重復抓取的幾率。
這裡有一個問題,很多人肯定想問是不是一個網頁上所有的鏈接搜索引擎都會提取的,答案是肯定的。但是在《google網站質量指南》中,有這樣一句:“如果站點地圖上的鏈接超過 100 個,則需要將站點地圖拆分為多個網頁。”有些人把這句話理解為:“爬蟲只能抓取前100個鏈接”,這是不對的。
因為在“待抓取列表”裡的URL,爬蟲並不會每一個鏈接都會抓取的。 鏈接放在這個列表裡是沒問題的,但是爬蟲沒有那麼多時間也沒必要每個鏈接都要去抓取,需要有一定的優先級。在“待訪問列表”裡,爬蟲一邊按照優先級抓取一部分的URL,一邊把還未被抓取的URL記錄下來等待下次抓取,只是這些還未被抓取的URL,下次爬蟲來訪問的頻率就每個網站都不一樣了, 每一類URL被訪問的頻率也不一樣。
按優先級抓取
那麼在“待抓取列表”裡的URL,哪些是能被優先抓取,哪些是被次要抓取的呢?
我們稍微思考一下都能明白這個抓取的優先級策略應該怎麼定。首先,那些目錄層級比較深的URL是次要抓取的;那些在模板部分的或重復率非常高的URL是被次要抓取的;那些動態參數多的URL是次要抓取的…。.
這麼做的原因,就是因為搜索引擎的資源是有限的,一個網站實際擁有的內容也是有限的,但是URL數量是無限的。爬蟲需要一些“蛛絲馬跡”來確定哪些值得優先抓取,哪些不值得。
在《谷歌搜索引擎入門指南》中,google建議要優化好網站的URL結構,如建議不要用“…/dir1/dir2/dir3/dir4/dir5/dir6/page.html
- 上一頁:搜索與搜索營銷隨筆
- 下一頁:近期新站沙盒效應的全方位分析總結