一、了解爬行器或爬行蜘蛛
我們知道,之所以我們能夠在百度、谷歌中很快地找到我們需要的信息,就是因為在百度和谷歌這樣的搜索引擎中,已經預先為我們收錄了大量的信息。不管是哪方面的信息,不管是很早以前的,還是最近更新的,都能夠在搜索引擎中找到。
那麼,既然搜索引擎需要預先收錄這些大量的信息,那麼它就必須到這個浩瀚的互聯網世界是抓取這些信息。據報道,全球網民已經達到十幾億的規模了,那麼這十幾億網民中,可想而知,每天能夠產生多少信息?搜索引擎又有何能耐把這麼多的信息收錄在自己的信息庫中?它又如何做到以最快的速度取得這些信息的呢?
首先,了解什麼是爬行器(crawler),或叫爬行蜘蛛(spider)。稱謂很多,但指的都是同一種東西,都是描述搜索引擎派出的蜘蛛機器人在互聯網上探測新信息。而各個搜索引擎對自己的爬行器都有不同的稱謂:百度的叫Baiduspider;Google的叫Googlebot,MSN的叫MSNbot,Yahoo則稱為Slurp。這些爬行器其實是用計算機語言編制的程序,用以在互聯網中不分晝夜的訪問各個網站,將訪問的每個網頁信息以最快的速度帶回自己的大本營。
二、搜索引擎每次能帶回多少信息
要想這些爬行蜘蛛每次能夠最大最多的帶回信息,僅僅依靠一個爬行蜘蛛在互聯網上不停的抓取網頁肯定是不夠的。所以,搜索引擎通過都會派出很多個爬行蜘蛛,讓它們通過浏覽器上安裝的搜索工具欄,或網站主從搜索引擎提交頁面提交而來的網站為入口開始爬行,爬行到各個網頁,然後通過每個網頁的超級鏈接進入下一個頁面,這樣不斷的繼續下去……
搜索引擎並不會將整個網頁的信息全部都取回來,有些網頁信息量很大,搜索引擎都只會取得每個網頁最有價值的信息,一般如:標題、描述、關鍵詞等。所以,通過只會取得一個頁面的頭部信息,而且也只會跟著少量的鏈接走。百度大概一次最多能抓走120KB的信息,谷歌大約能帶走100KB左右的信息,因此,如果想你的網站大部分網頁信息都被搜索引擎帶走的話,那麼就不要把網頁設計得太長,內容太多。這樣,對於搜索引擎來說,既能夠快速閱讀,又能夠帶走所有信息。
三、蜘蛛們是如何爬行的?
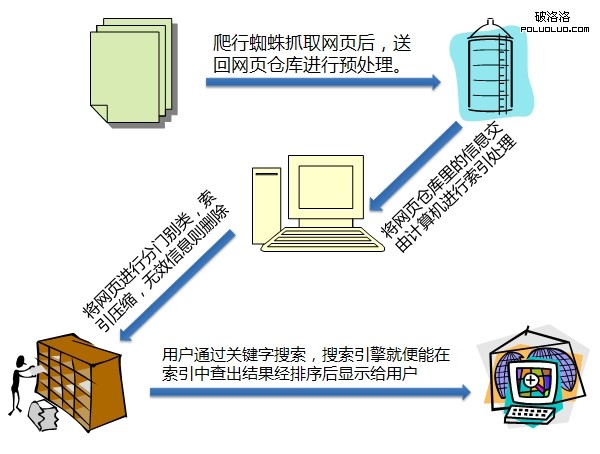
所有的蜘蛛的工作原理都是首先從網絡中抓取各種信息回來,放置於數據倉庫裡。為什麼稱為數據倉庫?因為此時的數據是雜亂無章的,還是胡亂的堆放在一起的。因此,此時的信息也是不會出現在搜索結果中的,這就是為什麼有些網頁明明有蜘蛛來訪問過,但是在網頁中還不能找到結果的原因。
搜索引擎將從網絡中抓取回來的所有資料,然後通過關鍵字描述等相關信息進行分門別類整理,壓縮後,再編類到索引裡,還有一部分抓取回來經過分析發現無效的信息則會被丟棄。只有經過編輯在索引下的信息,才能夠在搜索結果中出現。最後,搜索引擎則經過用戶敲擊進的關鍵字進行分析,為用戶找出最為接近的結果,再通過關聯度由近及遠排列下來,呈現在最終用戶眼前。
其大致過程如下圖:
四、重點介紹Google搜索引擎
Google搜索引擎使用兩個爬行器來抓取網頁內容,分別是:Freshbot和Deepbot。深度爬行器(Deepbot)每月執行一次,其受訪的內容在Google的主要索引中,而刷新爬行器(Freshbot)則是晝夜不停的在網絡上發現新的信息和資源,之後再頻繁地進行訪問和更新。因為,一般Google第一次發現的或比較新的網站就在Freshbot的名單中進行訪問了。
Freshbot的結果是保存在另一個單獨的數據庫中的,由於Freshbot是不停的工作,不停的刷新訪問內容,因些,被它發現或更新的網頁在其執行的時候都會被重寫。而且這些內容是和Google主要索引器一同提供搜索結果的。而之前某些網站在一開始被Google收入,但是沒幾天,這些信息就在Google的搜索結果中消失了,直到一兩個月過去了,結果又重新出現在Google的主索引中。這就是由於Freshbot在不停的更新和刷新內容,而Deepbot要每月才出擊一次,所以這些在Freshbot裡的結果還沒有來得及更新到主索引中,又被新的內容代替掉。直到Deepbot重新來訪問這一頁,收錄才真正進入Google的主索引數據庫中!
【相關鏈接】
搜索引擎優化教程(一):認識搜索引擎優化
本文章始發於“獨語斜欄”個人博客:http://www.nannannan.com/post/28.html轉載請注明出處。
- 上一頁:淺析網站頁面優化之分頁及網站底部處理
- 下一頁:教你快速提升PR的捷徑