眾所周知,內容重復是搜索引擎優化中的一大忌,通常情況下轉載的文章是很難獲得高權重,所以站長們往往使用偽原創,下面是部分關於內容復制的信息圖表,相信對各位會有所幫助。
#1 從博客上復制內容:

上圖是主要針對博客這種網站媒體類型的,我們使用wordpress的時候經常將文章毫無保留地展示在首頁,而不是使用輸出摘要(就好像SEMWATCH那樣),根據Randfish觀察,其實這樣子是會搜索引擎誤認為內容重復。
#2 URL參數引起的內容重復

究竟URL參數像Session IDs,Tracking IDs是怎樣引起內容重復的呢?Googlewebmastercentral (需要翻牆) 透露,同一個產品頁面,如果搜索引擎爬蟲抓取可以通過多種鏈接途徑抓取同一個產品頁面,那樣會有以下幾種消極的影響:
1.多種URLs會稀釋鏈接的廣泛性。比如上圖的產品頁面,如果有50個導入鏈接,那有可能分別形成了3種導入URL途徑,而不是唯一的某一個URL,這樣就等於將導入鏈接傳遞的權重分散到3個不同的鏈接上。
2.搜索結果或許會呈現不友好的URL(比如一大串長長 的session ID,tracking ID)。從而在SERP中,降低了用戶對該頁面的清晰了解程度(英文url比如semwatch.org/sem,不僅僅具備搜索引擎友好性,更重要的是用戶體驗友好性),不利於品牌的塑造。
#3 搜索引擎對待內容重復的態度
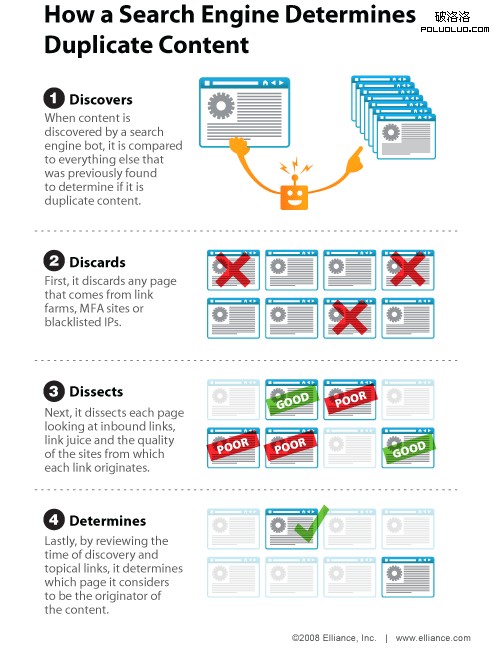
從Search Engine Land給出上圖可知,一般來說搜索引擎通過4個步驟來識別內容是原創還是復制:
1.發現。當搜索引擎爬蟲發現新的內容,他會立刻與之前收錄的內容進行比較確保內容的原創性。
2.丟棄。首先,搜索引擎會放棄收錄那些來自鏈接工廠,MFA站點(Made For Adense)和被列入黑名單的IP的頁面
3.解剖。下一步就是分析每個頁面的 入站鏈接,判斷鏈接的質量和源頭。
4.決定。最後就是回顧之前收錄的頁面和相關鏈接,決定哪一個頁面才是絕對原創。
#4 關鍵詞拆解

搜索引擎會蜘蛛通過你的某一個特定頁面爬行4個或者40個網站上不同的頁面,而這種行為一般是通過該頁面的相關內容鏈接進行爬行抓取(比如上圖的“滑雪板),很多朋友希望通過將眾多頁面相互關聯起來即使相互之前沒有關聯性,一個站點的許多頁面過度使用同一個關鍵詞,從而為了提高排名。但是事實上,這種行為對於排名是幫助不大的。
#5 怎樣處理好內容重復的情況
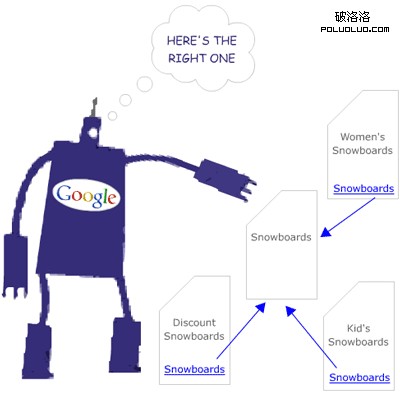
這裡不同在於不是僅僅通過“滑雪板”這個詞而是通過各種各樣,有價值而且唯一的關鍵詞(比如折扣滑雪板,小孩滑雪板等)鏈接到原來的內容上。這樣搜索引擎就可以很容易確定該頁面與其他頁面的相關性極強,這不僅僅基於搜索引擎友好性,更是考慮到用戶體驗與網站未來的信息架構。
Canonical標簽
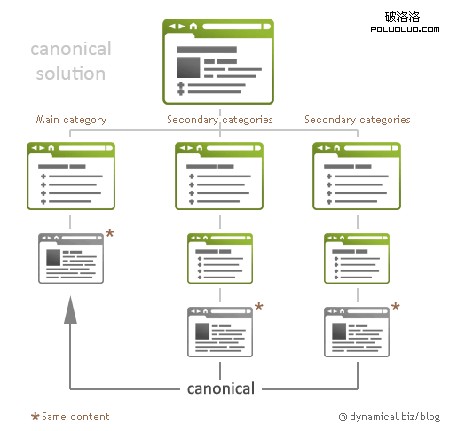
Source: Dynamical.biz
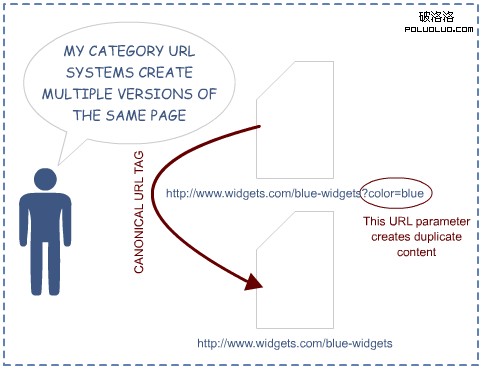
Source: SEOmoz.org
其實上面兩幅圖都涉及到一個問題,那就是網址規范化,針對這個問題,Zac前輩很早前就給我們分析過—網址規范化問題最新解決方法,大家可以前往學習。
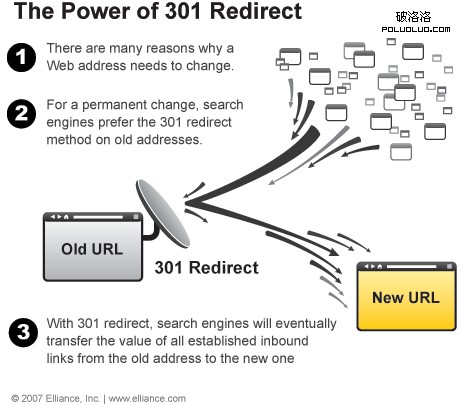
301重定向
- 上一頁:外貿SEO之關鍵詞密度
- 下一頁:新年已過將近半月 網站快照依然迷戀著09年