最近聽到很多SEO 對在頁面的規范版本用規范 URL 標簽( canonical URL tag) 時會有問題。很多人對於只有重復內容應該用 rel= “canonical” 屬性而原始內容不需要的說法存在疑惑。
看看下面圖表來幫助理解:
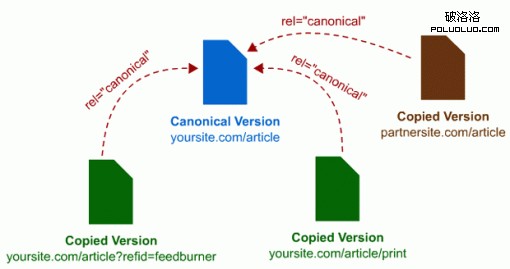
這是使用 rel=canonical 屬性的標准方式。頁面的不同版本——不管是在你自己的頁面還是合作伙伴的頁面或者發布授權內容的位置(注:這是 Google 2009年12月17日新發布的更新說明)—— 都能指回原版內容以便告訴搜索引擎哪裡可以找到最初版本。 然而,按以下方式來做也是可取的:
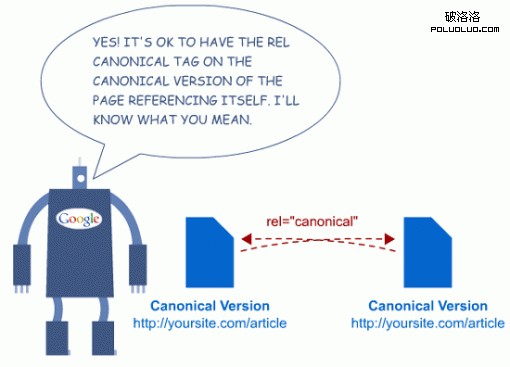
從 Google 官方發布的關於這方面內容的博客來看,關於該問題並沒給出很明確的說法。但是,我們可以看看Google給出的示例站點Wikia是怎樣做的。也能從 Google 開發者項目技術帶頭人 Maile Ohye 對該問題的評論回復看出一些端倪:
@Wade: Yes, it’s absolutely okay to have a self-referential rel=”canonical”。 It won’t harm the system and additionally, by including a self-reference you better ensure that your mirrors have a rel=”canonical” to you.
@Wade: 是的,在原始頁面有一個自參考的 rel= “canonical” 也是絕對沒問題的。不會有什麼危害,另外若是有自參考標簽的話最好要確保頁面的鏡像有 rel=”canonical” 指回該頁面。
Maile 給出了很好的建議。如果第三方參考了你發布的內容附加了數據串到URL,那麼添加一個默認的規范URL標簽會非常有用。 事實上,我們最近服務的很多公司發現將此作為最佳實踐在整站實施是很有效的,以防未來出現重復或減少再創建不包含 rel=canonical 屬性的頁面時流失鏈接果汁或者招致規范化問題的可能性。
最後,這的的確確是確保 Google 索引頁面的 “http” 而不是“https”版本的好辦法(從正確的頁面計算鏈接果汁)。對於很多 SEO 來說這都是曾經的心頭之痛,現在你知道該怎麼辦了吧。
原文地址:http://www.chinaz.com/Webbiz/Seo/01051030H2010.html?1262681969