分詞是很多做SEO的人常聽到的概念,為了讓大家在這個方面不會有疑惑,現在要來講一下分詞以及索引庫。這也是更深入的了解搜索引擎的開始。
搜索引擎每天都是在處理一個基本的需求:用戶搜索一個關鍵詞,搜索引擎馬上找到相關的網頁給用戶。這個過程要怎麼實現呢?下面就分步來了解這個過程。
首先搜索引擎要盡可能多的把互聯網上的網頁搜集下來,這樣能提供大量的網頁給用戶查詢。這一部分由爬蟲來解決,順著互聯網上的鏈接一個個往下抓取。最後就有了一堆記錄著網頁各種信息的資料庫。目前的現狀,最後能使這個資料庫裡有大概100多億個網頁。資料庫裡記錄了這些網頁的URL,整個網頁的HTML代碼,網頁標題等等信息。
然後,搜索引擎拿到用戶輸入的這個關鍵詞後,要從這個資料庫裡把相關的網頁找出來給用戶。這裡就碰到好幾個問題了:
1,要怎麼快速的從上100億個網頁裡找出匹配的網頁的呢?
要知道這是從上百億的網頁裡找符合這個關鍵詞內容的網頁,如果像用word裡那種用ctrl + F 輪詢的查找方式的話,即使用超級計算機,也不知道要消耗多少時間。但是現在的搜索引擎,在幾分之一秒裡就實現了。所以一定是做了一些處理才實現的。
解決辦法也倒簡單,就是建立一份索引庫。就像我們查《新華字典》一樣,我們不會翻遍《新華字典》的每一頁來查那個字在哪頁,而是先去索引表那裡找這個字,拿到頁碼後,直接翻到那頁就可以了。搜索引擎也會為上百億的網頁建立一個索引庫,用戶查詢信息的時候,是先到搜索引庫裡查一下要找的信息在哪些網頁,然後就引導你去那些網頁的。
如下圖:

索引庫
2,索引庫裡用什麼樣的分類方式?
我們知道,《新華字典》的索引表是用字母列表或者偏旁部首的分類方式的。那麼搜索引擎的索引庫裡是怎麼分類的?是不是也可以用字母列表的方式?
搜索引擎如果以字母列表的方式排列索引庫,那麼平均每個字母下要查詢的網頁數量是 100億÷26=3.85億 ,也還是一個很大的數字。而且搜索引擎上,今天是100億個網頁,過不了多久就是300億個網頁了。
最後,終於找到一個解決辦法:索引庫裡用詞語來分類。
因為盡管互聯網上的網頁是不斷激增的,但是每一種語言裡,詞語的數量都是相對固定的。比如英語就是一百多萬個單詞,100億 ÷ 1百萬 = 1 萬;漢語是8萬多個詞語,100億÷8萬=12萬5千。都是計算機很容易處理得過來的。
用詞語來分類還有一個好處,就是可以匹配用戶查詢的那個詞語。本來用戶就是要查這個詞語的,那我就按這個詞語去分類就是。
所以,搜索引擎的索引庫,最後就是這個樣子的:
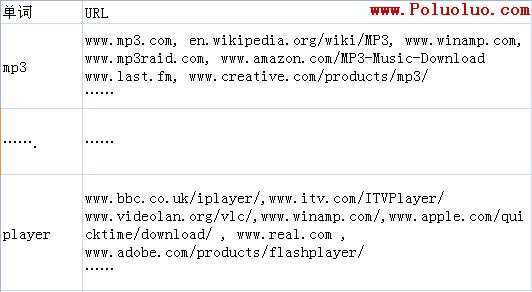
模擬的索引庫
理論上,當用戶輸入關鍵詞“mp3 player”搜索時,搜索引擎就從 “mp3”那行 和 “player”那行裡拿出同時都有的、交集的url來即可。
上圖也是現在英文版的google.com上的真實排名情況,可以看到 www.winamp.com 這個網站在搜索“mp3”的時候排第4位,在搜索“player”的時候也排第4位。當搜索“mp3 player”的時候,因為沒有其他網站比它更匹配這個詞語,所以它排在了第一位。
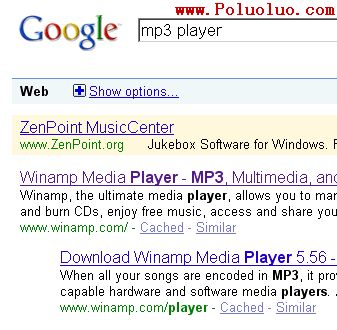
排在第一
當搜索引擎把一個網站抓取下來後,接著要做的事情就是把網頁裡的詞語分開放到索引庫裡。分詞在這個時候就要應用到了,所謂的分詞,其實很簡單,就是把詞語分開而已。
英語的分詞好處理一點,因為英語的每個單詞之間是用空格分開的,基本上就只要處理一些虛詞、介詞,還有一些詞語的單復數,變形詞等等。但是中文的分詞就復雜很多了,句子中的每個字都連在一起,有時候即使是人來判斷,都還有產生歧義的時候。中文的分詞有很多方法,也很容易弄懂的,如正向切分法,逆向切分法等等,網上有很多相關的資料。
谷歌的中文分詞方法是從國外一家第三方公司買的。百度的分詞方法是自己創立的,可能在詞庫上面比谷歌有點優勢。不過其他方面差了一些。
當爬蟲找到一個網頁的時候,在搜索引擎看來,這個網頁就是一大堆詞語的組合。基本流程如下:

搜索引擎的處理過程
看完這個流程圖,應該能給大家在做內部優化的時候有所啟發的。
我建議大家再去看一下《把Web標准化進行得更徹底一點》這篇文章,還有《豐富網頁摘要”,讓你的網站與眾不同》以及《SEO案例:錨文本、關鍵字、nofollow、Web標准化(一)》和 《SEO案例:錨文本、關鍵字、nofollow、Web標准化(二)》。那些文章和這篇文章一樣,都是在講同一個問題。
一定要站在搜索引擎的角度,把它的這些原理了解清楚了,才會讓你明白哪些因素才是你應該關注的重點。
有人說: SEO就是重在細節。這應該是經驗之談。但是不知道大家有沒有想過的是:是不是可能原本這些看似細節的東西,其實就是應該注意的重要的東西呢?如果你不能控制好你的排名,有沒有想過可能你以前特別在意的一些SEO因素,其實