最近發現一些關鍵字在谷歌的搜索結果中排名非常靠前,可是本博客的Pagerank=0,有時連0都沒有。可是Google為什麼會注意到這點呢?比如:當你搜索”Google ufo 麥田圈”時,易IT博客的文章 Google放出第二個UFO Logo(麥田圈Doodle) - 易IT博客就排名第一。具體見下圖:
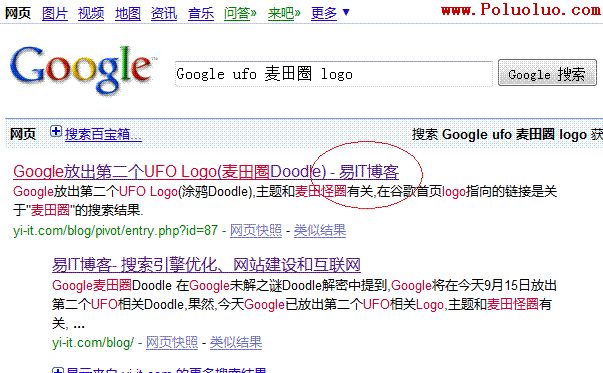
前幾天,Search Engline Journalde Ann Smarty也發現了這個問題,她的文章裡講到那些排名靠前的小站點或新站點的網頁甚至連優化都做的不好。在Webmasterworld的貼子解釋到,這是一種“混合(blended)”的搜索方式。排名最靠前的搜索結果是混合不同搜索結果的“集簇(集合,clusters)”後給出的,目的是為了給用戶更多的選擇。
這種混合可能包括以下幾種形式:
強制較新鮮的搜索結果排名靠前
綜合導航類的網頁、信息類和事務類的網頁
綜合對同一個關鍵詞有不同解釋的網頁
綜合各種類型搜索的結果,比如本地搜索,產品搜索,圖片搜索和新聞搜索等
。。。Google有時強制從有不同意思和意義的網頁集合中拿來某些網頁放到搜索結果的第一頁,即使有時這些網頁的排名不是很高。。。
一點補充,幾年前有段時間Google在改進技術強制把某些搜索結果放在固定的位置
以上的理論是基於Google的專利“在搜索短語的搜索結果中自動產生分類(Automatic taxonomy generation in search results using phrases)”,這個專利描述了下面的算法:
搜索結果可以混合不同集簇的代表性結果
一個用來查詢的短語可能會與幾個網頁的集簇相關聯。每個集簇是一組可能包含其他不同短語作為關鍵字的網頁,是作為當前查詢短語結果的補充。這假設創建集簇的短語是由一組提供被專利稱為“信息增益(information gain)”的單詞的組合。
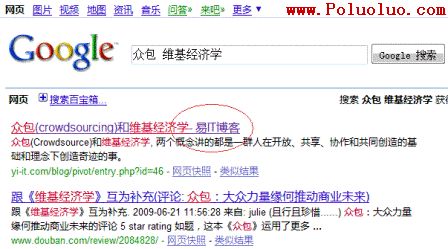
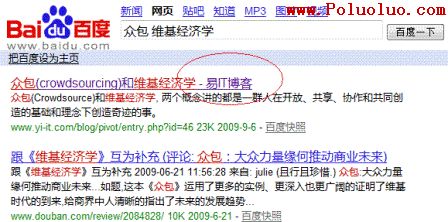
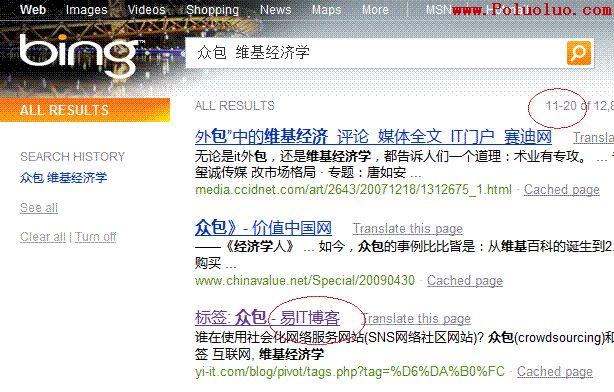
再來一個例子,當你在谷歌、百度和必應中搜索“眾包 維基經濟學”時,你會得到下面的結果:
谷歌搜索結果:
百度搜索結果:
必應搜索結果(注:必應還沒收錄上面的那篇文章,反而收錄了眾包的標簽頁):
看來每個搜索引擎都有這樣一種機制,只是收錄的速度、更新的快慢和具體的算法不同。
另外一個現象就是,我猜想Google多數時候會根據搜索結果生成的時間來判斷哪個是最初的源,而最早產生的重復內容會排名靠前。而百度則可能會把網站的排名作為主要考慮的因素。比如,相同一篇博客,原創的一般會在google的搜索結果中靠前,而在百度,排名高網站轉載的可能會靠前。當然,這只是個人經驗,並不是絕對的,因為有時在google搜索重復內容時也是大站的結果靠前。
原文:http://yi-it.com/blog/pivot/entry.php?id=92