什麼是網絡爬蟲呢?其實啊,很簡單,網絡爬蟲就是搜索引擎訪問你的網站進而收錄你的網站的一種內容采集工具。例如:百度的網絡爬蟲就叫做BaiduSpider。
俗話說:知己知彼,百戰百勝。
接下來想必你會問網絡爬蟲的工作原理是什麼呢?下面我給大家看一張圖:
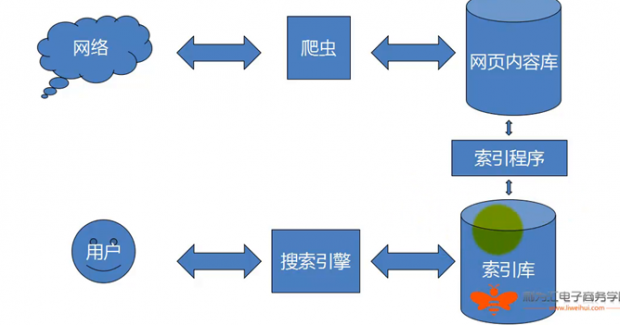
這張圖就能很充分的說明搜索引擎的Spider的工作原理:
Spider通過互聯網上所有的錨文本和鏈接進入你的網站采集你網站的網頁面裡的內容,把這些采集到的內容存放到網頁內容庫裡面,然後百度通過整理索引內容程序制作一個索引庫,讓用戶通過搜索引擎可以很快的找到它想要的東西。這就是搜索引擎網絡爬蟲的工作原理。
知道了網絡爬蟲的原理,如何做好SEO呢?只要記住一點,搜索引擎永遠最偏愛稀缺的優質的內容,所以要保持網站內容的更新頻率和質量就能得到Spider的好感,那麼之後你的網站就會和Spider墜入愛河了。那麼怎麼才能知道你的另一半Spider有沒有來過你的網站呢?很簡單,你可以通過查看你的空間上的logs文件,下面一張圖告訴你怎麼查看日志:

為什麼文章被收錄,搜索量沒有發生變化呢?
這就要從你自己身上找原因了,因為被蜘蛛抓取的內容在搜索引擎索引庫裡面是重復的,這篇文章就被認為是一點卵用也沒有了。
另外你可能也會遇到另外一種情況,那就是你在新浪博客和你的網站都發表了同一篇文章,但是你的文章在新浪博客上被收錄了,自己的網站上卻沒有被收錄,這種原因其實很簡單,就是因為新浪博客的名氣大,權重高,所以排名會比你的網站高,當然這種狀況是可以改變的,那就是好好做你的網站,把網站的內容做的很專一,那麼Spider就會更加偏愛你了。
轉載請注明商丘郭勇SEO技術分享學習博客(http://seo.teenjs.com/)分享從菜鳥到大神的SEO知識教程