圖解:搜索引擎工作的基本原理
編輯:SEO技巧
要做SEO搜索引擎優化,當然必須先了解搜索引擎的工作原理,不需要完全掌握,但是概念性的東西一定要印在大腦裡。至於不同的搜索引擎,其實大同小異,比如:百度、google都是差不多的,也不用分的太細。要做SEO搜索引擎優化,當然必須先了解搜索引擎的工作原理,不需要完全掌握,但是概念性的東西一定要印在大腦裡。至於不同的搜索引擎,其實大同小異,比如:百度、google都是差不多的,也不用分的太細。 搜索引擎的組成 搜索引擎大致一共分為4個部分,分別是
搜索引擎的組成
搜索引擎大致一共分為4個部分,分別是:引擎蜘蛛爬蟲、數據分析系統、數據索引系統、查詢系統。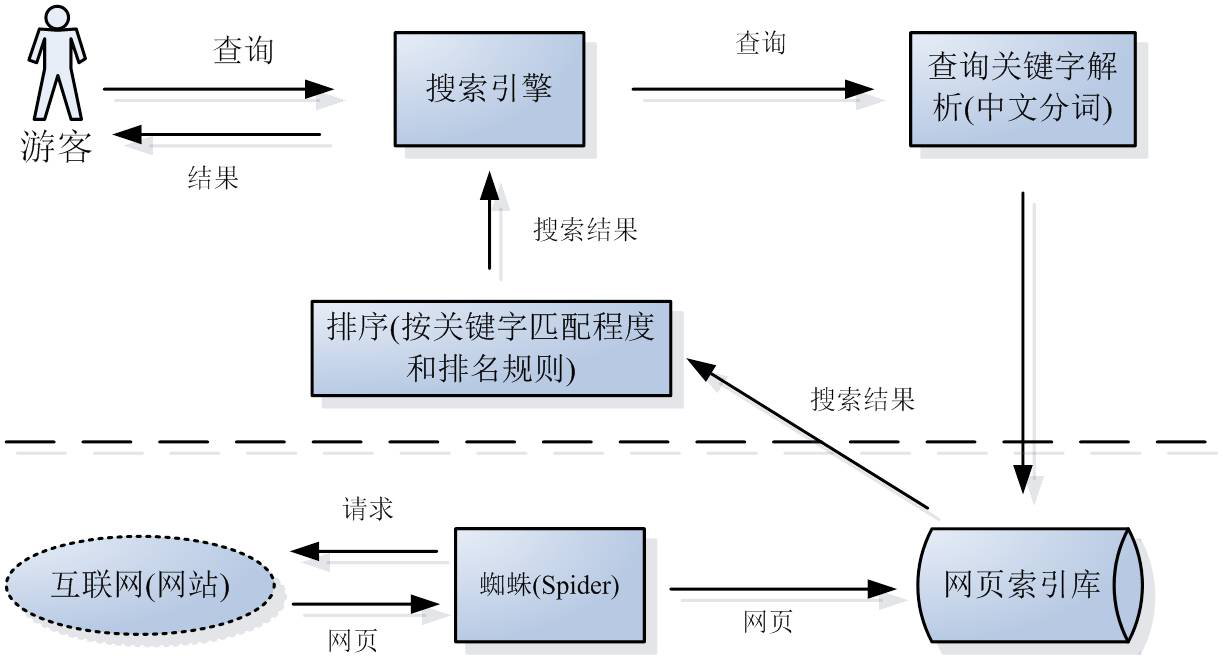
搜索引擎簡單的工作原理概況
搜索引擎蜘蛛發現連接 → 根據蜘蛛的抓取策略抓取網頁 → 然後交到分析系統的手中 → 分析網頁 → 建立索引庫什麼是搜索引擎蜘蛛?
搜索引擎蜘蛛程序,其實就是搜索引擎的一個自動應用程序,它的作用是什麼呢?其實很簡單,就是在互聯網中浏覽信息,然後把這些信息都抓取到搜索引擎的服務器上,然後建立索引庫等等,我們可以把搜索引擎蜘蛛當做一個用戶,然後這個用戶來訪問我們的網站,然後在把我們網站的內容保存到自己的電腦上!比較好理解。搜索引擎蜘蛛是怎樣抓取網頁的呢?
發現某一個鏈接 → 下載這一個網頁 → 加入到臨時庫 → 提取網頁中的鏈接 → 在下載網頁 → 循環 首先搜索引擎的蜘蛛需要去發現鏈接,至於怎麼發現就簡單了,就是通過鏈接鏈接鏈接。搜索引擎蜘蛛在發現了這個鏈接後會把這個網頁下載下來並且存入到臨時的庫中,當然在同時,會提取這個頁面所有的鏈接,然後就是循環。 搜索引擎蜘蛛幾乎是24小時不休息的(在此為它感到悲劇,沒有假期。哈哈。)那麼蜘蛛下載回來的網頁怎麼辦呢?這就需要到了第二個系統,也就是搜索引擎的分析系統。搜索引擎的蜘蛛抓取網頁有規律嗎?
答案是有!如果蜘蛛胡亂的去抓取網頁,那麼就費死勁了,互聯網上的網頁,每天都增加那麼那麼那麼多,蜘蛛怎麼可以抓取的過來呢?所以說,蜘蛛抓取網頁也是有規律的!蜘蛛抓取網頁策略
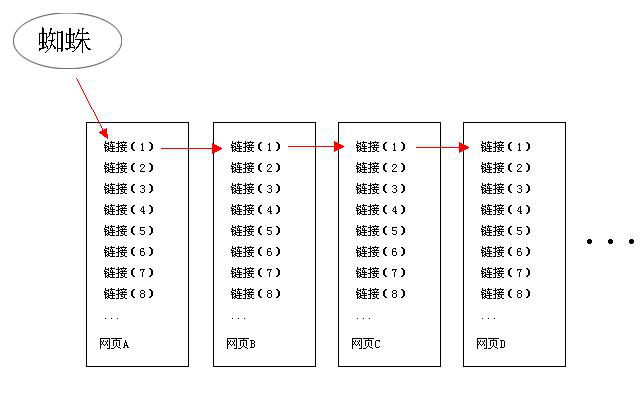 1、深度優先
什麼是深度優先?簡單的說,就是搜索引擎蜘蛛在一個頁面發現一個連接然後順著這個連接爬下去,然後在下一個頁面又發現一個連接,然後就又爬下去並且全部抓取,這就是深度優先抓取策略。大家看下圖
2、深度優先
1、深度優先
什麼是深度優先?簡單的說,就是搜索引擎蜘蛛在一個頁面發現一個連接然後順著這個連接爬下去,然後在下一個頁面又發現一個連接,然後就又爬下去並且全部抓取,這就是深度優先抓取策略。大家看下圖
2、深度優先在上圖中就是深度優先的示意圖,我們假如網頁A在搜索引擎中的權威度是最高的,假如D網頁的權威是最低的,如果說搜索引擎蜘蛛按照深度優先的策略來抓取網頁,那麼就會反過來了,就是D網頁的權威度變為最高,這就是深度優先! 3、寬度優先 寬度優先比較好理解,就是搜索引擎蜘蛛先把整個頁面的鏈接全部抓取一次,然後在抓取下一個頁面的全部鏈接。 寬度優先上圖呢,就是寬度優先的示意圖!這其實也就是大家平時所說的扁平化結構,大家或許在某個神秘的角落看到一篇文章,告誡大家,網頁的層度不能太多,如果太多會導致收錄很難,這就是來對付搜索引擎蜘蛛的寬度優先策略,其實就是這個原因。 4、權重優先 如果說寬度優先比深度優先好,其實也不是絕對的,只能說是各有各的好處,現在搜索引擎蜘蛛一般都是兩種抓取策略一起用,也就是深度優先+寬度優先,並且在使用這兩種策略抓取的時候,要參照這條連接的權重,如果說這條連接的權重還不錯,那麼就采用深度優先,如果說這條連接的權重很低,那麼就采用寬度優先! 那麼搜索引擎蜘蛛怎樣知道這條連接的權重呢?這裡有2個因素:1、層次的多與少;2、這個連接的外鏈多少與質量; 那麼如果層級太多的鏈接是不是就不會被抓取呢?這也不是絕對的,這裡邊要考慮許多因素,我們在後邊的進階中會降到邏輯策略,到時候我在詳細的給大家說!
重要的抓取規則:重訪抓取
我想這個比較好理解,就是比如昨天搜索引擎的蜘蛛來抓取了我們的網頁,而今天我們在這個網頁又加了新的內容,那麼搜索引擎蜘蛛今天就又來抓取新的內容,這就是重訪抓取!重訪抓取也分為兩個,如下: 1、全部重訪 所謂全部重訪指的是蜘蛛上次抓取的鏈接,然後在這一個月的某一天,全部重新去訪問抓取一次! 2、單個重訪 單個重訪一般都是針對某個頁面更新的頻率比較快比較穩定的頁面,如果說我們有一個頁面,1個月也不更新一次。 那麼搜索引擎蜘蛛第一天來了你是這個樣子,第二天,還是這個樣子,那麼第三天搜索引擎蜘蛛就不會來了,會隔一段時間在來一次,比如隔1個月在來一次,或者等全部重訪的時候在更新一次。 以上呢,就是搜索引擎蜘蛛抓取網頁的一些策略!那麼我們上邊說過,在搜索引擎蜘蛛把網頁抓取回來,就開始了第二個部分,也就是數據分析的這個部分。數據分析系統
數據分析系統,是處理搜索引擎蜘蛛抓取回來的網頁,那麼數據分析這一塊又分為了一下幾個: 1、網頁結構化 簡單的說,就是把那些html代碼全部刪掉,提取出內容。 2、消噪 消噪是什麼意思呢?在網頁結構化中,已經刪掉了html代碼,剩下了文字,那麼消噪指的就是留下網頁的主題內容,刪掉沒用的內容,比如版權! 3、查重 查重比較好理解,就是搜索引擎查找重復的網頁與內容,如果找到重復的頁面,就刪除。 4、分詞 分詞是神馬東西呢?就是搜索引擎蜘蛛在進行了前面的步驟,然後提取出正文的內容,然後把我們的內容分成N個詞語,然後排列出來,存入索引庫!同時也會計算這一個詞在這個頁面出現了多少次。 5、鏈接分析 這一個步驟就是我們平時所做的做煩躁的工作,搜索引擎會查詢,這個頁面的反向鏈接有多少,導出鏈接有多少以及內鏈,然後給這個頁面多少的權重等。數據索引系統
在進行了上邊的步驟之後,搜索引擎就會把這些處理好的信息放到搜索引擎的索引庫中。那麼這個索引庫又大致分為以下兩個系統:
正排索引系統 什麼是正排索引?簡單的說,就是搜索引擎把所有URL都加上一個編號,然後這個編號對應的就是這個URL的內容,包括這個URL的外鏈,關鍵詞密度等等數據。 到排索引系統 倒排索引源於實際應用中需要根據屬性的值來查找記錄。這種索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的地址。由於不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱為倒排索引(inverted index)。
小編推薦
熱門推薦