基於網絡爬蟲工作原理,該如何優化SEO?
編輯:關於SEO
公司程序猿在開發產品的過程中,不斷擴展自己的知識體系。並為非技術部的同事普及爬蟲原理。小愛學習完之後發現對SEO優化還是有幫助的唷!
1.1 爬蟲定義
爬蟲是一個抓取網頁的計算機程序,它在互聯網中漫游,發現和搜集信息。日夜不停地運行,盡可能多、盡可能快地搜集各種類型的新信息,同時因為互聯網上的信息更新很快,所以還要定期更新已經搜集過的舊信息,以避免死連接和無效連接。 1.2 第一個爬蟲 RBSE (Eichmann,1994)是第一個發布的爬蟲。它有兩個基礎程序。第一個是“spider”,抓取隊列中的內容到一個關系數據庫中,第二個程序是“mite”,是一個修改後的www的ASCII浏覽器,負責從網絡上下載頁面。 1.3 日常生活接觸 Baiduspider, Googlebot。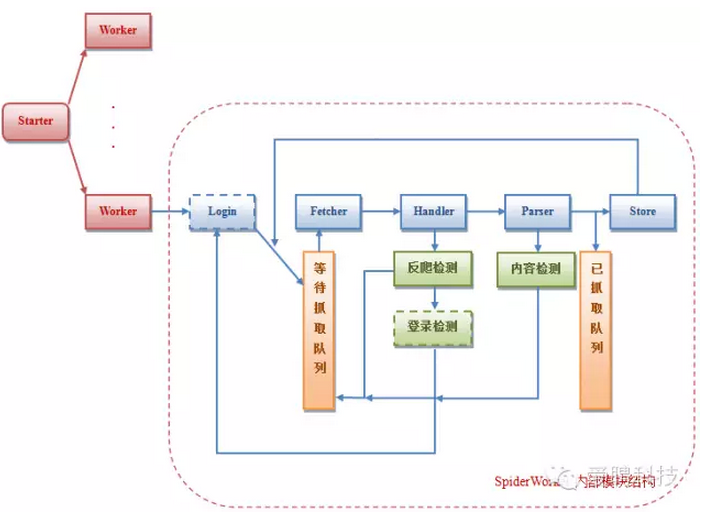 1.2 爬蟲組成
網絡爬蟲主要由控制器,解析器,資源庫組成。
中央控制器:根據系統傳過來的URL鏈接,分配一線程,啟動線程調用爬蟲爬取網頁。
解析器:是爬蟲的主要部分,負責下載網頁,對網頁的文本進行處理,如過濾功能,抽取特殊HTML標簽的功能,分析數據功能。
資源庫:主要是用來存儲網頁中下載下來的數據記錄的容器,並提供生成索引的目標源。中大型的數據庫產品有:Oracle、Sql Server等。
1.3 爬蟲類型
一般分傳統爬蟲和聚集爬蟲。
(1)傳統爬蟲,從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,抓取之後,通過源碼解析來獲得想要的內容。
(2)聚焦爬蟲:根據一定的網頁分析算法過濾與主題無關的鏈接,重復上述過程,直到達到系統的某一條件時停止所有被爬蟲抓取的網頁將會被系統存貯。
1.2 爬蟲組成
網絡爬蟲主要由控制器,解析器,資源庫組成。
中央控制器:根據系統傳過來的URL鏈接,分配一線程,啟動線程調用爬蟲爬取網頁。
解析器:是爬蟲的主要部分,負責下載網頁,對網頁的文本進行處理,如過濾功能,抽取特殊HTML標簽的功能,分析數據功能。
資源庫:主要是用來存儲網頁中下載下來的數據記錄的容器,並提供生成索引的目標源。中大型的數據庫產品有:Oracle、Sql Server等。
1.3 爬蟲類型
一般分傳統爬蟲和聚集爬蟲。
(1)傳統爬蟲,從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,抓取之後,通過源碼解析來獲得想要的內容。
(2)聚焦爬蟲:根據一定的網頁分析算法過濾與主題無關的鏈接,重復上述過程,直到達到系統的某一條件時停止所有被爬蟲抓取的網頁將會被系統存貯。
2.抓取對象
抓取對象:靜態網頁、文件對象、動態網頁、特殊內容。 特殊內容:比如RSS、XML數據,情況特殊需特殊處理。如新聞的滾動新聞頁面,需要爬蟲不停地監控掃描,發現新內容馬上就進行抓取。3.爬蟲成本
使用爬蟲的代價包括: (1)網絡資源:在很長一段時間,爬蟲使用相當的帶寬高度並行地工作。 (2)服務器超載:尤其是對給定服務器的訪問過高時。 (3)邏輯糟糕的爬蟲,可能導致服務器或者路由器癱瘓,或者會嘗試下載自己無法處理的頁面。 個人爬蟲,如果過多的人使用,可能導致網絡或者服務器阻塞。4. 爬蟲質量
新鮮度和過時性 爬蟲的目標是盡可能高的提高頁面的新鮮度 同時降低頁面的過時性5. 爬蟲策略及優化
 5.1 一般抓取方法:
(1)從一個起始URL集合開始,以一定的規則循環在互聯網中發現信息。這些起始URL可以是任意的URL,但常常是一些非常流行、包含很多鏈接的站點(如Yahoo!)
(2)劃分:將Web空間按照域名、IP地址或國家域名劃分,每個搜索器負責一個子空間的窮盡搜索。
5.2 抓取策略
網頁的抓取策略可以分為深度優先、廣度優先和最佳優先三種。
深度優先在很多情況下會導致爬蟲的陷入(trapped)問題。
目前常見的是廣度優先和最佳優先方法。
5.3 策略選擇
(1)選擇策略,決定所要下載的頁面;
①重新訪問策略,決定什麼時候檢查頁面的更新變化;
② 平衡禮貌策略,指出怎樣避免站點超載;
②並行策略,指出怎麼協同達到分布式抓取的效果;
(2)提示:為了獲取更好的抓取策略,更多有關網頁質量的信息應該考慮進去。
5.4 注意事項
爬蟲開發的主要問題是性能和反封鎖。
很多時候,采用高並發高頻率抓取數據是可行的,前提是目標站點沒有采用任何反爬措施(訪問頻率限制、防火牆、驗證碼……)。
更多時候,有價值的信息,一定伴隨著嚴格的反爬措施,一旦ip被封,什麼組件都沒戲了。
5.1 一般抓取方法:
(1)從一個起始URL集合開始,以一定的規則循環在互聯網中發現信息。這些起始URL可以是任意的URL,但常常是一些非常流行、包含很多鏈接的站點(如Yahoo!)
(2)劃分:將Web空間按照域名、IP地址或國家域名劃分,每個搜索器負責一個子空間的窮盡搜索。
5.2 抓取策略
網頁的抓取策略可以分為深度優先、廣度優先和最佳優先三種。
深度優先在很多情況下會導致爬蟲的陷入(trapped)問題。
目前常見的是廣度優先和最佳優先方法。
5.3 策略選擇
(1)選擇策略,決定所要下載的頁面;
①重新訪問策略,決定什麼時候檢查頁面的更新變化;
② 平衡禮貌策略,指出怎樣避免站點超載;
②並行策略,指出怎麼協同達到分布式抓取的效果;
(2)提示:為了獲取更好的抓取策略,更多有關網頁質量的信息應該考慮進去。
5.4 注意事項
爬蟲開發的主要問題是性能和反封鎖。
很多時候,采用高並發高頻率抓取數據是可行的,前提是目標站點沒有采用任何反爬措施(訪問頻率限制、防火牆、驗證碼……)。
更多時候,有價值的信息,一定伴隨著嚴格的反爬措施,一旦ip被封,什麼組件都沒戲了。
6. 爬蟲協議(狀態碼)

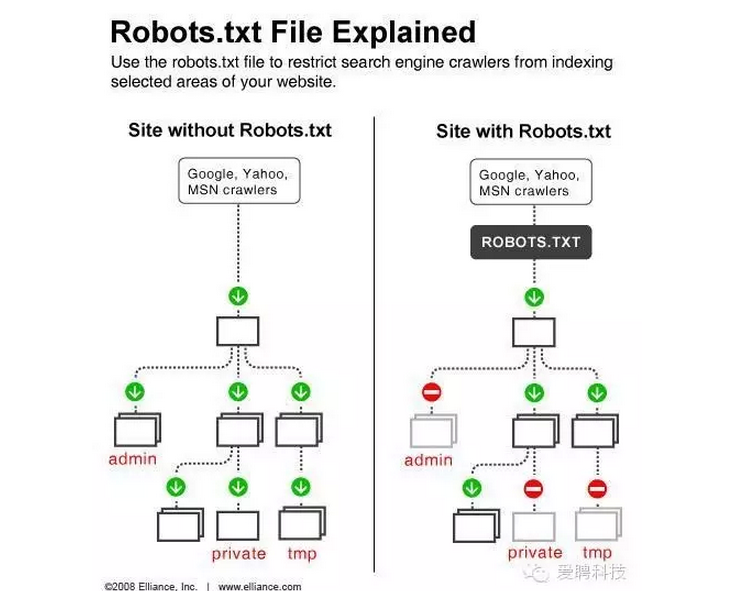 Robots協議
Robots協議(也稱為爬蟲協議、機器人協議等),
全稱是“網絡爬蟲排除標准”(Robots Exclusion Protocol),
網站通過Robots協議告訴搜索引擎哪些頁面可以抓取,
哪些頁面不能抓取。
.htaccess文件是Apache服務器中的一個配置文件,它負責相關目錄下的網頁配置。
通過htaccess文件,可以幫我們實現:網頁301重定向、自定義404錯誤頁面、改變文件擴展名、允許/阻止特定的用戶或者目錄的訪問、禁止目錄列表、配置默認文檔等功能。
HTTP狀態碼通常分為5種類型,分別以1~5五個數字開頭,由3位整數組成:
------------------------------------------------------------------------------------------------
200:請求成功 處理方式:獲得響應的內容,進行處理
201:請求完成,結果是創建了新資源。新創建資源的URI可在響應的實體中得到 處理方式:爬蟲中不會遇到
202:請求被接受,但處理尚未完成 處理方式:阻塞等待
204:服務器端已經實現了請求,但是沒有返回新的信 息。如果客戶是用戶代理,則無須為此更新自身的文檔視圖。 處理方式:丟棄
300:該狀態碼不被HTTP/1.0的應用程序直接使用, 只是作為3XX類型回應的默認解釋。存在多個可用的被請求資源。 處理方式:若程序中能夠處理,則進行進一步處理,如果程序中不能處理,則丟棄301:請求到的資源都會分配一個永久的URL,這樣就可以在將來通過該URL來訪問此資源 處理方式:重定向到分配的URL302:請求到的資源在一個不同的URL處臨時保存 處理方式:重定向到臨時的URL
304 請求的資源未更新 處理方式:丟棄
400 非法請求 處理方式:丟棄
401 未授權 處理方式:丟棄
403 禁止 處理方式:丟棄
404 沒有找到 處理方式:丟棄
5XX 回應代碼以“5”開頭的狀態碼表示服務器端發現自己出現錯誤,不能繼續執行請求 處理方式:丟棄
Robots協議
Robots協議(也稱為爬蟲協議、機器人協議等),
全稱是“網絡爬蟲排除標准”(Robots Exclusion Protocol),
網站通過Robots協議告訴搜索引擎哪些頁面可以抓取,
哪些頁面不能抓取。
.htaccess文件是Apache服務器中的一個配置文件,它負責相關目錄下的網頁配置。
通過htaccess文件,可以幫我們實現:網頁301重定向、自定義404錯誤頁面、改變文件擴展名、允許/阻止特定的用戶或者目錄的訪問、禁止目錄列表、配置默認文檔等功能。
HTTP狀態碼通常分為5種類型,分別以1~5五個數字開頭,由3位整數組成:
------------------------------------------------------------------------------------------------
200:請求成功 處理方式:獲得響應的內容,進行處理
201:請求完成,結果是創建了新資源。新創建資源的URI可在響應的實體中得到 處理方式:爬蟲中不會遇到
202:請求被接受,但處理尚未完成 處理方式:阻塞等待
204:服務器端已經實現了請求,但是沒有返回新的信 息。如果客戶是用戶代理,則無須為此更新自身的文檔視圖。 處理方式:丟棄
300:該狀態碼不被HTTP/1.0的應用程序直接使用, 只是作為3XX類型回應的默認解釋。存在多個可用的被請求資源。 處理方式:若程序中能夠處理,則進行進一步處理,如果程序中不能處理,則丟棄301:請求到的資源都會分配一個永久的URL,這樣就可以在將來通過該URL來訪問此資源 處理方式:重定向到分配的URL302:請求到的資源在一個不同的URL處臨時保存 處理方式:重定向到臨時的URL
304 請求的資源未更新 處理方式:丟棄
400 非法請求 處理方式:丟棄
401 未授權 處理方式:丟棄
403 禁止 處理方式:丟棄
404 沒有找到 處理方式:丟棄
5XX 回應代碼以“5”開頭的狀態碼表示服務器端發現自己出現錯誤,不能繼續執行請求 處理方式:丟棄
7. 項目使用
技術社區中流行的爬蟲技術相當多,很多人喜歡基於Python的,也有人喜歡用C#,很多人由於系統集成開發和跨平台的需要傾向於java。 開源爬蟲 Web Crawler是一個為.net准備的開放源代碼的網絡檢索器(C#編寫)。 (1)Ruya是一個在廣度優先方面表現優秀,基於等級抓取的開放源代碼的網絡爬蟲。在英語和日語頁面的抓取表現良好,它在GPL許可下發行,並且完全使用Python編寫。按照robots.txt有一個延時的單網域延時爬蟲。 (2)Universal Information Crawler快速發展的網絡爬蟲,用於檢索存儲和分析數據; Dine是一個多線程的java的http客戶端。它可以在LGPL許可下進行二次開發。 2003年百度占領搜索引擎市場。 2003年熱血傳奇上線。 2003年淘寶網上線。 2004-2005年淘寶網占領電商市場。 2004-2005年搜索引擎廣告進入快速增長期。 目前,爬蟲的需求呈爆炸式增長的趨勢。 定制開發的服務http://item.taobao.com/item.htm?spm=a230r.1.14.4.10ZOWj&id=42659198536&ns=1&abbucket=6#detail 搜索引擎中的爬蟲實現常用分布式、並行計算技術,以提高信息發現和更新的速度。商業搜索引擎的信息發現可以達到每天幾百萬網頁。 采用分布式體系結構提高系統規模和性能 爬蟲可以采用集中式體系結構和分布式體系結構,兩種方法各有千秋。但當系統規模到達一定程度(如網頁數達到億級)時,必然要采用某種分布式方法,以提高系統性能。 以Google為例,它在全球建立了幾十個數據中心,每個數據中心運行上萬台服務器,目前它在全球有幾十萬台服務器,因此它的服務能夠減少地震、火災等自然災害的影響。2006年底,中國因為海底光纖損壞,眾多互聯網服務都受到影響,而Google在中國的服務,沒受到影響,就是因為其遍布全球的數據中心和災難應急處理對策。
小編推薦
熱門推薦