robots文件存在於網站根目錄,是用來告訴百度蜘蛛那些應該抓取,那些不應該抓取。正確使用robots文件有助於做好seo優 化,robots文件的核心詞匯就是allow和disallow用法。百度官網是認可這個文件的,在百度站長平台上也有robots這個欄目,點擊進 入,就可以看到你網站robots文件是否編寫正確了。
百度robots文件使用說:
1、robots.txt可以告訴百度您網站的哪些頁面可以被抓取,哪些頁面不可以被抓取。
2、您可以通過Robots工具來創建、校驗、更新您的robots.txt文件,或查看您網站robots.txt文件在百度生效的情況。
3、Robots工具暫不支持https站點。
4、Robots工具目前支持48k的文件內容檢測,請保證您的robots.txt文件不要過大,目錄最長不超過250個字符。
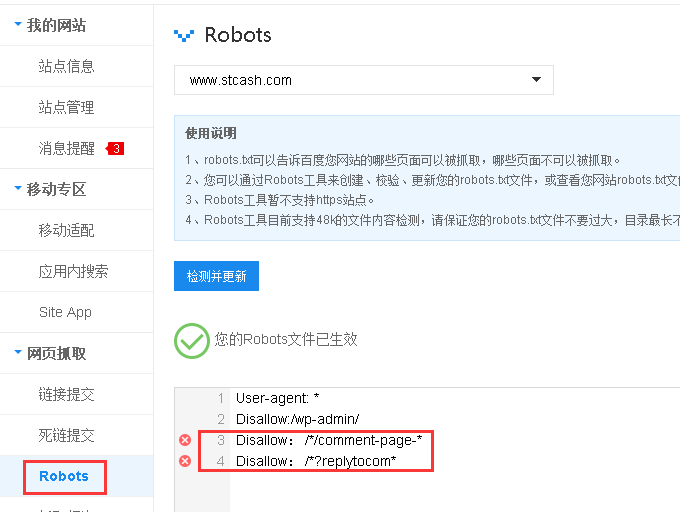
上圖我給的一個例子中,disallow語句有問題,原因是把英文的冒號寫成了中文的冒號。
當然直接輸入網站根目錄加上robtots.txt文件也可以
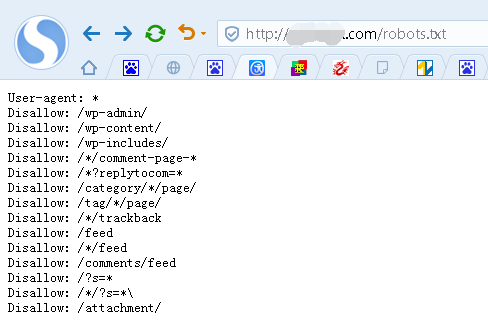
User-agent:* 是用來置頂那些搜索引擎蜘蛛可以抓取的,一般默認設置
Disallow:/category/*/page/ 分類目錄下面翻頁後的鏈接,比如,進入校賺網分類目錄 "推廣運營經驗"目錄後,在翻頁一次,就成了 stcash.com/category/tuiguangyunying/page/2形式了
Disallow:/?s=* Disallow:/*/?s=* 搜索結果頁面和分類目錄搜索結果頁面,這裡沒必要再次抓取。
Disallow:/wp-admin/ Disallow:/wp-content/ Disallow:/wp-includes/ 這三個目錄是系統目錄,一般都是屏蔽蜘蛛抓取
Disallow:/*/trackback trackback的鏈接
Disallow:/feed Disallow:/*/feed Disallow:/comments/feed 訂閱鏈接
Disallow:/?p=* 文章短鏈接,會自動301跳轉到長連接
例如,朱海濤博客之前就被收錄過短連接
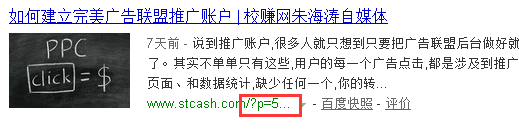
Disallow:/*/comment-page-* Disallow:/*?replytocom* 這兩個我在之前文章有過說明,來自於評論鏈接,很容易造成重復收錄。
在robots.txt文件的最後還可以制定sitemap文件 Sitemap:http://***.com/sitemap.txt
sitemap地址指令,主流是txt和xml格式。在這裡分享一段張戈所寫txt格式的simemap文件。
0) { foreach($mypages as $page) { echo get_page_link($page->ID); echo "n"; } } ?>
0){ foreach ($terms as $term) { echo get_term_link($term, $term->slug); echo "n"; } } ?>
$tag ) { $link = get_term_link( intval($tag->term_id), "post_tag" ); if ( is_wp_error( $link ) ) { return false; $tags[ $key ]->link = $link; } echo $link; echo "n"; } ?>
將上述代碼保存到txt文件,上傳到根目錄,並且在robots.txt文件中指定即可
這裡給大家共享下我的robots.txt文件
User-agent: *
Disallow:/wp-admin/
Disallow: /*/comment-page-*
Disallow: /*?replytocom*
Disallow: /wp-content/
Disallow: /wp-includes/
Disallow: /category/*/page/
Disallow: /*/trackback
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
Disallow: /?s=*
Disallow: /*/?s=*
Disallow: /attachment/
Disallow: /tag/*/page/
Sitemap: http://www.stcash.com/sitemap.xml
- 上一頁:SEO老兵親述:用戶為何不喜歡我的網站呢?
- 下一頁:SEO需要具備哪些素質